
본 글은 주변 쓰레기통을 찾아주는 서비스 binder를 개발하며 발생한 이슈를 서술하였습니다.
느린 응답 속도
지난번에 GPT의 응답을 바탕으로 후처리 기능을 구현하며 서비스의 안정성을 높였으나 아직 문제가 많이 남아있다.
GPT의 느린 응답 속도로 인해 매번 댓글을 작성할 때마다 1초 이상 소요되는 문제가 발생하였다. 지금 구조에서는 사용자가 댓글을 작성할 때마다 매번 GPT에 요청을 보낸다.
만약 지금보다 훨씬 많은 사용자가 댓글을 작성을 하게 된다면 응답속도가 더욱 떨어지게 될 우려가 있으므로 반드시 구조를 개선할 필요가 있었다.

DB 학습시키기
GPT에게 매번 요청을 보내지 않을 방법을 고민하던 중 아이디어가 하나 떠올랐다.
그것은 바로 DB를 학습시키는 것이다.
아이디어는 이렇다.
- 댓글을 작성할 시 GPT에 검증을 요청한다.
- 욕설 포함 여부, 욕설 목록을 응답 받는다.
- 후처리 로직을 통해 GPT의 응답이 정상인 경우에만 욕설 목록을 DB에 저장한다.
- 추후 댓글 작성할 때 DB의 욕설 목록을 먼저 확인한다.
- DB에 의해 걸러지지 않는다면 GPT에 검증을 요청한다.
- 이후 반복
처음에 DB에 욕설 목록을 저장하는 방법을 사용하지 않았던 이유는 필터링을 우회하는 데이터(ex: 뮈1췬)를 일일이 추가하기 어려웠기 때문이다.
즉, DB를 학습시키는 방법을 사용하면 관리자가 새로운 욕설을 매번 직접 추가하지 않아도 되기 때문에 위 문제를 해결할 수 있다.
코드에 적용하기
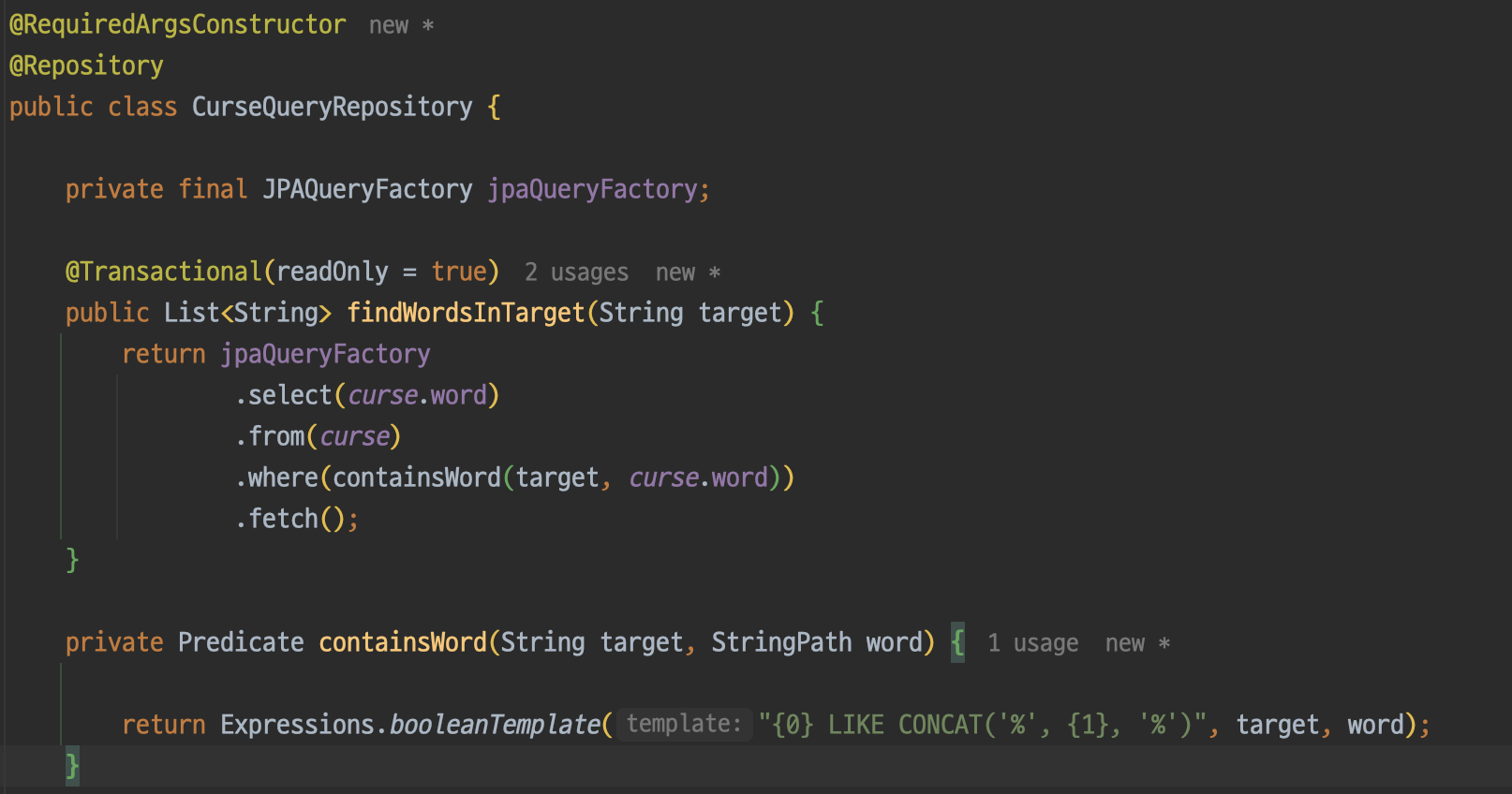
먼저 Curse 엔티티 클래스를 만들고 word 조건에 대한 빠른 탐색을 위해 유니크 인덱스를 걸어주었다.

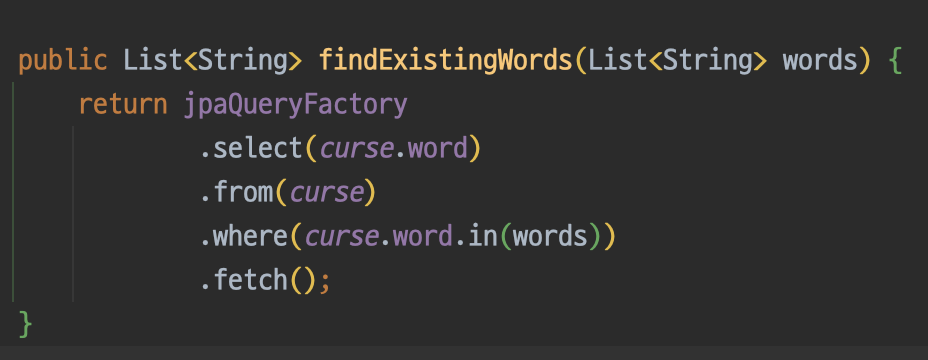
repository에서는 target안에 포함된 word 목록을 반환하는 메서드를 구현한다. 일단 where절에 가장 간단한 방법인 like를 사용해보았다.
그리고 욕설 데이터를 가상으로 약 10000개 정도 생성한 뒤 쿼리 실행계획을 확인해보았다.

..? word에 인덱스를 설정해줬는데도 풀스캔을 한다. 왜 그런걸까?

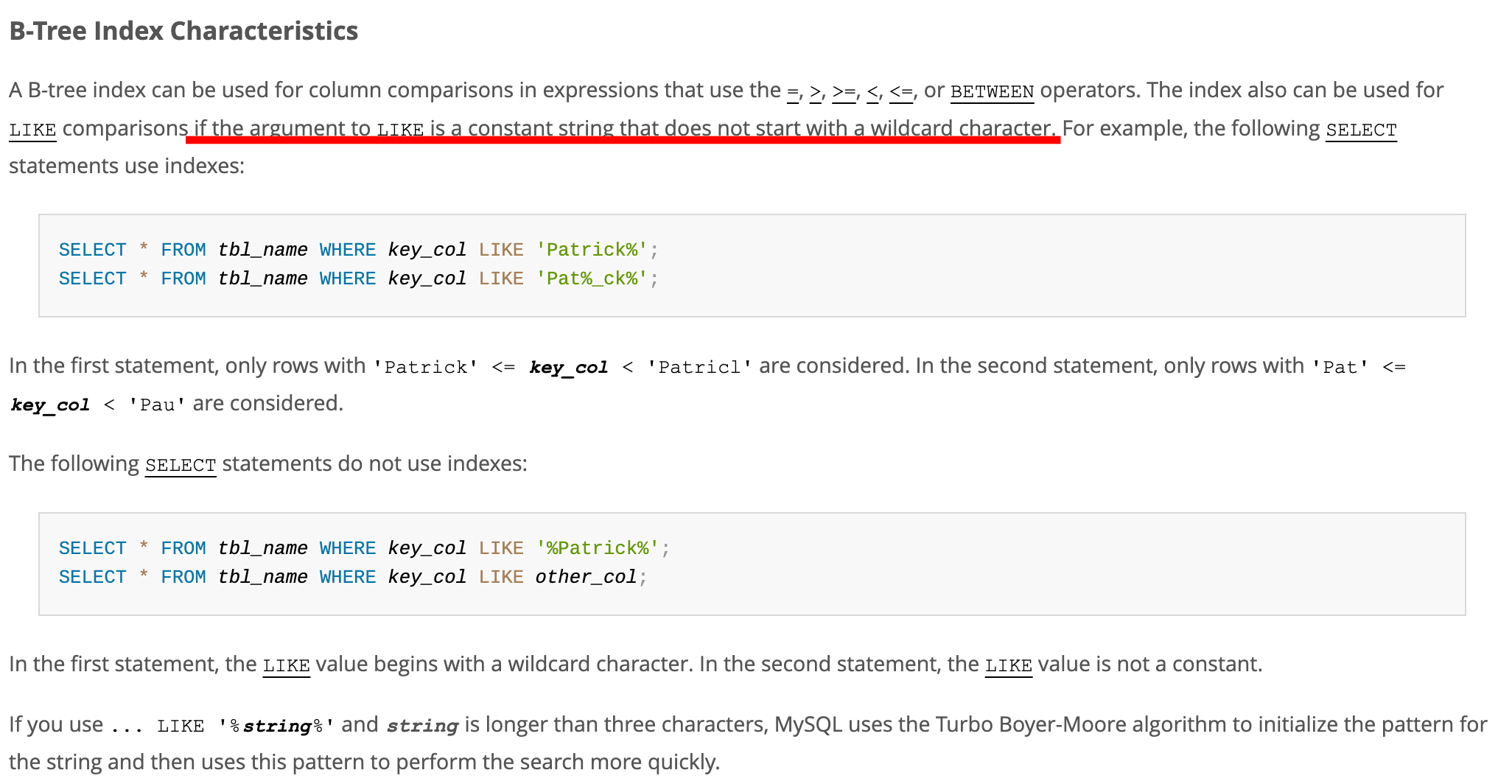
이에 대한 힌트는 MySQL의 공식문서에서 확인할 수 있었다. B-Tree Index에 대한 설명을 보면 Like를 사용할 때, 문자열의 앞 부분에 와일드 카드가 있으면 인덱스가 적용되지 않는다고 한다. 즉, 'word%'는 인덱스 적용이 가능하고 '%word%'는 불가능한 것이다.
그렇다면 어떤 방법을 써야할까?
MySQL은 텍스트 타입의 컬럼을 빠르게 탐색할 수 있도록 Full-Text Index를 제공한다.

하지만 욕설 필터링의 경우 Full-Text Index 방식이 적절하지 않았다. 그 이유는 저장되어 있는 문자열(욕설)이 입력되는 문자열(댓글 본문)보다 짧기 때문이다.
아래는 실험을 통해 얻은 결과이다.
- DB에는 '아x같네'라는 욕설이 등록되어 있다.
- stop word를 사용할 경우 '쓰레기통이 없네 아x같네ㅋㅋ'라는 문구에서 욕설이 발견되지 않는다. '아x같네'와 '아x같네ㅋㅋ'가 다르기 때문이다.
- ngram을 사용할 경우 '여기는 어디 앞인거 같네'라는 문구에서 욕설이 발견된다. ngram은 단어를 잘게 쪼개는 방식인데 '아x같네'를 '아x','같네'로 쪼개기 때문에 '같네'라는 단어만 사용해도 욕설로 인식하기 때문이다.
결국 나는 인덱싱을 포기하고 like 방식을 사용하기로 결정하였다.
그 이유는 웹에 올라와 있는 욕설 데이터들이 대부분 10000개 전후로 구성되어 있기 때문에 우리 프로젝트의 욕설 데이터도 그 정도 규모가 될 것이라고 생각했고, 풀스캔을 하더라도 크게 부담이 없을 것이라 판단했기 때문이다.
그리고 만약 성능이 느려지더라도 추후 캐시를 도입하면 해당 문제를 해결할 수 있을 것이라 생각했다.
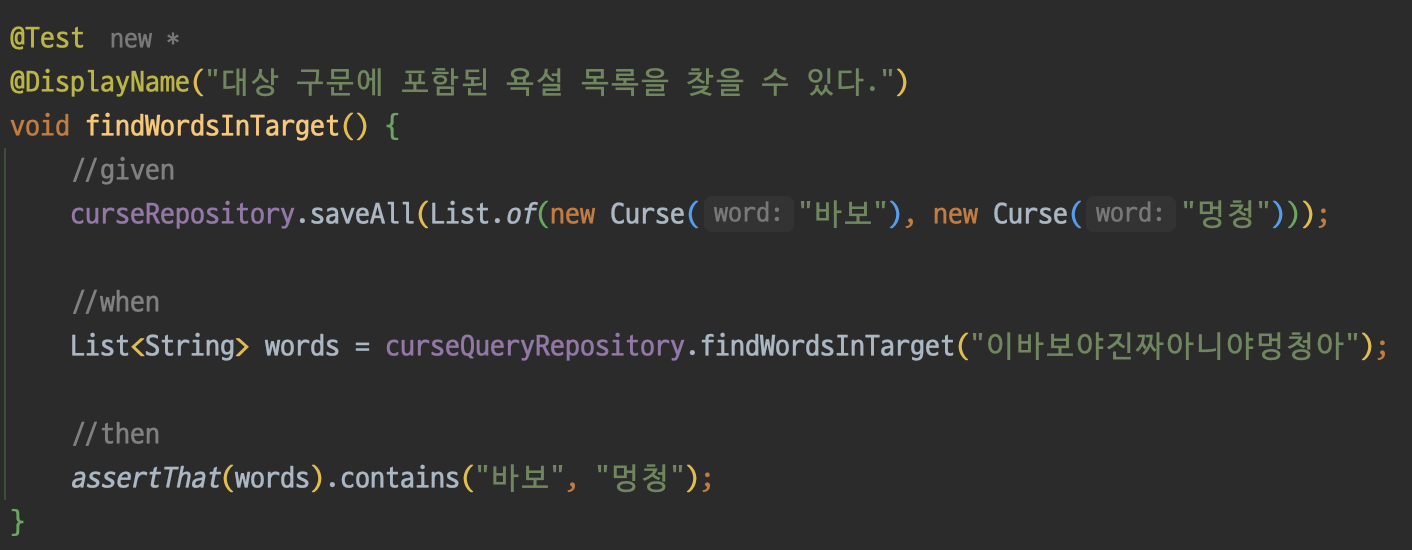
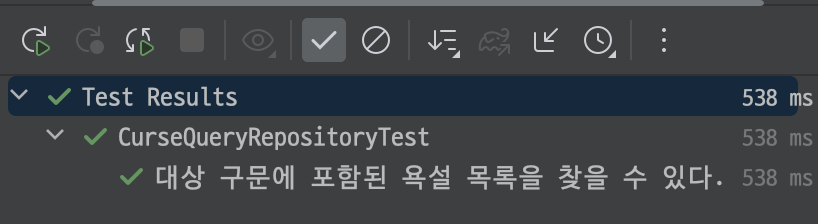
이제 위에서 만든 메서드의 테스트를 진행해보자!
다음으로 AI가 욕설로 지정한 단어 중에서 DB에 존재하지 않는 새로운 단어들만 추출하는 메서드를 만든다.
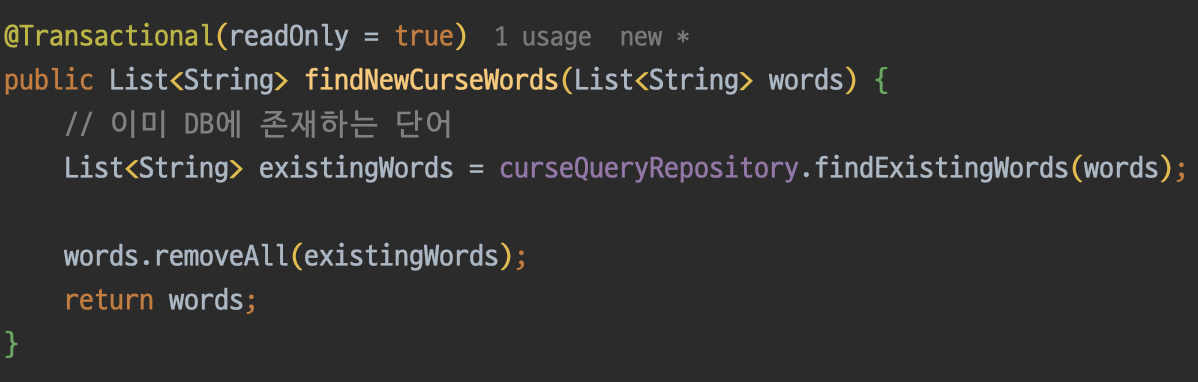
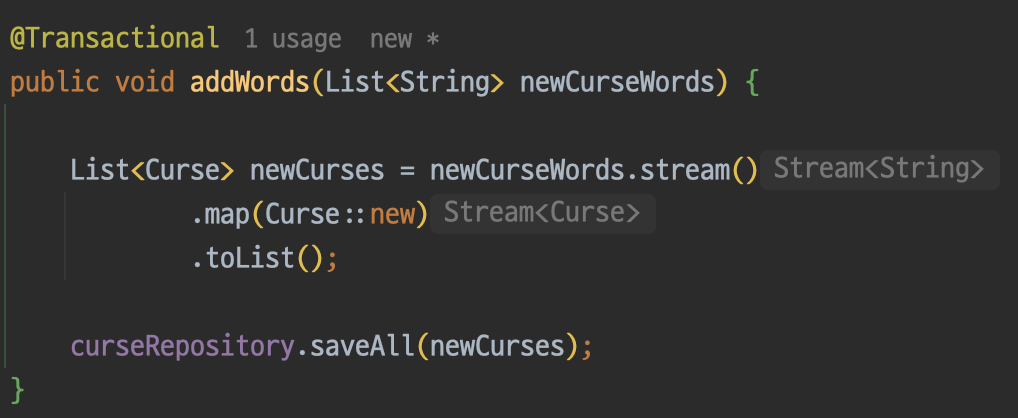
그리고 새로운 단어들을 저장하는 메서드도 만들어준다.
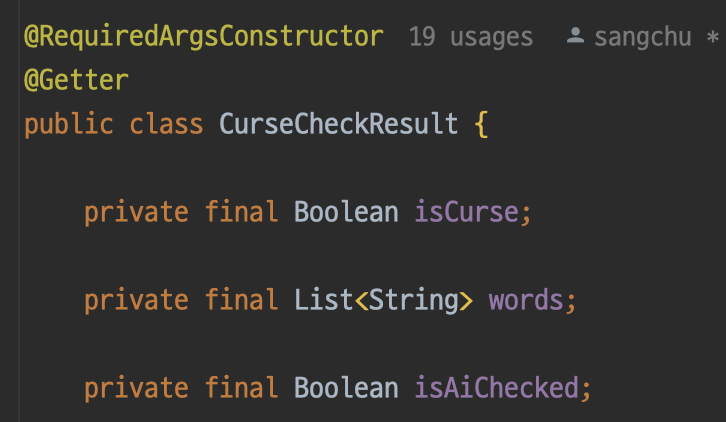
CurseCheckResult에는 AI 검증 진행 여부를 확인하기 위해 DTO에 값을 추가해준다.
내친김에 리팩토링도 해보자.
기존 AiCheckManager 클래스를 만들고 AI 검증에 대한 책임을 해당 클래스로 몰아주었다.
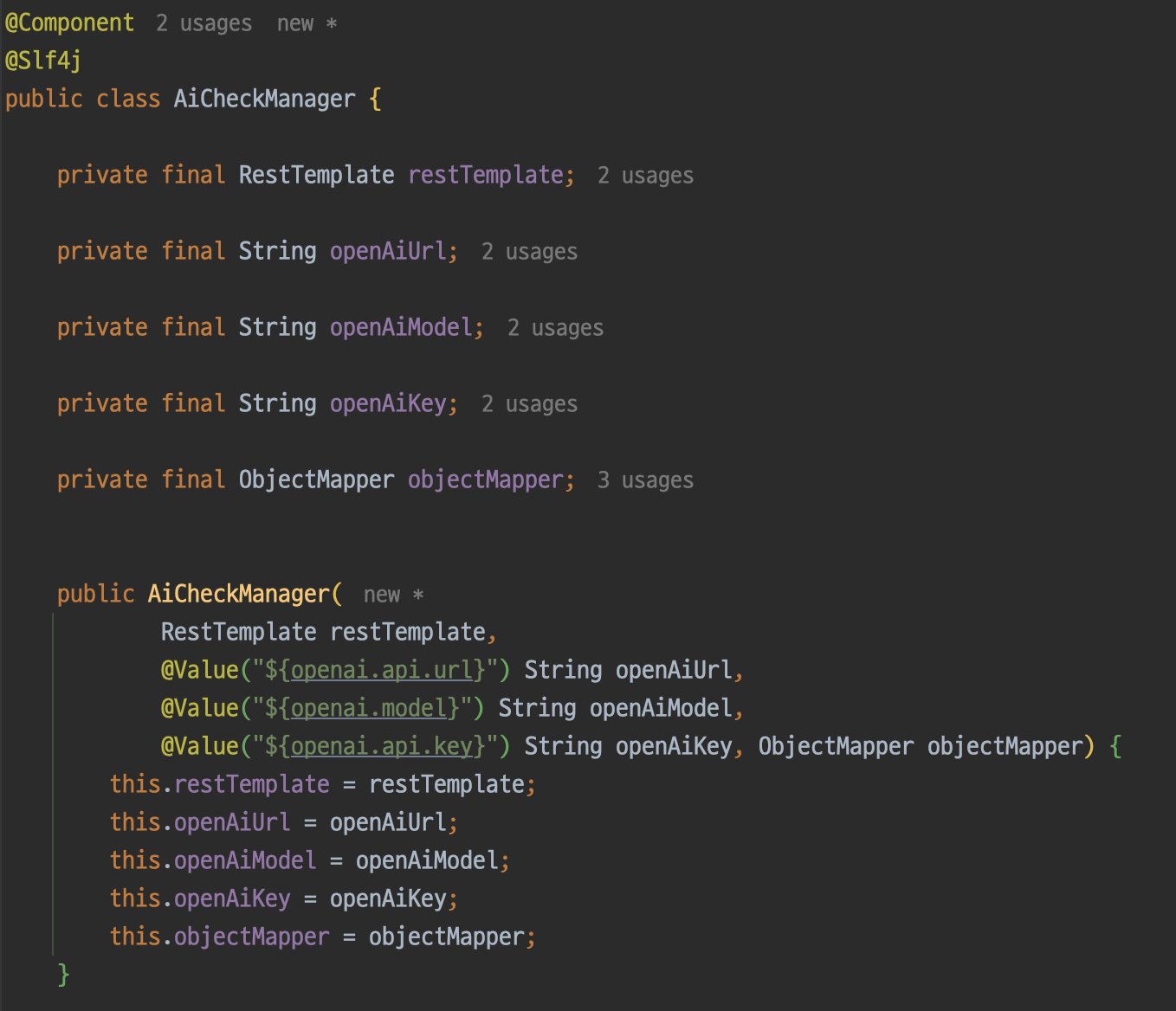
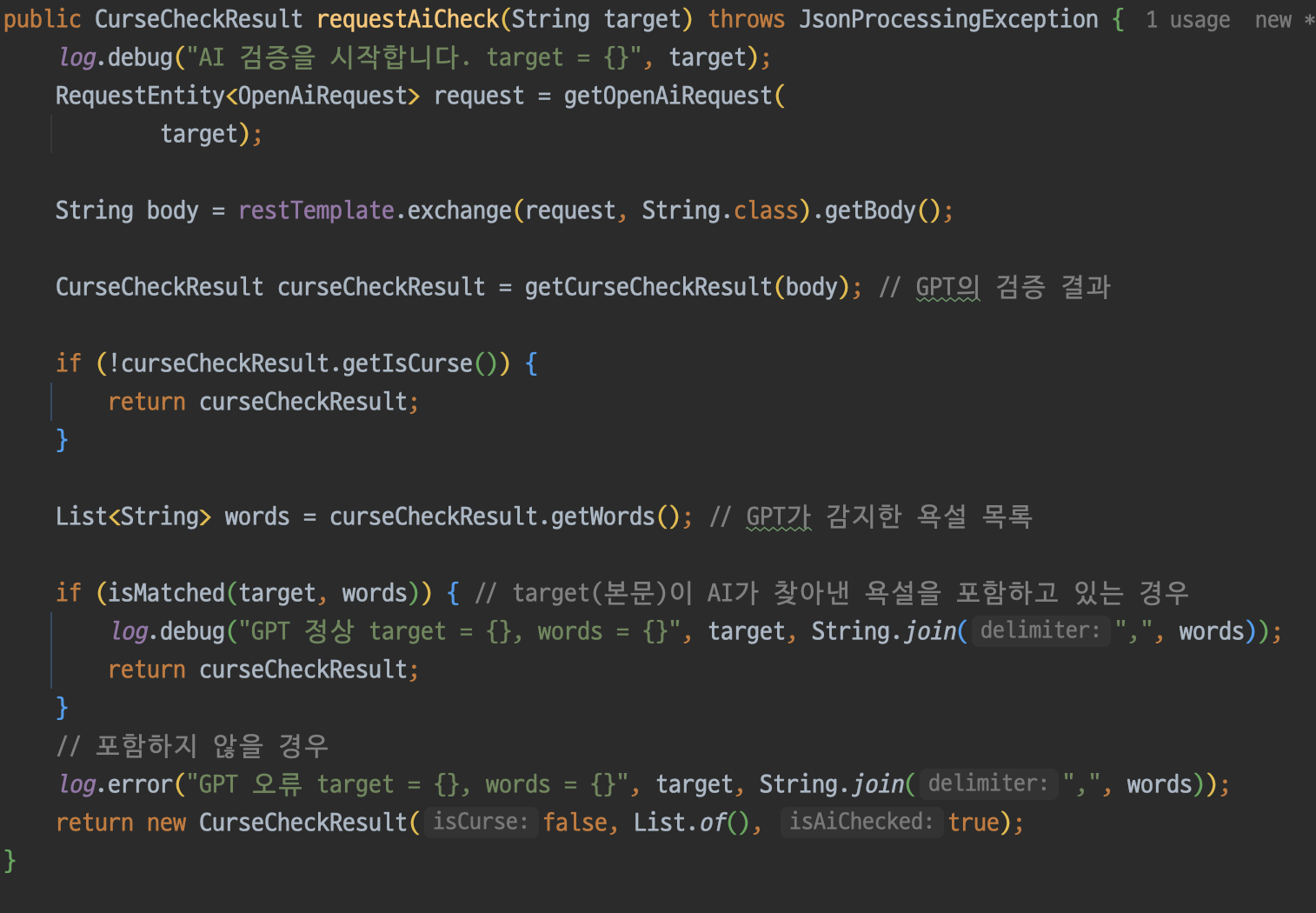
마지막으로 필터링 서비스에서 각자 컴포넌트에서 구현한 메서드들을 조합해주자. 리팩토링을 함께 진행해주니 가독성이 훨씬 좋아졌다.
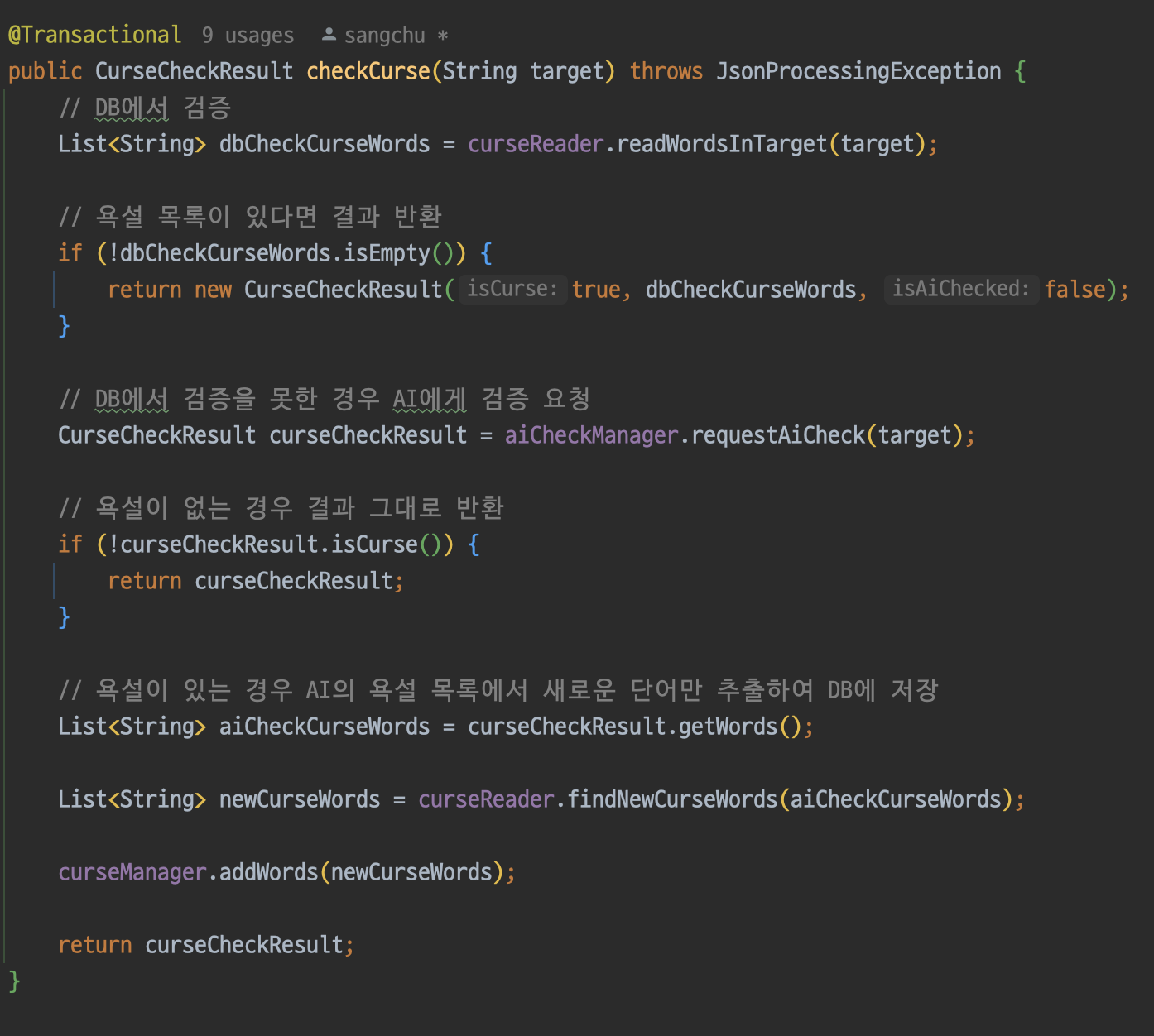
통합 테스트
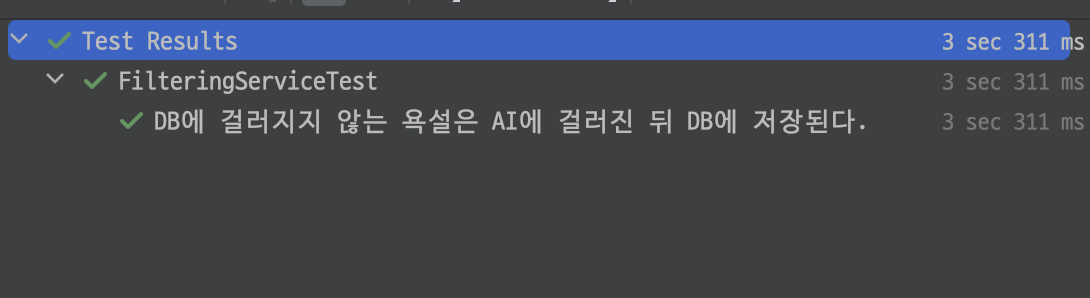
이제 통합테스트를 진행해보자. 우선 AI에 필터링된 욕설이 DB에 잘 저장되는지 확인해본다.
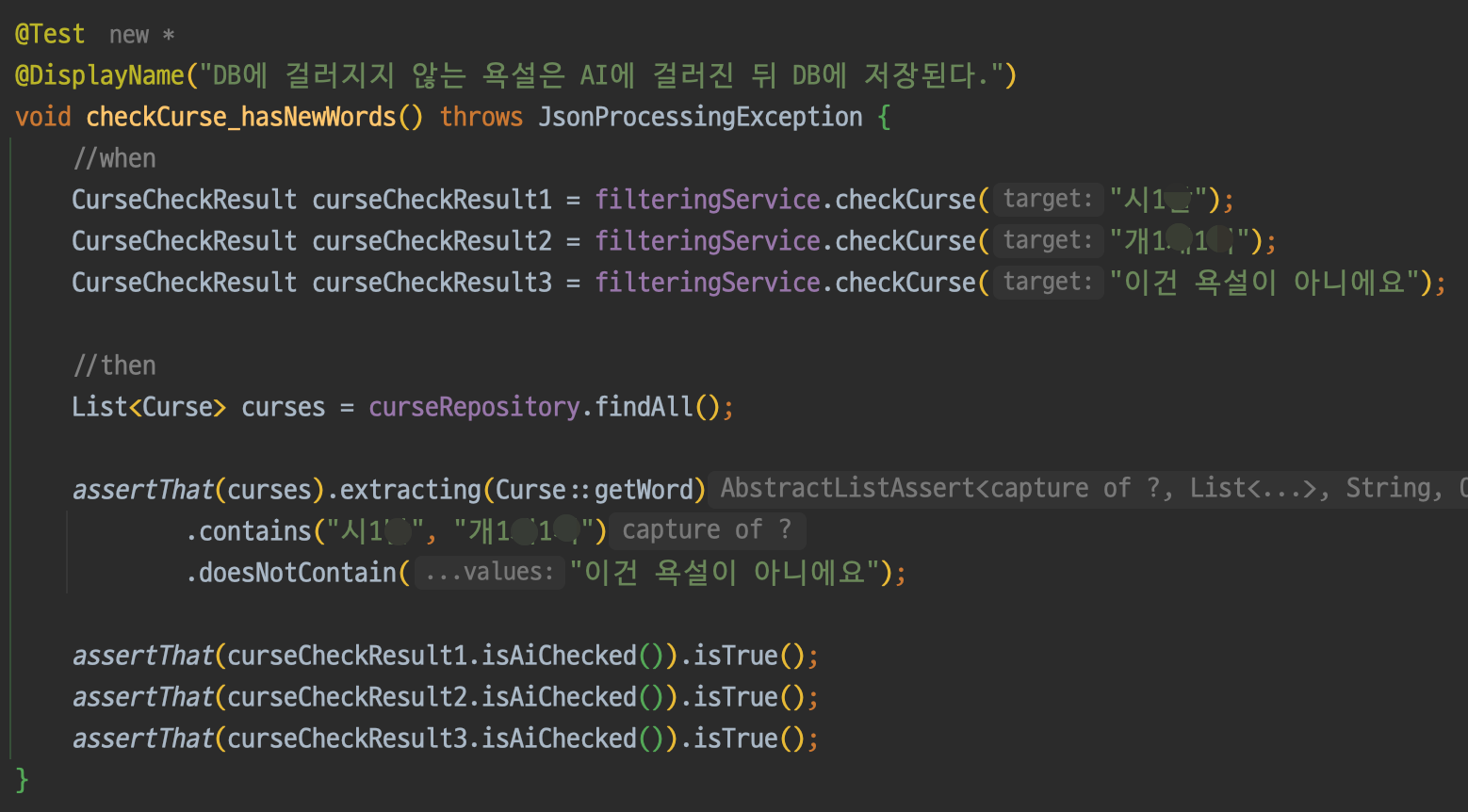
Ai에 의해 검증되고 DB에 저장이 잘 된 것을 확인할 수 있다.
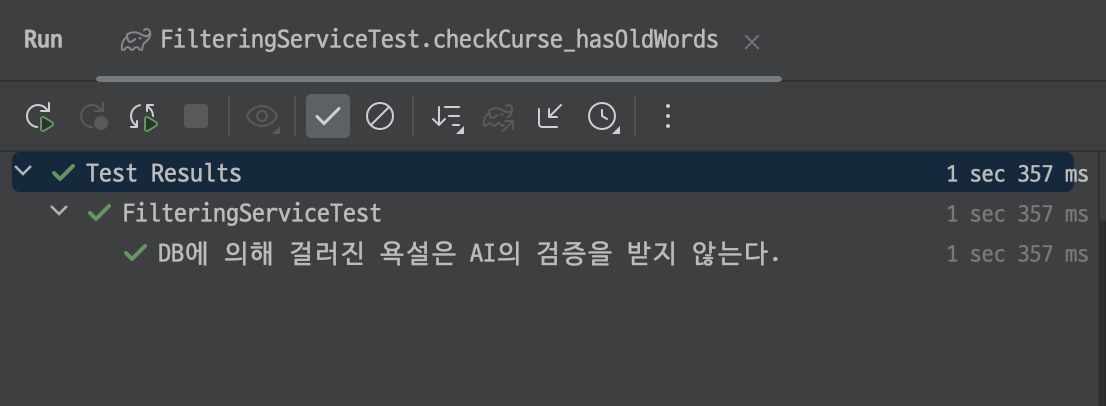
다음은 DB에 이미 욕설 데이터가 존재하는 경우이다.

욕설이 포함된 문장은 DB에서 검증되고 욕설이 미포함된 문장은 Ai에 의해 검증된 것을 확인할 수 있다!
또 다른 문제
순조롭게 진행되나 싶더니 역시나 문제가 터진다. 실제 서버에서 테스트를 진행해봤더니 필터링 후 DB에 욕설이 저장되지 않는다.
테스트에서 AI에 의해 검증된 욕설이 DB에 잘 저장되는 것을 분명히 확인했는데 왜 저장이 안된 것일까...?
.
.
하지만 생각보다 고민은 오래가지 않았다. 최근에 동시성 이슈를 해결하면서 트랜잭션 전파 문제로 고생한적이 있기 때문이다.
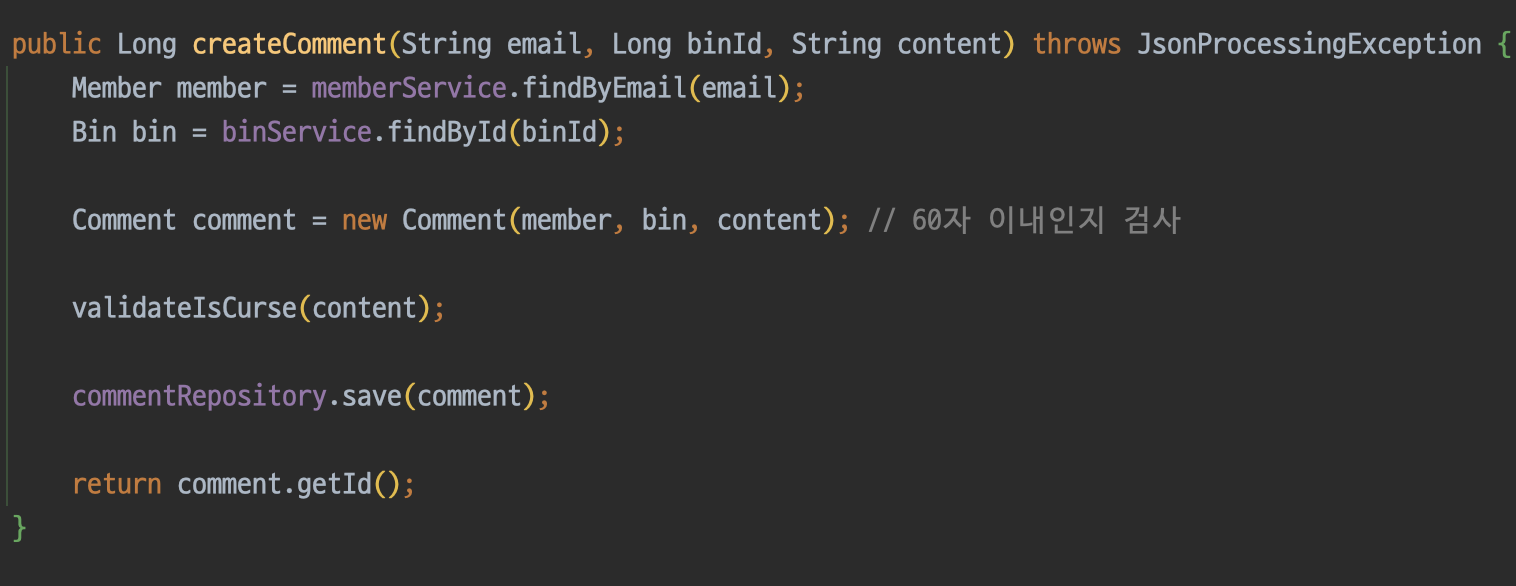
원인을 분석한 결과는 아래와 같다.
- 사용자가 댓글 작성을 요청한다.
- DB에 욕설이 없으므로 AI에게 검증을 요청한다.
- AI가 반환한 욕설 리스트를 DB에 저장한다.
- 욕설이 존재하므로 예외를 발생시킨다.
- 트랜잭션 내에서 언체크드 예외(RuntimeException)가 발생했으므로 자동으로 DB가 롤백된다.

이 문제를 해결하려면 어떻게 해야할까? 가장 먼저 떠오른 방법은 트랜잭션을 분리하는 것이다. 트랜잭션의 분리하는 방법은 여러가지가 있겠지만 나는 Propagation 옵션을 사용하기로 하였다.
아래와 같이 전파 옵션을 REQUIRES_NEW로 설정해주면 욕설 필터링을 수행할 때 기존 트랜잭션에 참여하지 않고 새롭게 트랜잭션을 생성한다.

그리고 웹에서 다시 한번 테스트를 진행해보자!
DB에 아직 해당 욕설이 없으므로 AI에게 검증을 요청하는 로직이 포함되어 확실히 시간이 오래 걸린다.

이번에는 확실히 DB에 저장이 잘 된다!

그리고 다시 시도를 해보면?
대성공이다! 응답 속도가 약 1초에서 30 밀리초로 감소하였으니 약 33배의 성능향상을 이루었다고 할 수 있다.

다음 과제
성능은 향상되었으나 현재 구조는 매번 DB에 접근해야 한다는 문제가 존재한다.
해당 문제를 해결하면 성능을 더 끌어올릴 수 있지 않을까?
다음 글에서는 해당 문제를 한번 해결해보자.
참고 문헌
https://dev.mysql.com/doc/refman/8.4/en/index-btree-hash.html
https://dev.mysql.com/doc/refman/8.4/en/innodb-fulltext-index.html
https://liltdevs.tistory.com/199
https://velog.io/@jhkim31/JPA-FULLTEXT-INDEX-%EC%A0%81%EC%9A%A9
