Comparing Two Population Means (2)
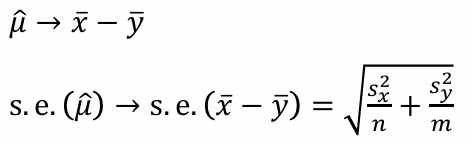
9.3 Analysis of Independent Samples
Paired samples은 두 모집단의 표본 개수가 같으므로 비교하는 것이 쉬웠지만 unpaired인 independent samples은 꽤 복잡하다.

우리가 구하고자 하는 것은
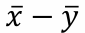
이 point estimate의 standard error가 필요하다.
이는 각 분산을 더한 것에 루트를 씌워주면 된다.
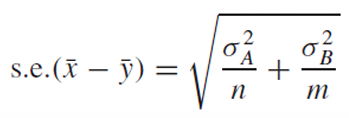
그러나 모집단의 분산을 포함하므로 이를 표본 분산으로 교체한다.
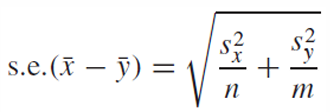
우리는 하나의 모집단을 추정하기 위해 표본 평균, standard error, critical point를 필요로 했다.
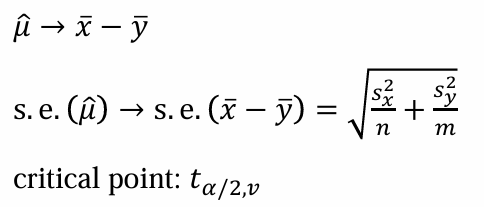
그러나 두 모집단의 표본의 개수가 다를 수 있으므로 자유도는 다음과 같이 구해야 한다.
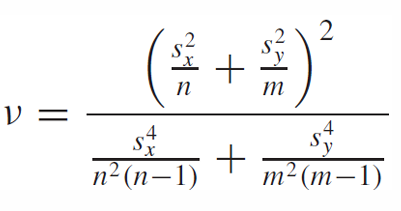
소수점은 버리고 정수를 사용한다.
Confidence Interval of Independent Samples
새로운 신뢰구간은 다음과 같이 구할 수 있다.
two-sided interval
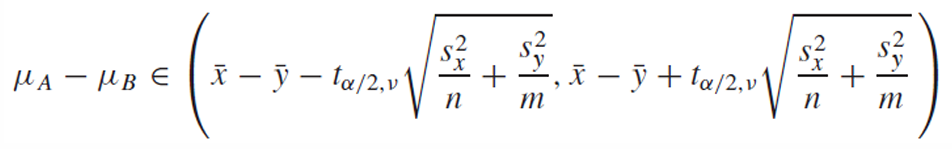
one-sided interval
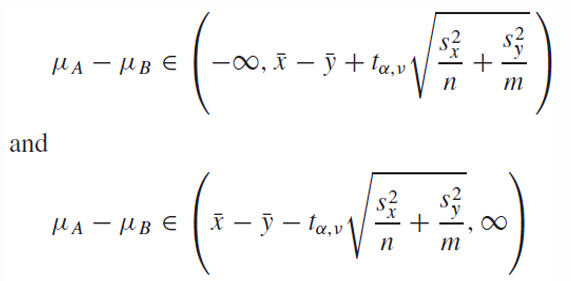
Hypothesis Test of Independent Samples
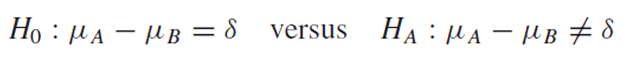
가설이 위와 같을 때 t-statistic은
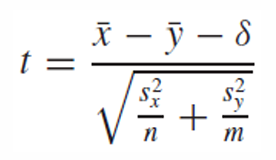
보통 둘의 차이 유무를 알기 위해 0을 우항으로 두므로
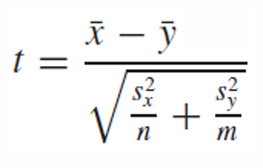
결국 우리는 가설검증을 위해 t-statistic, 신뢰구간, critical point를 알기 때문에 하나의 모집단에 대한 추정과 동일하게 가설검증을 할 수 있다.
Independent Samples : Pooled Variance
만약 두 모집단의 분산이 같다고 가정하면 표본 분산을 다음과 같이 추정할 수 있다.
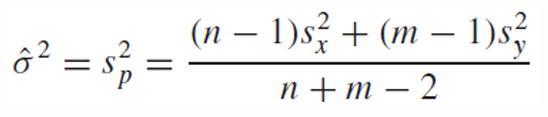
standard error에서도 두 모집단의 분산이 같으므로 바깥으로 묶어서 빼주고
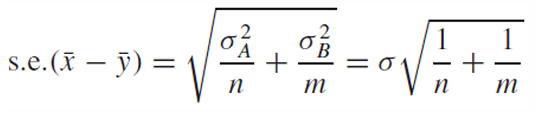
새롭게 추정한 표본 분산으로 다음과 같이 표현한다.
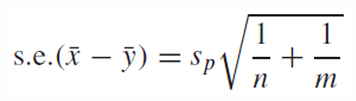
이때 자유도는 n + m - 2로 critical point를 계산한다.
Confidence interval of pooled variance
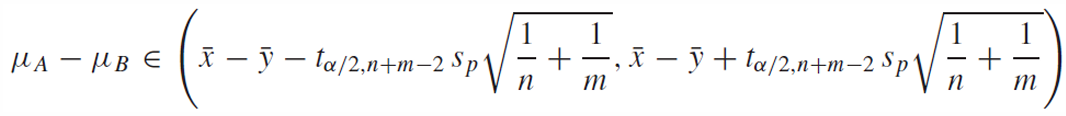
1 − 𝛼의 유의수준에서 신뢰구간은 위처럼 표현할 수 있다.
일반적으로는 pooled variance보다는 기존의 independent samples의 방법이 더 안전하여 이를 사용한다.
그러나 두 모집단의 분산이 같다는 것을 안다면 pooled variance는 매우 좋은 선택지가 될 수 있다.
Two Sample z-Procedures
두 모집단의 분산을 알고 있다면 t-interval 대신 standard normal distribution을 이용하면 된다.
