🫢 Feast
🐵 Feature Store란?
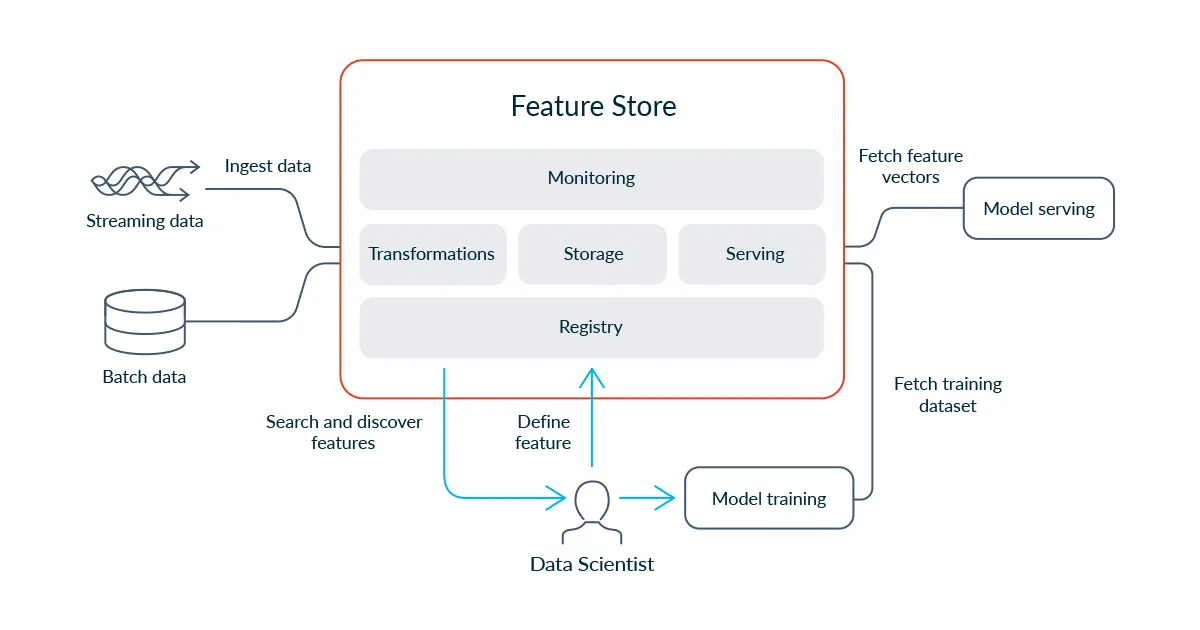
Feature Store는 운영형 머신러닝을 위한 전용 데이터 인프라입니다. 머신러닝 모델과 데이터를 연결하는 인터페이스로, 특징을 생성하고 저장하며 학습과 추론에 일관되게 제공합니다. 이를 통해 training-serving skew 문제를 방지하고, 모델 성능을 안정적으로 유지할 수 있습니다.
특징(Feature)은 모델의 입력 신호 데이터로, 예를 들어 신용카드 사기 예측에서 "해외 거래 여부"나 "평소 거래 대비 금액"이 특징이 될 수 있습니다. Feature Store의 주요 기능은 새로운 특징을 프로덕션화, 자동화된 계산과 백필, 팀 간 파이프라인 공유, 버전 및 메타데이터 관리, 프로덕션 모니터링입니다.
아키텍처는 크게 다섯 구성요소로 나뉩니다.
첫째, Serving은 학습과 추론에서 일관된 특징을 제공하며, Offline SDK와 Online API를 모두 지원합니다.
둘째, Storage는 Offline(과거 데이터 저장, S3·BigQuery 등)과 Online(실시간 추론용 최신 값, Redis·DynamoDB 등)으로 구분됩니다.
셋째, Transformation은 원시 데이터를 정기적으로 특징으로 변환하며, Batch, Streaming, On-demand 방식을 지원합니다.
넷째, Monitoring은 데이터 품질, drift, 불일치 및 운영 지표를 추적하여 시스템 안정성을 보장합니다.
다섯째, Registry는 중앙에서 특징 정의와 메타데이터를 관리하며, 탐색·협업·배포를 지원합니다.
Feature Store는 특징 코드 재사용과 자동화된 백필을 통해 학습과 추론의 일관성을 확보합니다. 팀 내·팀 간 특징을 공유하고 재사용할 수 있어 협업과 개발 속도가 향상됩니다. 또한 특징의 라이프사이클 전반(생성, 저장, 제공, 모니터링)을 통합 관리합니다. 결과적으로 Feature Store는 단순 데이터 저장소를 넘어, 운영형 ML 시스템을 효율적이고 안정적으로 구축할 수 있게 해주는 핵심 인프라입니다.
🤔 Feast란?
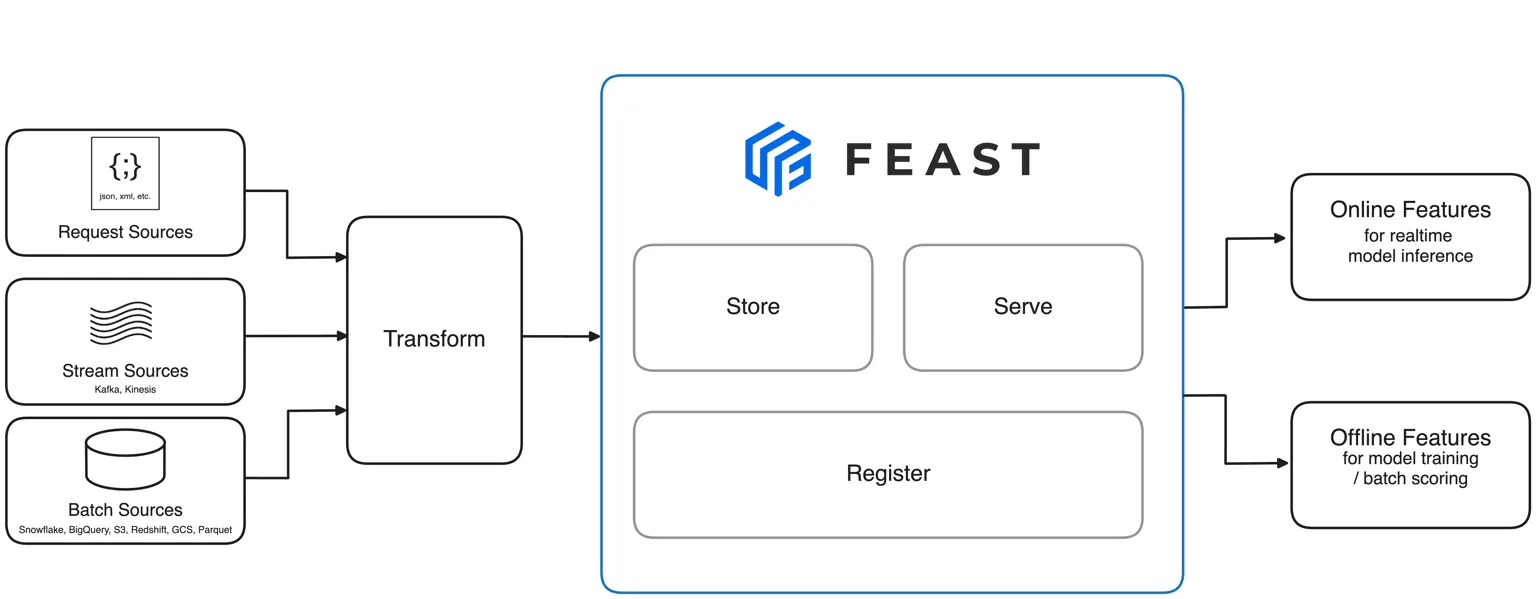
Feast(Feature Store)는 머신러닝 시스템에서 피처(Feature)를 일관되게 관리하고 제공하기 위한 오픈소스 플랫폼입니다. 이를 통해 모델 학습과 서비스 환경에서 동일한 피처를 안정적으로 사용할 수 있습니다.
구성 요소는 크게 두 가지로 나눌 수 있습니다.
- 오프라인 스토어는 과거 데이터를 기반으로 모델 학습이나 대규모 배치 예측에 활용됩니다.
- 온라인 스토어는 실시간 예측 서비스에서 빠른 응답 속도로 피처를 제공합니다.
Feast는 Python SDK, Feature Server, UI, CLI 등을 제공하여 피처 정의, 탐색, 조회, 업데이트를 지원합니다.
이를 통해 ML 플랫폼 팀은 다음과 같은 이점을 얻습니다.
- 학습과 서빙에서 동일한 피처 제공 → 일관된 데이터 활용 가능
- 데이터 누출 방지 → 시점에 맞는 피처 세트를 생성하여 미래 데이터 유출을 방지
- 데이터 인프라와 ML의 분리 → 단일 데이터 접근 계층을 제공해 모델을 다양한 환경(배치 ↔ 실시간, 한 인프라 ↔ 다른 인프라)으로 손쉽게 이동 가능
결론적으로, Feast는 머신러닝 모델 운영을 위한 표준화된 피처 관리 시스템으로, 데이터와 모델을 연결하는 핵심적인 역할을 합니다.
🔊 Feast가 있어야하는 이유
머신러닝 모델을 실제 서비스에 적용하려면 단순히 모델만 잘 만드는 것으로는 충분하지 않습니다. 모델이 필요로 하는 피처(Feature)를 안정적으로 관리하고 제공하는 체계가 반드시 필요합니다. 여기서 Feast가 중요한 역할을 합니다.
1️⃣ 일관된 피처 관리
- 모델 학습(오프라인)과 실시간 예측(온라인)에서 동일한 피처를 사용할 수 있습니다.
- 이를 통해 학습 환경과 운영 환경 간의 데이터 불일치 문제를 줄일 수 있습니다.
2️⃣ 데이터 누출 방지
- Feast는 시점(Point-in-time) 기준으로 올바른 피처 세트를 생성합니다.
- 미래 데이터가 학습 데이터에 섞여 들어가는 오류를 막아 모델의 신뢰성을 높입니다.
3️⃣역할 간 협업 강화
- 데이터 엔지니어, 머신러닝 엔지니어, MLOps 엔지니어, 데이터 사이언티스트 모두가 공통된 피처 저장소를 활용할 수 있습니다.
- 이를 통해 피처 재사용이 가능해지고, 중복 작업을 줄이며 협업 효율성을 높입니다.
4️⃣ 데이터 인프라와 ML 분리
- 다양한 데이터베이스, 데이터 웨어하우스, 실시간 시스템과 연결 가능하지만, 모델 입장에서는 단일 API/SDK를 통해 동일하게 피처에 접근할 수 있습니다.
- 환경이 변해도 모델을 쉽게 이식할 수 있습니다.
5️⃣ 운영 효율성 및 확장성
- 실시간 예측을 위한 빠른 온라인 스토어와 대규모 학습용 오프라인 스토어를 모두 지원합니다.
- 시스템 확장이 필요할 때 유연하게 대응할 수 있습니다.
⌨️ Feast 기능
1️⃣ 피처 정의 및 관리
- Python SDK를 사용해 피처, 엔티티, 데이터 소스, 변환 로직을 코드로 정의 가능
- 피처 카탈로그를 통해 중앙화된 피처 관리 제공
- 버전 관리 및 메타데이터 추적 기능 지원
2️⃣ 데이터 스토어 연동
- 오프라인 스토어(Offline Store):
- 과거 데이터를 기반으로 모델 학습 및 배치 예측에 활용
- 데이터 웨어하우스, 데이터 레이크 등과 연결 가능
- 온라인 스토어(Online Store):
- 실시간 예측을 위해 저지연 피처 조회 지원
- Redis, DynamoDB 등과 연동 가능
3️⃣ 피처 조회 및 제공
- Python SDK를 통한 피처 읽기/쓰기
- Feature Server를 통한 REST/gRPC 기반 접근 (비-Python 환경에서도 활용 가능)
- 실시간/배치 시나리오 모두 지원
- 모델 학습 시: 오프라인 피처 세트 생성
- 모델 서빙 시: 온라인 피처 제공
4️⃣ 데이터 품질 및 일관성 보장
- 시점(Point-in-time) 정합성 보장 → 데이터 누출 방지
- 학습과 서빙에서 동일한 피처 제공 → 데이터 불일치 문제 해결
5️⃣ 운영 도구 제공
- UI: 프로젝트에 정의된 피처 탐색 및 시각화
- CLI 도구: 피처 정보 조회 및 업데이트
- 다양한 인프라 환경과 유연하게 통합 가능
🧠 Feast Workflow
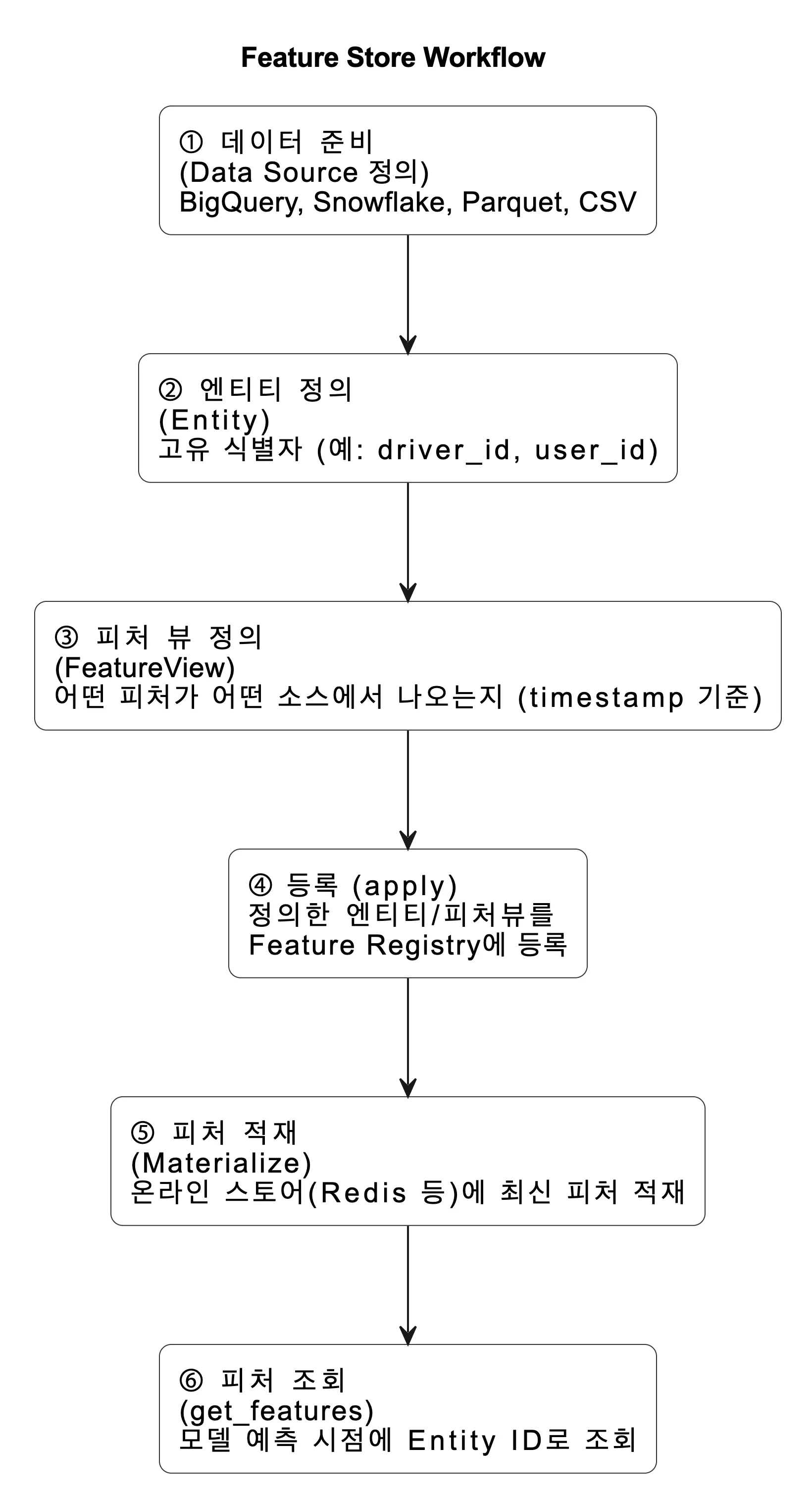
| 단계 | 이름 | 설명 |
|---|---|---|
| 1️⃣ | 데이터 준비(Data Source 정의) | 피처를 추출할 원천 데이터를 정의합니다. 예: BigQuery, Snowflake, Parquet, CSV |
| 2️⃣ | 엔티티(Entity) 정의 | 고유 식별자(primary key)를 지정합니다. 예: driver_id, user_id |
| 3️⃣ | 피처 뷰(FeatureView) 정의 | 어떤 피처들이 어떤 데이터 소스에서 나오는지를 정의합니다. (timestamp 기반으로 관리) |
| 4️⃣ | 등록(apply) | 정의한 엔티티/피처뷰를 Feature Registry에 등록합니다. |
| 5️⃣ | 피처 적재(Materialize) | 온라인 스토어(Redis 등)에 최신 피처를 로드해 실시간 서빙 가능 상태로 만듭니다. |
| 6️⃣ | 피처 조회(get_features) | 모델 예측 시점에 Entity ID를 기반으로 피처를 가져옵니다. |
