
본 글은 주변 쓰레기통을 찾아주는 서비스 binder를 개발하며 발생한 이슈를 서술하였습니다.
캐시
지금 구조는 댓글을 작성할 때마다 DB에 매번 접근한다. 이에 대응하기 위해 현재 구조에 캐시를 추가하고자 한다.
사실, 현재 우리 시스템의 욕설 데이터 양은 많지 않아서 DB만으로도 필터링 서비스를 원활하게 운영할 수 있다. 따라서 지금 당장 캐시를 도입하는 것은 오버엔지니어링일 수 있다.
하지만 항상 시스템 확장을 염두에 두어야한다. 추후 데이터 양이 증가하거나 서비스 요구사항이 변경될 경우, 캐시 도입이 필요할 수 있다. 이러한 가능성에 대비하여, 현재는 필수적이지 않지만 캐시 구현을 시도해보기로 결정했다.
Redis
캐시는 크게 로컬 캐시와 글로벌 캐시로 나뉘어질 수 있다. 나는 글로벌 캐시 중 하나인 Redis를 사용하기로 하였다. 그 이유는 아래와 같다.
- 로컬 캐시는 어플리케이션과 같은 서버를 사용하므로 애플리케이션 성능에 영향을 줄 수 있다.
- 로컬 캐시는 어플리케이션에 상태를 부여하는 것과 같다. 그러므로 확장에 취약하다.
- 글로벌 캐시에는 대표적으로 Redis와 Memcached가 있다. MemCached는 key-value만 지원하는 반면 Redis는 다양한 자료구조를 지원한다.
- Redis는 데이터 영속화 기능을 가지고 있으므로 갑작스러운 장애에 대응할 수 있다.
- 싱글스레드이므로 캐싱 뿐만 아니라 추후 동시성 제어에 활용할 수 있다.
Set
Redis에서는 set이라는 자료구조를 제공한다. 자바의 Set과 비슷한 개념으로 생각하면 된다. 이제 본격적으로 set을 사용해서 욕설을 캐싱을 해보자.
Redis의 설정과 관련된 내용은 인터넷에 많이 나와있으므로 생략하였다.
아래의 코드는 각각 욕설을 set에 저장하고, set에 존재하는지 확인하는 로직이다.

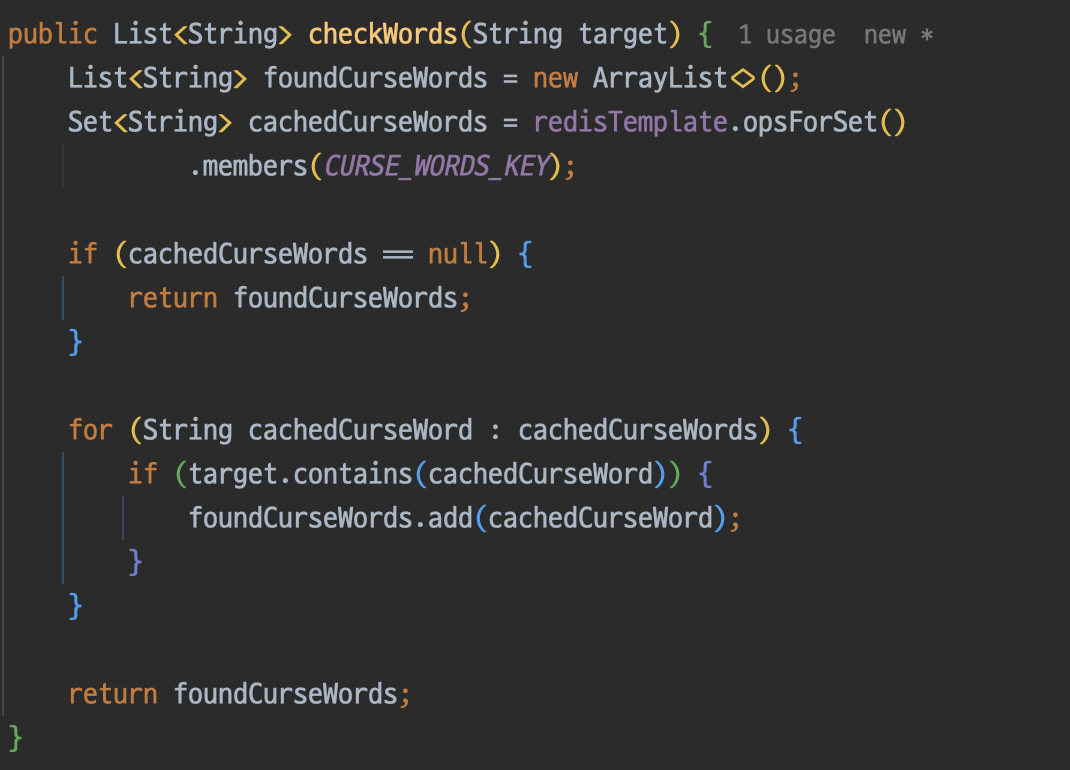
그리고 필터링 서비스에 해당 코드를 적용한다.
변경된 전체 흐름은 다음과 같다.
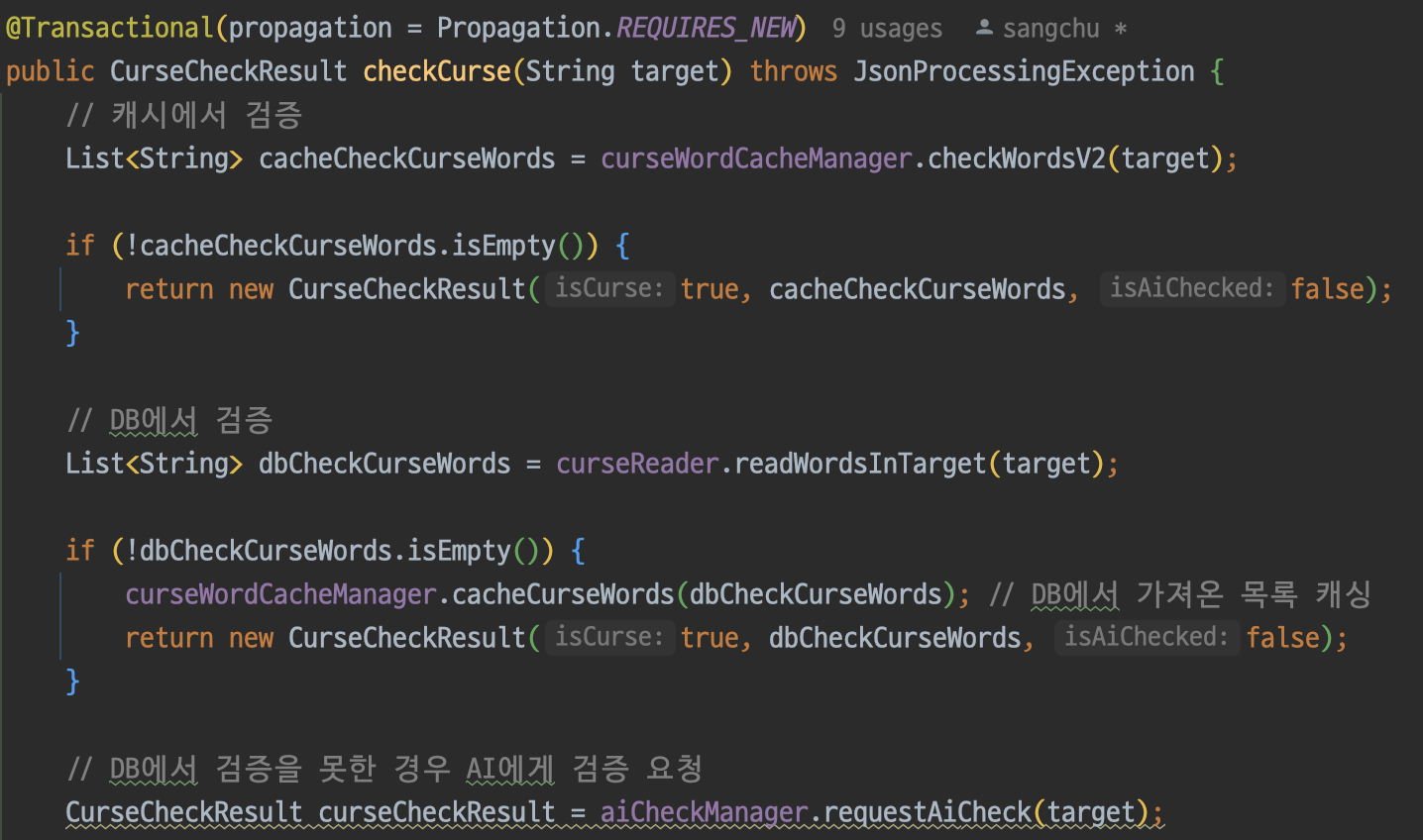
- 캐시를 먼저 확인한다.
- 캐시에 의해 욕설이 검출되면 결과를 리턴한다.
- 캐시에 의해 검증되지 않으면 DB에 의한 검증을 시도한다.
- DB에 의해 욕설이 검출되면 캐시에 저장하고 결과를 리턴한다.
- DB에 의해 욕설이 검출되지 않으면 AI에 검증을 요청한다.
- 이후 로직 동일
성능 부하 테스트
자 이제 성능 부하 테스트를 해보자. 여러 테스트 도구 중에서 이번에는 가볍기로 유명한 K6를 사용해보기로 하였다. 정확성을 위해서 원래 실제 서버(EC2)에 애플리케이션을 띄우고 테스트를 진행해야하지만 코드 수정 및 배포의 번거로움으로 인해 로컬에서 진행하기로 했다.
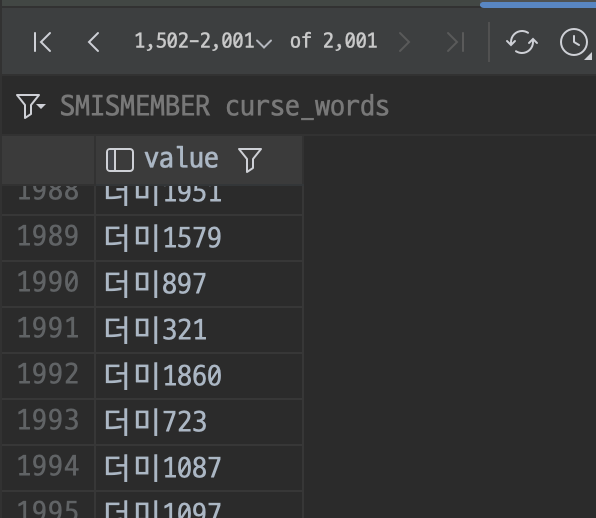
그리고 좀더 정확한 테스트 상황을 조성하기 위해 파레토의 법칙에 따라 DB의 약 20% 의 데이터를 캐시에 저장한다고 가정하고 아래와 같이 2000개의 데이터를 캐싱하였다.
그리고 아래와 같이 스크립트를 작성하고 테스트를 진행해보았다!
근데... 요청이 하나도 처리가 안되었다. 왜 이러는걸까?

로그를 확인해보니 커넥션이 말라버렸다고 한다. 왜?
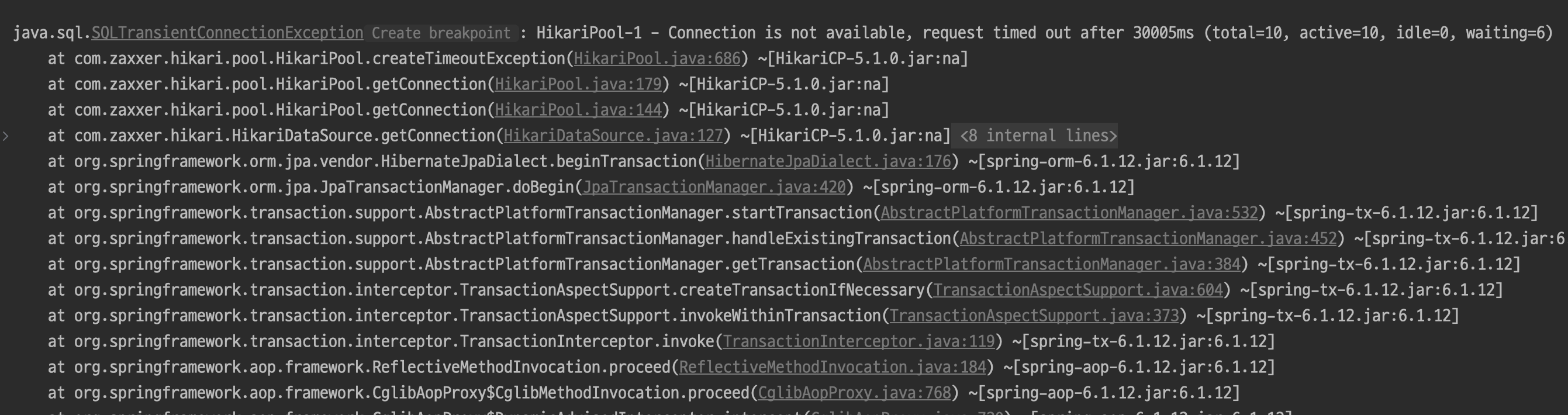
커넥션 고갈
그 이유는 checkCurse 메서드 때문이었다. 해당 메서드의 트랜잭션 전파 옵션을 requires_new로 설정해놓았는데 하나의 댓글 작성 요청당 커넥션을 두개씩 점유하게 되므로 커넥션이 말라버리는 현상이 발생한 것이다.


나는 다행히 이 문제를 해결할 방법을 알고 있었다. 당시 requires_new를 이용했던 이유는 기존 코드를 최대한 수정하지 않는 선에서 트랜잭션을 분리하기 위함이었다. 이제는 다른 방법을 사용해야할 때가 왔다.
먼저 전파 옵션에서 requires_new를 제거해주자.

그리고 commentServcie의 createComment에서도 트랜잭션을 제거해준다. 사실 이부분이 핵심인데, @Transactional은 꼭 필요한 곳에만 사용해야한다.
해당 메서드에서 DB의 데이터를 조작하는 작업은 총 2번 이루어진다.
- 욕설을 DB에 저장할 때
- 코멘트를 DB에 저장할 때
욕설을 저장할 때는 코멘트와 함께 저장되지 않는다. 그리고 코멘트를 저장할 때도 욕설을 함께 저장하지 않는다.
즉, 애초에 두 작업은 같은 트랜잭션으로 묶일 필요가 없는 것이다. 그래서 나는 파사드 패턴을 적용하고 각각 구현체에서 트랜잭션을 적용하기로 하였다. checkCurse 부분은 이미 트랜잭션이 적용되어 있으므로 comment를 저장하는 부분만 트랜잭션을 적용해주면 된다.
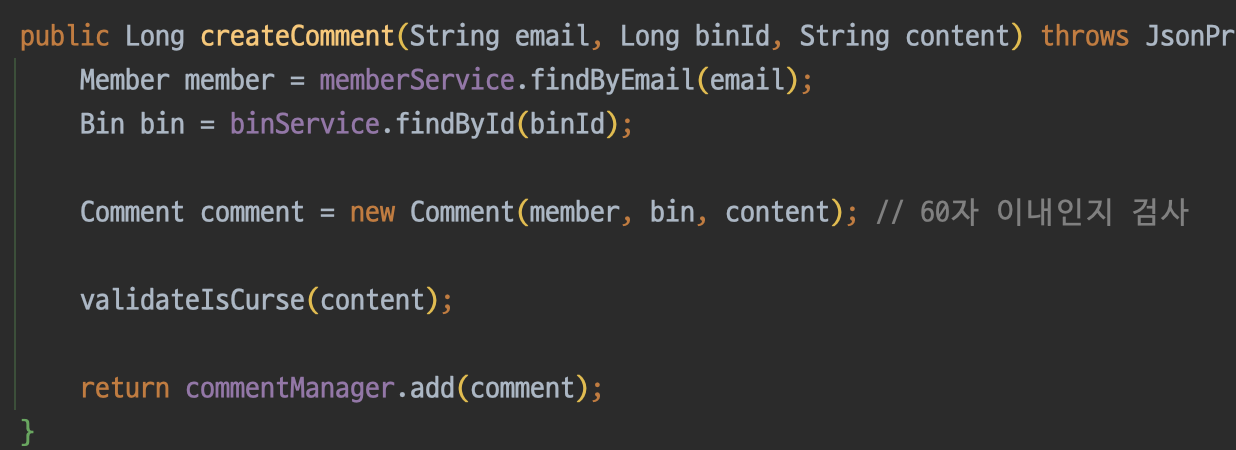
아래와 같이 구현체를 하나 만들고 트랜잭션을 적용해주었다.
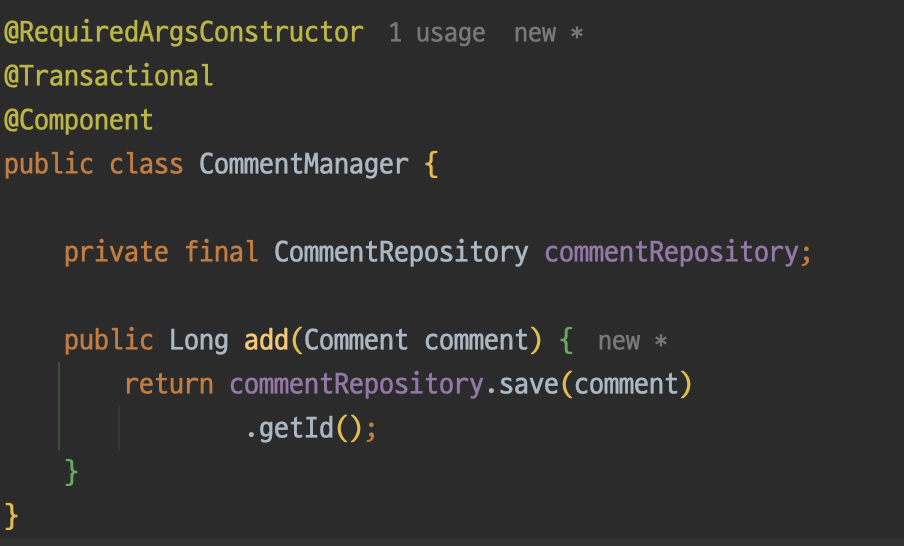
정리해보자면 기존에는 아래와 같은 방식으로 한번의 요청에 두개의 커넥션을 사용했다면
- createComment 호출 - 트랜잭션1 시작
- checkCurse 호출 - 트랜잭션2 시작
(커넥션 2개 사용) - checkCurse 종료 - 트랜잭션2 종료
- checkCurse 종료 - 트랜잭션1 종료
지금은 아래와 같이 변경된 것이다.
- createComment 호출 - 트랜잭션 시작 x
- checkCurse 호출 - 트랜잭션 1 시작
- checkCurse 종료 - 트랜잭션 1 종료
- add 호출 - 트랜잭션 1 시작
- add 종료 - 트랜잭션 2 종료
- createComment 종료
이런식으로 한번의 요청에 하나의 커넥션을 사용하므로 커넥션이 마르는 상황을 방지할 수 있다.
그동안 왜 커넥션 관리에 신경써야 하는지 크게 와닿지 않았었는데 이번에 제대로 알게 되었다.
이제 테스트를 다시 진행해보자!
다시 테스트
먼저 캐시 없이 진행했을 때의 결과이다.
초당 약 476 TPS를 처리하는 것을 볼 수 있다.

이번엔 캐시를 사용했을 때의 결과이다.
... 어째 별로 성능 향상이 되지 않는 것 같다.

왜 이런 결과가 나온걸까? 어디서 병목현상이 발생하는지 확인하기 위해 인텔리제이의 프로파일러를 사용하였다.
문제의 지점은 바로 레디스에서 캐시에 있는 모든 욕설을 가져오는 부분이었다. 몇번의 테스트를 해봤는데, 캐시에 담는 데이터가 커질수록 병목현상은 더욱더 심해졌다.
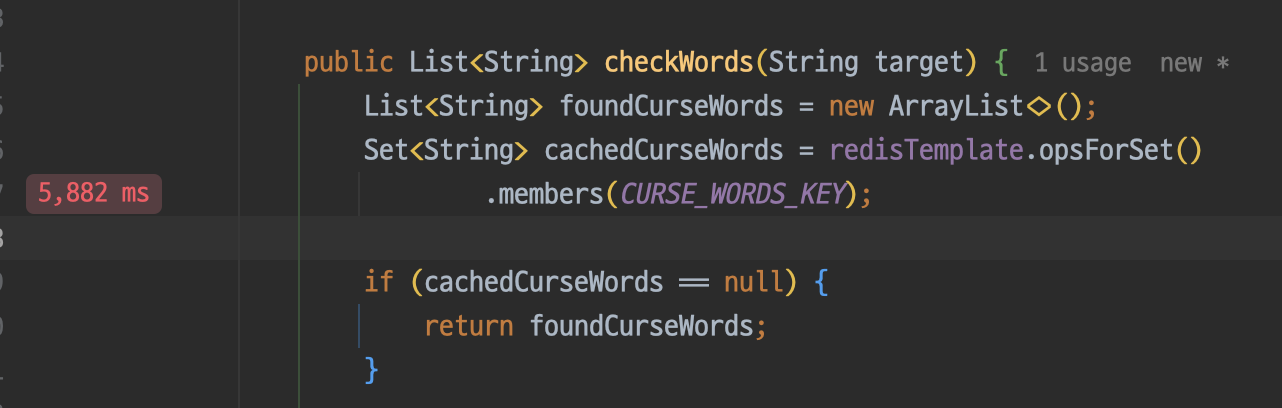
이 문제를 어떻게 해결할 수 있을까 고민하던 중 redis의 scan 기능을 통해 청크 단위로 로직을 수행할 수 있다는 것을 알게되었다. 하지만 이 방법을 사용해도 성능은 전혀 개선되지 않았다.
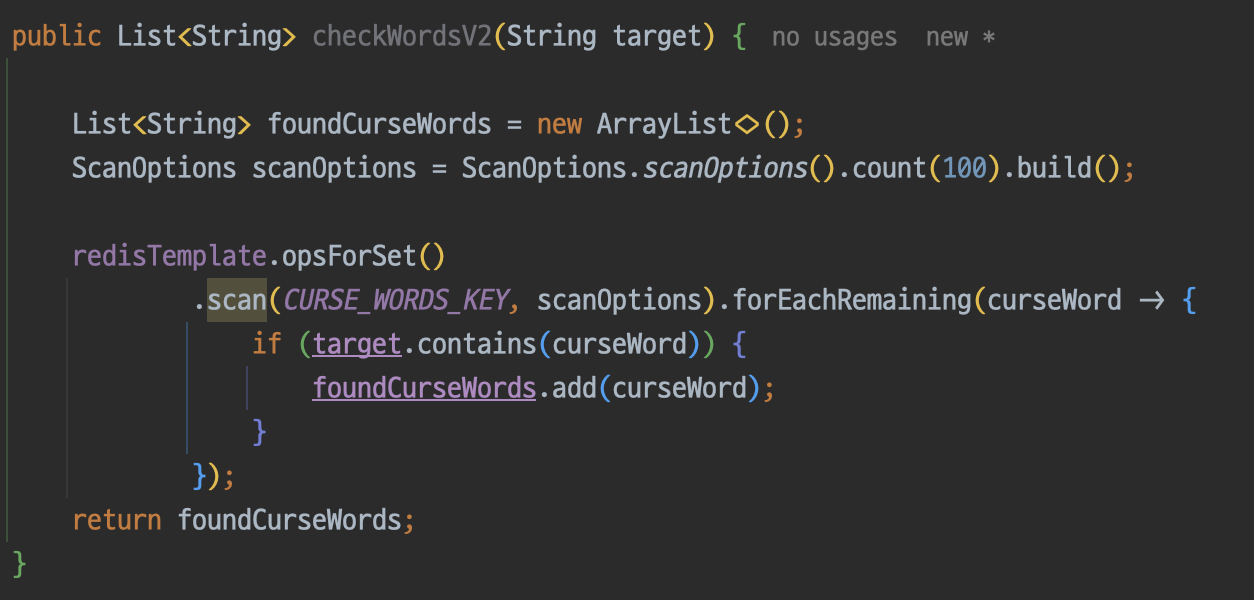
이후 DB의 데이터를 10만개로 늘리고 레디스의 데이터는 2000개 그대로 유지시킨 상태로 테스트를 해봤는데 약 5배의 성능 차이가 났다.
즉, DB에는 데이터가 엄청나게 쌓여있지만 그 데이터들이 대부분 허수여서 실제로 사용되는 데이터는 약 2% 정도일 경우에는 캐시가 유효할 수 있겠다.
결론
결국 나는 현재 욕설 필터링에서는 캐시를 사용하지 않기로 하였다. 캐시를 도입하면 모든 상황에서 항상 빨라질 줄 알았는데 내 착각이었다.
(물론 내 상황처럼 Set을 모두 순환하는게 아니고 특정 key를 조회했을때 값을 바로 조회할 수 있는 상황었다면 이야기는 달랐을 것이다.)
이번 경험을 통해 기술 적용에 있어 맹목적이면 안 된다는 걸 깨달았다. 캐시가 모든 상황에서 만능 해결책은 아니었다.
문제를 찾고 해결하는 과정이 개발자에겐 정말 중요하다는 것도 다시 한번 느꼈다. 앞으로 새로운 기술을 도입할 때는 항상 비판적으로 생각하고, 꼭 테스트해봐야겠다.
남은 과제
아직 가장 큰 중요한 과제가 남아있다. 댓글을 작성할 때 욕설이 포함되어 있지 않을 경우 매번 AI에게 검증을 받기 때문에 항상 1초 이상의 시간이 걸린다. 이 상황을 꼭 해결해보고 싶다.

참고 문헌
