Probability and Statistics for Engineers and Scientists (Review)
1.Inferences on a Population Mean (1)
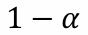
신뢰구간(Confidence Interval) : 가장 그럴듯한 값들을 포함하는 구간Confidence Level : 신뢰구간을 결정하는 요소로, 전형적으로 90%, 95%, 99%의 confidence level을 가진다주로 위와 같이 표현하며 a는 confidenc
2.Inferences on a Population Mean (2)
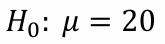
가설검증은 명제나 가설에 대해 타당성(plausibility)을 평가할 수 있게 해준다.Null hypothesis : 귀무가설, 타당성을 평가하는 대상으로 명제 혹은 가설이다.Alternative hypothesis : 대립가설, 귀무가설을 기각했을 때 채택하는, 타
3.Comparing Two Population Means (1)
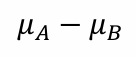
이전까지는 하나의 모집단에 대해 다뤘다.그러나 두 개의 모집단을 비교하는 경우도 있을 것이다.예를들면 한국 학생들의 평균 키가 첫 번째 모집단이고, 미국 학생들의 평균 키가 두 번째 모집단으로 설정할 수 있다.이렇게 설정했을 때, 일반적으로 우린 두 모집단이 다를 것이
4.Comparing Two Population Means (2)
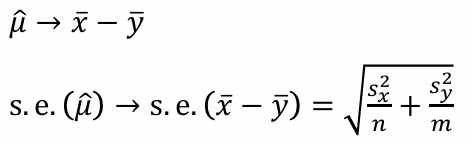
Paired samples은 두 모집단의 표본 개수가 같으므로 비교하는 것이 쉬웠지만 unpaired인 independent samples은 꽤 복잡하다.우리가 구하고자 하는 것은 이 point estimate의 standard error가 필요하다.이는 각 분산을 더
5.Discrete Data Analysis (1)
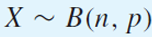
Binomial 분포를 따르는 성공 횟수의 랜덤 변수 X가 있다.이때 성공의 비율은 전체 횟수 n으로 성공 횟수 X를 나눈 Y로 볼 수 있다.이를 대입하면 Y의 평균과 분산은 다음과 같다.n이 커질수록 Y의 분산이 작아져서, Y는 실제 성공확률인 p에 매우 가까워진다.
6.Discrete Data Analysis (2)
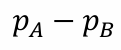
이전에 두 모집단의 표본 평균의 차로 신뢰구간을 구했던 것처럼, 확률의 차이를 이용할 수 있다.이에 해당하는 two-sided 신뢰구간은 다음과 같다.또한 정규분포로 근사하기 위해 npa, n(1-pa), mpb, m(l-pb) > 5 의 조건은 동일하다.이는 x, n
7.Discrete Data Analysis (3)
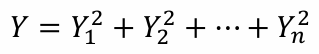
지금까지 binomial distribution처럼 성공과 실패, 두 개의 category를 검증했다면 이제는 3개 이상의 category를 살펴볼 것이다.표준 정규 분포를 따르는 독립적인 랜덤 변수 Yi 제곱의 합으로 표현할 수 있고이것도 자유도가 n인 chi-squ