Comparing Two Population Means (1)
9.1 Introduction
Two Population Distributions
이전까지는 하나의 모집단에 대해 다뤘다.
그러나 두 개의 모집단을 비교하는 경우도 있을 것이다.
예를들면 한국 학생들의 평균 키가 첫 번째 모집단이고, 미국 학생들의 평균 키가 두 번째 모집단으로 설정할 수 있다.
이렇게 설정했을 때, 일반적으로 우린 두 모집단이 다를 것이라는 가정에 관심이 있다.
한 접근법으로 두 모집단의 평균을 비교하는 방법이 있고, 두 모집단의 평균이 다르다면 두 모집단은 다르다.
Two Population Means
우리는 두 모집단의 평균을 비교한다.
두 모집단의 차이가 0이면 같은 것이고, 0이 아니면 다를 것이다.
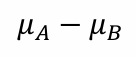
A모집단의 평균이 더 크다면 모집단 평균의 차는 양수, 같다면 0, 작다면 음수다.
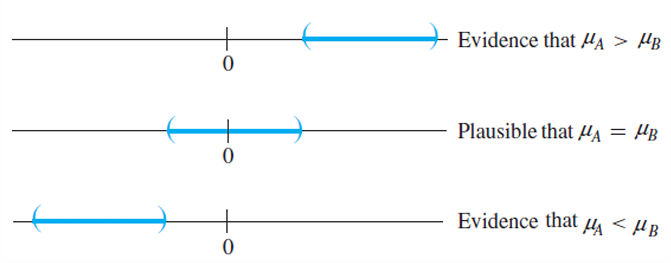
결국 우리가 관심이 있는 것은 이 신뢰구간에 0이 포함되는지의 여부이다.
Paired Samples vs. Independent Samples
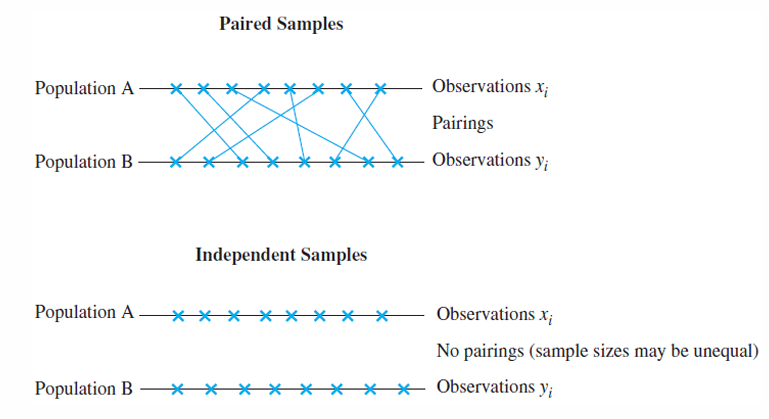
Paired samples는 외부 환경 요인으로 인한 변동성을 낮춘다.
예를 들면 신약과 기존약을 같은 환자에게 두 모집단(Day1, Day2) 별로 투여한다.
Independent samples는 두 모집단(환자그룹A, 환자그룹B)이 각각 신약과 기존약을 투여한다. 그러나 기존약을 투여하는 모집단이 약에 대한 반응성이 더 좋은 집단이라면 다른 결과가 나올 것이다.
9.2 Analysis of Paired Samples
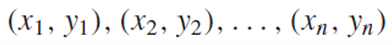
각각의 pair의 차이를 알고 싶으므로 새로운 두 샘플의 차이를 새로운 샘플로 만든다.
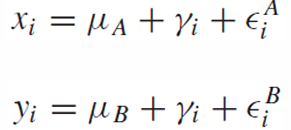
같은 i 번째 subject에 투여하므로 subject effect 변수는 동일하여 소거되고, error term은 A와 B의 차로 새로운 error term이 생긴다.
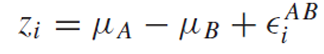
A의 error term과 B의 error term은 모두 평균이 0인 관측치이므로 새로운 error term도 평균이 0인 관측치가 되고 Z의 error term이 된다.
subject effect도 소거됐으므로 A와 B의 영향이 없는 새로운 샘플 집단으로 볼 수 있다.
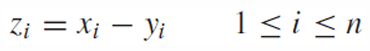
새롭게 만든 샘플의 평균은 이전에 봤듯이 다음과 같다.
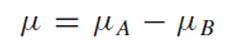
가설검증을 위한 귀무가설과 대립가설을 하나의 모집단처럼 구할 수 있게 됐다.
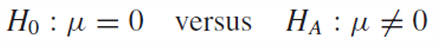
이후의 가설검증은 하나의 모집단에 대한 가설검증과 같다.
