프로젝트 개요
1️⃣ 프로젝트 제목
“비트코인 및 주요 코인 1시간 단위 시세 예측 및 실시간 UI 제공 시스템”
2️⃣ 프로젝트 목표
- 목표:
- 새로 고침 시간을 기준으로 해당 날의 1시간 단위 시세를 예측
- 코인별 모델을 사용해 가격 변동 차이 고려
- 예측할 코인
- 비트코인(KRW-BTC)
- 도지코인(KRW-DOGE)
- 이더리움(KRW-ETH)
- 리플(KRW-XRP)
- 예측할 코인
- 예측 결과를 웹 UI에서 직관적으로 확인 가능
- 핵심 포인트
- 단기 예측(1시간 단위) → 단기 트레이딩
- 코인별 맞춤 모델 → 가격 단위, 변동성 차이 반영
- 자동화 → 매일 00시 학습 및 예측
3️⃣ 데이터
- 데이터 소스: 업비트
- 데이터 기간: 예측 기준 시간 이전 24시간 데이터
- 주요 컬럼
| 컬럼명 | 의미 | 비고 (추가 설명) |
|---|---|---|
market | 마켓 구분 | KRW-BTC → 원화(KRW)로 비트코인 거래 |
예: KRW-BTC, KRW-ETH 등 | ||
trade_date | 거래일자 (UTC 기준) | YYYYMMDD |
trade_time | 거래시간 (UTC 기준) | HHMMSS |
trade_date_kst | 거래일자 (KST, 한국시간) | YYYYMMDD |
trade_time_kst | 거래시간 (KST, 한국시간) | HHMMSS |
trade_timestamp | 거래 체결 시각 (UTC, ms 단위) | Unix timestamp (밀리초) |
opening_price | 당일 시가 | 하루 시작 가격 |
high_price | 당일 고가 | 하루 중 최고 거래 가격 |
low_price | 당일 저가 | 하루 중 최저 거래 가격 |
trade_price | 최근 거래 체결가 | |
| 해당 봉의 종가(Close price) | 현재/마지막 체결된 가격 | |
| 1시간 내 마지막 거래 가격 | ||
prev_closing_price | 전일 종가 | 어제 마지막 거래 가격 |
change | 전일 대비 등락 | RISE, FALL, EVEN |
change_price | 전일 대비 가격 차이 | (오늘가 - 전일 종가) |
change_rate | 전일 대비 등락률 | |
| 전 봉 대비 수익률(변동률) | 퍼센트(소수) | |
(현재 종가 / 이전 종가) - 1 | ||
signed_change_price | 부호 포함 가격 차이 | 양수(상승), 음수(하락) |
signed_change_rate | 부호 포함 등락률 | 양수(상승), 음수(하락) |
trade_volume | 최근 체결 거래량 | 해당 거래 건의 수량 (BTC 단위) |
acc_trade_price | 누적 거래대금 (당일) | 원화 기준 합계 |
acc_trade_price_24h | 24시간 누적 거래대금 | 직전 24시간 동안 원화 거래총액 |
acc_trade_volume | 누적 거래량 (당일) | BTC 기준 합계 |
| 단위: 해당 코인 기준, 예: BTC면 BTC 수량 | ||
acc_trade_volume_24h | 24시간 누적 거래량 | 직전 24시간 동안 BTC 거래총액 |
highest_52_week_price | 52주 최고가 | 최근 1년간 최고 가격 |
highest_52_week_date | 52주 최고가 기록일 | 날짜(YYYY-MM-DD) |
lowest_52_week_price | 52주 최저가 | 최근 1년간 최저 가격 |
lowest_52_week_date | 52주 최저가 기록일 | 날짜(YYYY-MM-DD) |
timestamp | 서버 응답 시각 (ms 단위) | API 호출 기준 시간 |
1시간봉 기준 시각, KST로 변환됨 (candle_date_time_kst) |
4️⃣ 데이터 수집 파이프라인
- 10초 마다 수집
- 응답값 파싱
- 파싱 불가 또는 없을시 None 처리
- 10분 마다 파일로 저장
- parquet 형식으로 저장
- 1시간 마다 s3 업로드
- upbit-ticker/yyyy-mm-dd/ 폴더 하위에 일별로 저장
- 배포
- ec2 - t3.중간
- docker container 기반
5️⃣ 추후 개발 방향
- 다른 종류의 모델 추가하기
- 크롤링으로 비트코인 관련 뉴스 기사 기반 예측 기능 구현
My Tasks
1️⃣ 데이터 파이트 라인 초안 구축
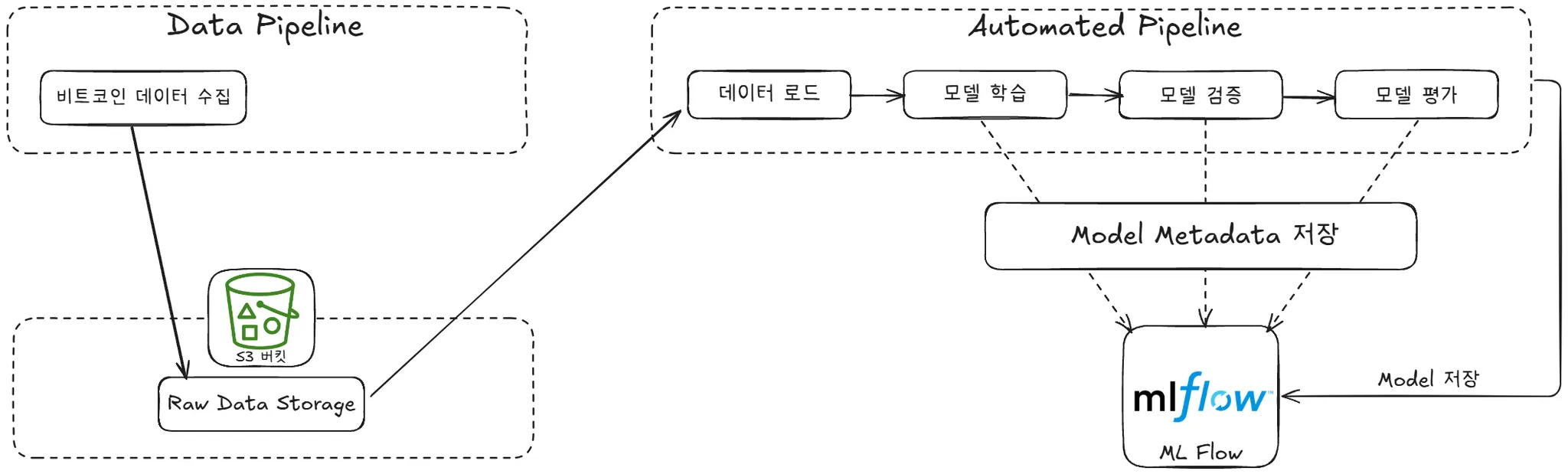
2️⃣ LSTM 모델 개발
Models
XGBoost
데이터 개수가 적은 상황에서 XGBoost를 성능이 가장 좋을 것 같았습니다. 왜냐하면 2가지 이유가 있었습니다.
- 과적합 방지 가능
- 하이퍼파라미터 조정 가능:
max_depth,min_child_weight→ 트리 복잡도 제한subsample,colsample_bytree→ 데이터 샘플링gamma→ 최소 손실 감소 기준
- 덕분에 노이즈가 있어도 안정적 학습 가능
- 하이퍼파라미터 조정 가능:
- 높은 예측 성능
- Gradient Boosting 기반이라 약한 트리를 순차적으로 학습
- 이전 트리가 틀린 부분을 다음 트리가 보완 → 정확도 상승
- 단일 결정 트리나 선형 모델보다 복잡한 비선형 관계도 잘 포착
LSTM
시계열 데이터에 특화된 순환 신경망 모델로써 기존의 RNN의 기울기 소실 문제를 해결한 모델로써 시계열 데이터를 학습하는데 유리한 것 같아서 선정했습니다.
- 시계열에 특화된 모델
- LSTM은 순차 데이터를 단계별로 처리 → 시계열 예측에 적합
- 가중치 소실 문제 해결(완벽 해결은 X)
- LSTM의 셀 상태(cell state)와 게이트 구조 덕분에 장기 의존성 학습 가능
- 하지만 아주 긴 시퀀스에서는 여전히 정보 희석 가능
Transfromer
LSTM은 RNN 계열로 순차 데이터 처리에 강점이 있었지만, 병렬 처리가 어렵고, 긴 거리 의존성 문제가 여전히 있었고, 훈련 시간이 증가되는 문제들이 있었습니다. 이러한 문제를 보완하기 위해서 나온 모델입니다.
→ 선정 (X) / 1. 시간적으로 여유가 없었습니다. 2. 이번 프로젝트는 모델의 성능이 중요한게 아니라 MLOps의 흐름을 알아가는 프로젝트기 때문에 사용하기에는 너무 딥했습니다.
Model 선택 이유
일단 위의 모델들 설명을 보면 알 수 있드시, 선택할 수 있었던 모델은 XGBoost와 LSTM 정도였습니다. 위 두 모델 중에서 성능이 높았던 LSTM을 선택을 했고, 또한 DL을 간단하게 구현해 보는게 좋은 기회지 않을까 싶어서 LSTM으로 선정을 했습니다. 또한 시계열 특성을 잘 살릴 수 있었던 것이 LSTM 모델이기 때문도 있었습니다.
Modeling
모델링은 Many to one 모델링을 사용하기로 했습니다. 즉 24 to 1의 형태로 현재 기준으로 24시간 전의 데이터를 바탕으로 1시간 후의 데이터를 예측하는 형태로 구현하기로 했습니다.
-
시간별로 학습 및 예측을 구현한 이유
: 초당 변화로 하게 되면 데이터의 변동성이 매우 클 수 있습니다. 초 단위로 예측을 진행하게 되면 단기 패턴 예측을 사용하는게 적합합니다. 따라서 초 단위가 아니라 분이나 시간 단위로 예측을 진행하기로 했습니다. 여기서 모델이 학습 및 예측을 하는 시간까지 고려하면 시간 단위로 나누는게 더 적절해 보였습니다.
-
1시간을 예측한 이유
: 일단 24시간을 통으로 예측을 한다고 하면, 168:24인데, 이렇게 되면 시퀀스 길이가 길이지기 때문에 기울기 소실 문제가 발생할 수 도 있습니다. 또한 모델이 과적합 될 위험도 생기며, 예측 간격이 길어지므로 오차가 누적될 수 도 있습니다.
Model Code
import pandas as pd
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
from tensorflow.keras import layers, Model
btc = pd.read_csv('./data/KRW-BTC_historical.csv')features = ["trade_price", "change_rate", "acc_trade_volume"]
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(btc[features])price_scaler = MinMaxScaler()
data_price = btc[["trade_price"]].values
price_scaler.fit(data_price)def create_sequences(data, seq_len=24, pred_len=1):
X, y = [], []
for i in range(len(data) - seq_len - pred_len + 1):
X.append(data[i:i+seq_len]) # 입력: 모든 feature
y.append(data[i+seq_len:i+seq_len+pred_len, 0]) # 출력: trade_price만
return np.array(X), np.array(y)
X, y = create_sequences(data_scaled, seq_len=24, pred_len=1)split = int(len(X) * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]X_train = tf.convert_to_tensor(X_train, dtype=tf.float32)
y_train = tf.convert_to_tensor(y_train, dtype=tf.float32)
X_test = tf.convert_to_tensor(X_test, dtype=tf.float32)
y_test = tf.convert_to_tensor(y_test, dtype=tf.float32)class LSTMModel(tf.keras.Model):
def __init__(self, input_size, hidden_size=256, output_size=24, num_layers=2, dropout=0.2):
super(LSTMModel, self).__init__()
# LSTM 층 여러 개 쌓기
self.lstm_layers = []
for i in range(num_layers - 1):
self.lstm_layers.append(
layers.LSTM(hidden_size, return_sequences=True, dropout=dropout)
)
# 마지막 LSTM 층 (return_sequences=False → 마지막 hidden state만 반환)
self.lstm_layers.append(
layers.LSTM(hidden_size, return_sequences=False, dropout=dropout)
)
# Fully connected (Dense) layer
self.fc = layers.Dense(output_size)
def call(self, x):
out = x
for lstm in self.lstm_layers:
out = lstm(out)
out = self.fc(out)
return outinput_size = X_train.shape[2]
hidden_size = 256
output_size = 1
model = LSTMModel(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
seq_len = X_train.shape[1]
model.build(input_shape=(None, seq_len, input_size))
model.compile(
loss=tf.keras.losses.MeanSquaredError(),
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
metrics=[tf.keras.metrics.MeanAbsoluteError()]
)
model.summary()history = model.fit(
X_train, y_train,
epochs=100,
batch_size=32,
validation_data=(X_test, y_test),
verbose=1
)
test_loss, test_mae = model.evaluate(X_test, y_test, verbose=0)
print(f"Test Loss: {test_loss:.6f}, Test MAE: {test_mae:.6f}")y_pred = model.predict(X_test)y_test_scaled = np.expm1(y_test)
y_pred_scaled = np.expm1(y_pred)y_test_scaled = price_scaler.inverse_transform(y_test.numpy())
y_pred_scaled = price_scaler.inverse_transform(y_pred.numpy())from sklearn.metrics import mean_squared_error
import numpy as np
rmse = np.sqrt(mean_squared_error(y_test_scaled, y_pred_scaled))
print(f"Validation RMSE: {rmse:.4f}")3️⃣ Streamlit UI
1) 환경 설정 및 라이브러리
streamlit,pandas,numpy,plotly,boto3,httpx,asyncio사용.env파일로부터 AWS 환경 변수(AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY,BUCKET_NAME) 로드- AWS 환경 변수가 없으면 더미 데이터 사용 → 테스트 시에도 동작하도록 설계
2) 데이터 로드 설계
(1) S3에서 시간 단위 데이터 로드
- S3 경로 구조:
upbit_ticker/{날짜}/파일 - 최근
30시간데이터를 로드 event_timestamp = timestamp(ms) + 9시간(KST)변환event_hour단위로 그룹화 → 코인별 시계열 데이터 생성
(2) 증분 데이터 로드 (Incremental)
last_load_hour기준으로 새로운 데이터만 추가 로드- 기존 데이터와 병합 후 최근 30시간만 유지
- 불필요한 중복 제거 (
drop_duplicates)
(3) 더미 데이터 생성
- AWS 미사용 시
numpy로 가격 시뮬레이션 생성 - 기본 가격 + 랜덤 변동성(0.5%) 적용
3) 예측 API 호출
(1) 비동기 호출
httpx.AsyncClient→FastAPI서버로 요청/predict/lstm엔드포인트 호출- 최근 30시간 데이터 JSON 변환 후 전송
- 예외 처리: 연결 실패, 타임아웃 시 fallback
(2) 동기 호출 Wrapper
fetch_prediction()→ 내부적으로asyncio.run()실행
(3) Fallback 예측 (더미/통계 기반)
- AI 모델 응답이 없을 경우 → 현재 가격 + 변동성 기반 랜덤 예측 생성
- 모델별 노이즈/트렌드 파라미터 적용
4) Streamlit UI 구성
(1) 사이드바 옵션
- 코인 선택 (
KRW-BTC,KRW-ETH,KRW-DOGE,KRW-XRP) - 모델 선택 (
LSTM,GRU,Prophet,LightGBM)
(2) 데이터 로드 로직
@st.cache_data사용 → 1시간 캐싱- 초기 로드는 전체 데이터, 이후에는 증분 로드
(3) 예측 실행
@st.cache_data(5분 캐싱) → 같은 데이터/시간대는 API 재호출 방지- "새로고침 버튼" 누르면 캐시 클리어 + 증분 강제 업데이트
5) 시각화 및 대시보드
(1) 메트릭 카드
- 현재 가격 (변동률 표시)
- 24시간 거래량
- 1시간 뒤 예측 가격 (증감률 + 신뢰도)
(2) 신뢰도 Progress Bar
- 예측 신뢰도 % 표시
- AI 사용 여부 (
AI 활성vs통계 모드)
(3) Plotly 차트
- 최근 24시간 가격 추이 라인 그래프
- 예측 지점 표시 (빨간/주황 dashed line)
- 신뢰 구간 (±5%)
(4) 데이터 테이블
- 최근 24시간 데이터 (
event_hour,trade_price,trade_volume)
(5) 모델 성능 지표
- RMSE, MAE, R², 예측 신뢰도, 데이터 소스(AI/통계)
(6) 시스템 상태
- AWS S3 연결 여부
- AI 예측 활성화 여부
- 데이터 품질(최근 20시간 이상 확보 여부)
(7) 자동 새로고침 옵션
- 사이드바에서 체크 → 30초 주기로
st.rerun()
📊 전체 아키텍처 흐름
- Streamlit 실행 → 사이드바에서 코인/모델 선택
- 데이터 로드
- S3에서 최근 30시간 로드 (or 더미 데이터)
- 증분 업데이트 반영
- 예측 실행
- FastAPI 호출
- 실패 시 → 통계 기반 예측
- 결과 시각화
- 메트릭 카드 + 차트 + 테이블
- 모델 성능 및 상태 표시
- RMSE/MAE/R²
- AWS 연결 상태 / AI 예측 여부
4️⃣ Github Actions CI/CD
Github Actions이란?
💡 0GitHub Actions는 빌드, 테스트 및 배포 파이프라인을 자동화할 수 있는 CI/CD(연속 통합 및 지속적인 업데이트) 플랫폼입니다. 리포지토리에 대한 모든 끌어오기 요청을 빌드 및 테스트하거나 병합된 끌어오기 요청을 프로덕션에 배포하는 워크플로를 만들 수 있습니다.GitHub Actions은(는) 단순한 DevOps 수준을 넘어 리포지토리에서 다른 이벤트가 발생할 때 워크플로를 실행할 수 있도록 합니다. 예를 들어 누군가가 리포지토리에서 새 이슈를 만들 때마다 워크플로를 실행하여 적절한 레이블을 자동으로 추가할 수 있습니다.
GitHub에서 워크플로를 실행할 Linux, Windows, macOS 가상 머신을 제공하거나, 사용자 고유의 데이터 센터 또는 클라우드 인프라에서 자체 호스트형 실행기를 호스트할 수 있습니다.
<깃허브 공식 문서>
내용이 꽤나 많아서 이해하길 힘들 것 같기는 한데, 간단하게 이해를 하면 Github를 이용한 ci/cd를 구현이 가능한 기능입니다. 또한 깃허브 Github Action에는 몇가지 구성 요소가 있습니다. 아래에서 설명을 자세히 하겠습니다!
Github Actions의 구성 요소
1️⃣ workflow
워크플로는 하나 이상의 작업을 실행할 구성 가능한 자동화된 프로세스입니다. 워크플로는 리포지토리에 체크 인된 YAML 파일에서 정의되며, 리포지토리의 이벤트로 트리거될 때 실행되거나 수동으로 또는 정의된 일정에 따라 트리거될 수 있습니다.
워크플로는 리포지토리의
.github/workflows디렉터리에 정의됩니다. 리포지토리에 다음과 같은 각각의 다른 작업 집합을 수행하는 여러 워크플로가 있을 수 있습니다.
- 끌어오기 요청을 빌드하고 테스트합니다.
- 릴리스가 생성될 때마다 애플리케이션을 배포합니다.
- 새 문제가 보고될 때마다 레이블을 추가합니다.
2️⃣ events
이벤트는 워크플로 실행을 트리거하는 리포지토리의 특정 활동입니다. 예를 들어 누군가가 끌어오기 요청을 만들거나, 이슈를 열거나, 리포지토리에 커밋을 푸시할 때 GitHub에서 활동이 시작될 수 있습니다.
3️⃣ jobs
작업(Job)은 워크플로에서 동일한 러너(Runner)에서 실행되는 일련의 단계(Step) 집합입니다. 각 단계는 실행될 셸 스크립트이거나 실행될 액션(Action)일 수 있습니다. 단계는 순서대로 실행되며 서로 의존 관계가 있습니다. 모든 단계가 동일한 러너에서 실행되므로 한 단계에서 다른 단계로 데이터를 공유할 수 있습니다. 예를 들어, 애플리케이션을 빌드하는 단계 다음에 빌드된 애플리케이션을 테스트하는 단계를 둘 수 있습니다.
작업은 다른 작업과의 의존성을 설정할 수 있습니다. 기본적으로 작업에는 의존성이 없으며 병렬로 실행됩니다. 작업이 다른 작업에 의존하도록 설정되면, 해당 작업이 완료될 때까지 대기한 후 실행됩니다.
또한 매트릭스(Matrix)를 사용하여 동일한 작업을 여러 번 실행할 수 있으며, 각 실행마다 운영체제나 언어 버전과 같은 다른 변수 조합을 적용할 수 있습니다.
4️⃣ actions
액션(Action)은 워크플로 내에서 특정 작업을 수행하는 미리 정의된 재사용 가능한 작업(Job) 또는 코드 집합으로, 워크플로 파일에서 반복되는 코드를 줄여줍니다. 액션이 수행할 수 있는 작업의 예시는 다음과 같습니다.
- GitHub에서 Git 리포지토리 가져오기(Pull)
- 빌드 환경에 맞는 도구 체인(toolchain) 설정
- 클라우드 제공자(cloud provider) 인증 설정
직접 액션을 작성할 수도 있고, GitHub 마켓플레이스(GitHub Marketplace)에서 워크플로에 사용할 액션을 찾아 사용할 수도 있습니다.
5️⃣ 실행
러너(Runner)는 워크플로가 트리거될 때 해당 워크플로를 실행하는 서버입니다. 각 러너는 한 번에 하나의 작업(Job)만 실행할 수 있습니다. GitHub는 워크플로 실행을 위해 Ubuntu Linux, Microsoft Windows, macOS 러너를 제공합니다. 각 워크플로 실행은 새로 프로비저닝된 가상 머신(VM)에서 실행됩니다.
🏋️ Cloudtype의 GitHub Actions
name: Streamlit CI/CD
on:
push:
paths:
- 'streamlit/app.py'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
# 1️⃣ 레포지토리 코드 가져오기
- name: Checkout repository
uses: actions/checkout@v3
# 2️⃣ Docker Buildx 설치
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
# 3️⃣ Docker 이미지 빌드
- name: Build Docker image
run: |
docker build -t bitcoin-ui ./streamlit
# 4️⃣ 기존 컨테이너 종료/제거 후 새 컨테이너 실행
- name: Run Docker container
run: |
docker stop bitcoin-ui || true
docker rm bitcoin-ui || true
docker run -d -p 8501:8501 --name bitcoin-ui bitcoin-ui
🔥 Issue 발생
Github Action이 작동하는 방법이 2가지 있습니다. 설명은 아래를 읽어보시면 될 것 같습니다. 여튼 위 두 방법중에 Action Runner를 쓰게 되면 Action Runner 역시 관리를 해줘야하기 때문에 관리 해야할 task가 늘어났습니다. 그래서 ssh로 원격 서버에 연결하는 방식을 사용하기로 했습니다. 이 부분에서 AWS의 보안그룹 문제가 발생했습니다.
1️⃣ Action Runner를 통해 실행하는 방법
- GitHub Actions 자체 구조
- 워크플로(
.github/workflows/*.yml)를 러너(Runner)가 읽어서 실행 - 러너는 GitHub 호스티드 러너 또는 셀프 호스티드 러너 모두 가능
- 특징:
- Job과 Step 단위로 정의된 명령을 자동 실행
- GitHub와 연결되어 이벤트 트리거(push, PR 등)에 따라 동작
- 예: Python 스크립트 실행, Docker 빌드, 테스트, 배포 등
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: python main.py2️⃣ SSH로 원격 서버에 연결해 스크립트를 실행하는 방법
- GitHub Actions 워크플로 안에서 SSH 접속 후 명령 실행
- 주로 원격 서버 배포 또는 특정 환경에서만 실행 가능한 스크립트에 사용
- 특징:
- 서버에 직접 접근 가능 → 서버 환경 그대로 활용
- self-hosted 러너 없이도 가능, 다만 SSH 키/접속 설정 필요
- 예: AWS EC2, 온프레미스 서버에 배포 스크립트 실행
- name: Deploy via SSH
uses: appleboy/ssh-action@v0.1.9
with:
host: ${{ secrets.SERVER_IP }}
username: ${{ secrets.SERVER_USER }}
key: ${{ secrets.SERVER_KEY }}
script: |
cd /app
git pull
docker-compose up -d🔹 핵심 차이
| 방식 | 설명 | 특징 |
|---|---|---|
| Action Runner | 워크플로를 직접 Runner가 실행 | GitHub 이벤트 기반, 자동화 중심 |
| SSH 연결 | 워크플로에서 원격 서버 접속 후 스크립트 실행 | 원격 환경 활용, 배포/관리 중심 |
AWS 보안그룹
AWS 보안 그룹이 무슨 이슈가 있냐고 하면 결국에 ssh로 연결을 해서 스크립트를 실행하는 방식이기 때문에 들어오는 호스트를 특정 할 수 있어야 합니다. 하지만 깃허브 actions의 경우에는 IP가 계속해서 바뀌는 문제가 있었습니다. 아래의 2가지 상황에서 할 수 있는 방법들이 있습니다.
1️⃣ 모든 호스트 ssh 연결 허용
야생과 같은 인터넷 세상에서 모든 호스트에 대해서 ssh를 연결하는 경우에는 AWS 비용으로 유사 유럽 풀패키지 여행을 다녀올 수 있습니다. 그렇다면 왜 모든 호스트 연결이란 방법이 있을까요?
바로 AWS에서 자체적으로 발급해주는 보안키입니다. 해당 보안키를 유출하지 않는 이상 위와 같이 유사 유럽 풀패키지 여행을 다녀올 수는 없을 겁니다. 하지만 여기서 보안키를 유출하지 않는다는 가정이 있는데, 이 사바나와 같은 인터넷 세상에서 키를 잃어버리는 것은 어려운 일은 아니죠..따라서 아래 방법을 사용하기로 했습니다.
2️⃣ 내 IP만 ssh 연결 허용
나의 IP만 ssh 연결을 하게 되면 깃허브 action의 IP는 계속 바뀌기 때문에 내 IP를 하면 어떻게 연결을 하냐 싶지만, 연결할 수 없습니다. 그래서 뭘 하겠냐는 말이냐면, 아래 해결방법 부분에서 자세히 설명해 드리겠습니다.
💡 해결방법
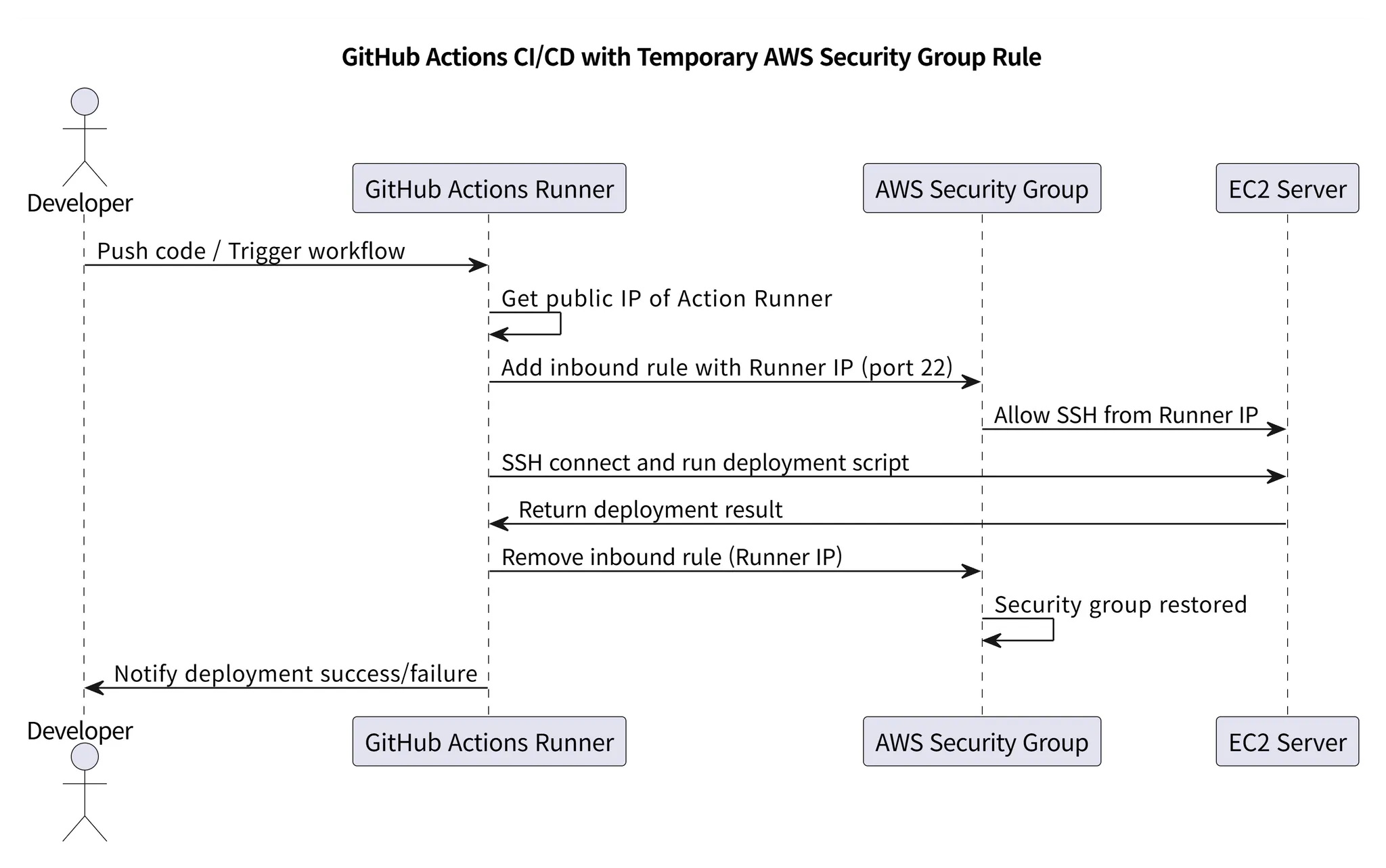
github action이 작동을 하게되면 해당 요청에 대한 IP를 저장하고 해당 IP를 저장해뒀다가 나중에 AWS의 보안 그룹에 임시로 추가를 해두고 스크립트 작업 이후에는 보안 그룹을 삭제하는 식으로 구현을 했습니다. 이러한 방법으로 github action ci/cd를 구축했습니다.
But…
배스천 호스트..를 쓰는게 현업에서 쓰는거라고 합니다..
🤔 Bastion Host란?
- 내부 서버에 안전하게 접근하기 위한 중간 게이트웨이 서버
- 외부에서 직접 EC2에 접근하지 않고, Bastion Host를 통해서만 접근
- Bastion Host는 보안 그룹에서 특정 IP(예: 사무실 IP, VPN IP)만 허용
- 내부 서버(Private Subnet의 EC2)는 외부와 직접 연결되지 않고 Bastion을 통해서만 접근 가능
- 흐름
- GitHub Actions Runner → Bastion Host로 SSH 접속
- Bastion Host → 내부 EC2로 접근하여 배포 수행
- 장점
- 보안 그룹 변경 불필요 (항상 Bastion만 열려 있음)
- 접근 경로를 단일화하여 관리 용이
- 로깅/모니터링이 쉬움 (누가 언제 어떤 서버 접속했는지 기록)
즉, IAM 인증을 사용해서 ssh를 접근하게 한다!
5️⃣ FastAPI 기반 비트코인 가격 예측 서버 구조 정리
1️⃣ main.py (FastAPI 앱 설정)
- FastAPI 서버 실행 및 CORS 설정
app = FastAPI( title="Bitcoin Prediction API", description="비트코인 가격 예측을 위한 FastAPI 서버", version="1.0.0" ) - CORS 허용 (모든 Origin/Method/Header 허용)
- 라우터 자동 등록
for router, prefix, tags in routers: app.include_router(router) - uvicorn 실행 포인트
if __name__ == "__main__": uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
2️⃣ core/config.py (환경 설정 관리)
.env기반 환경 변수 관리 (pydantic_settings.BaseSettings)- 설정값
ML_FLOW_URL→ MLflow 서버 주소MODEL_NAME→ 모델 이름MODEL_VERSION_ALIAS→ 모델 버전 aliasMODEL_URL→models:/모델명/버전형태 URI 생성
3️⃣ core/utils.py (모델 로딩 및 전처리)
🔹 scale_model_load()
- MLflow에서 모델 및 Scaler 불러오기
- 모델:
mlflow.keras.load_model scaler_X.joblib,scaler_y.joblib다운로드 후 로드
- 모델:
- 비동기 방식으로 실행 (CPU 블로킹 최소화)
🔹 data_preprocess(df)
- 입력 DataFrame 정리 과정:
timestamp변환 및 인덱스 설정- 1시간 단위 리샘플링 (
resample("1H")) - 이동평균 (
MA_3,MA_6) 생성 - Lag Feature (
lag_1) 생성 - 결측치 제거
- 입력 시퀀스 (길이 24) 생성
- 최종 반환:
(X_input, num_features)
🔹 model_predict()
- 입력 데이터 스케일링 → 모델 예측 → 결과값 역스케일링
- 출력: 다음 1시간 예측 가격 (
y_pred)
4️⃣ api/__init__.py (라우터 자동 등록)
api디렉토리 내routes_*.py파일을 자동으로 탐색- 각 모듈의
router를 FastAPI 앱에 등록 - 규칙:
- 파일명
routes_xxx.py - prefix:
/xxx - tag:
"Xxx"
- 파일명
5️⃣ api/routes_predict.py (예측 API 라우터)
🔹 엔드포인트 정의
- POST /predict/lstm
- 요청 바디(
PredictRequest){ "coin": "BTC", "model": "lstm", "recent_data": [ {"event_timestamp": "...", "trade_price": ..., "acc_trade_volume": ...}, ... ] }
🔹 처리 흐름
-
recent_data→ DataFrame 변환 -
scale_model_load()→ 모델 + 스케일러 불러오기 -
data_preprocess(df)→ 입력 데이터 전처리 -
model_predict()→ 모델 예측 수행 -
예측 결과 반환
{ "coin": "BTC", "model": "lstm", "predicted_price": 48000000.0, "metrics": { "rmse": 25000, "mae": 15000, "r2": 0.92 } }
✅ 전체 동작 시퀀스
- 클라이언트 요청 (
/predict/lstmPOST, 최근 데이터 전송) - FastAPI 서버 → 라우터 매칭
- 모델/스케일러 로딩 (
scale_model_load) - 데이터 전처리 (
data_preprocess) - 모델 추론 (
model_predict) - 예측 결과 응답 반환
