Discrete Data Analysis (2)
10.2 Comparing Two Population Proportions
이전에 두 모집단의 표본 평균의 차로 신뢰구간을 구했던 것처럼, 확률의 차이를 이용할 수 있다.
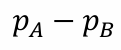
이에 해당하는 two-sided 신뢰구간은 다음과 같다.
또한 정규분포로 근사하기 위해 npa, n(1-pa), mpb, m(l-pb) > 5 의 조건은 동일하다.
이는 x, n-x, y, m-y > 5와 같다.
pb의 sample size를 m, 성공횟수를 y라고 설정하면
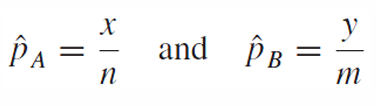
point estimate은
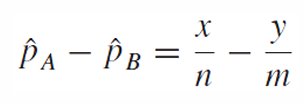
우리는 pa-pb의 standard error를 알아야 한다.
일단 두 분산은
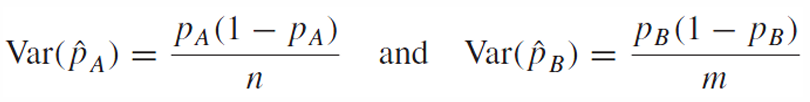
서로 독립이므로
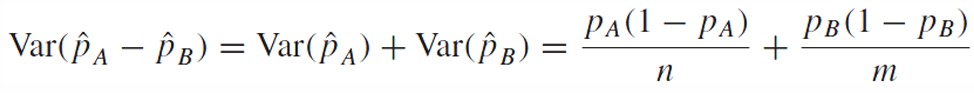
따라서 point estimate의 standard error는
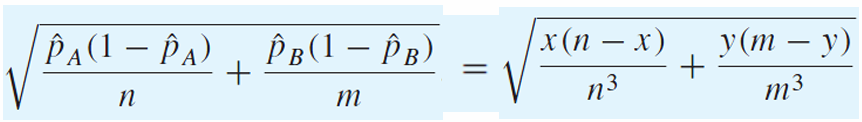
z-statistic
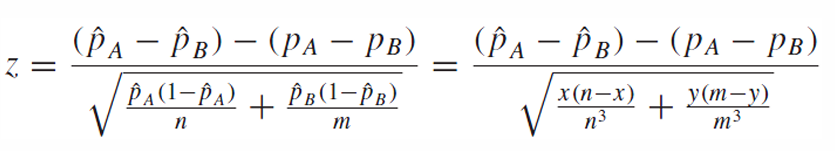
Two-Sided Confidence Interval
1 − 𝛼 의 유의수준에서 신뢰구간은
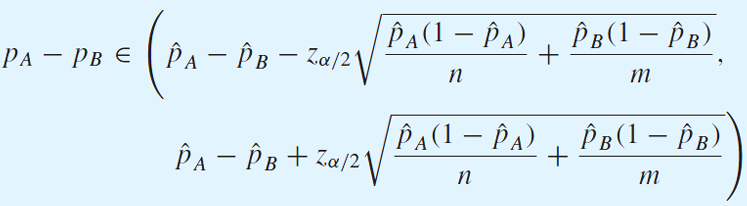
pa hat과 pb hat을 치환하면
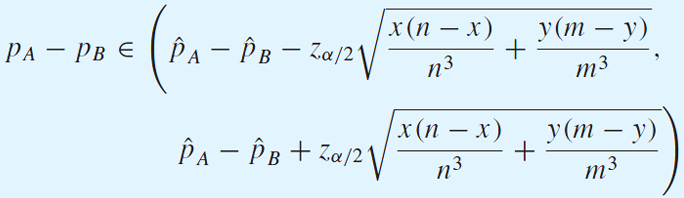
One-Sided Confidence Interval
upper bound
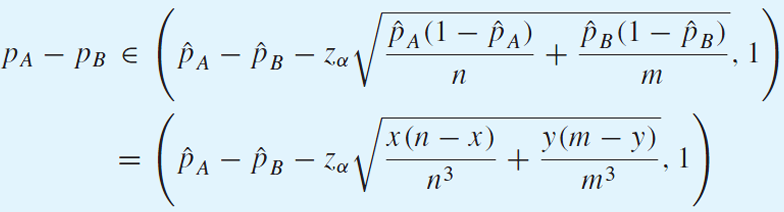
lower bound
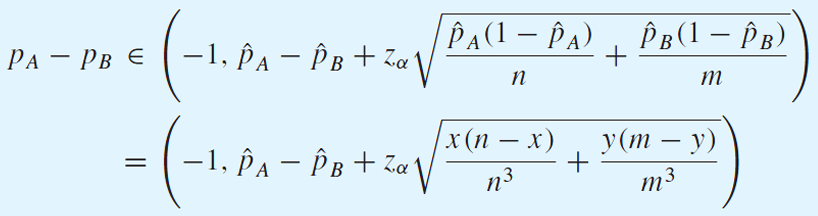
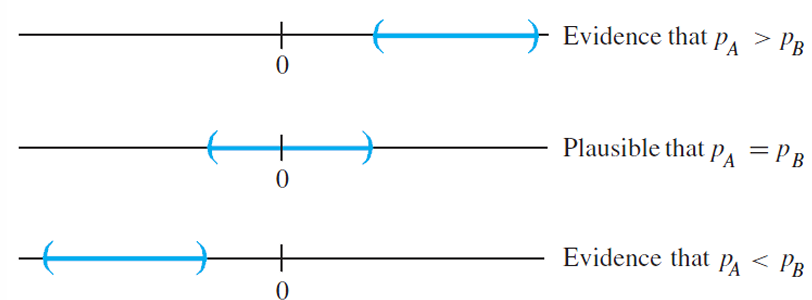
0 <= pa, pb <= 1 이므로 -1 <= pa - pb <= 1 이다.
Two-Sided Hypothesis Testing
만약 pa = pb라면 pooled estimate이 적합하다.
두 모집단의 pa와 pb가 같다고 가정하면, 하나의 표본 확률로 pooled variance처럼 pooled estimate를 추정할 수 있다.
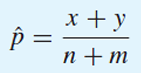
그때의 z-statistic은
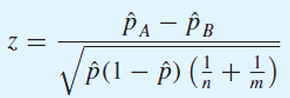
One-Sided Hyothesis Testing
critical point, 신뢰구간, z-statistic을 모두 구할 수 있으므로 나머지는 기존 가설검증과 동일하다.

Context-aware AI researcher at the intersection of CV, HCI, and AR/VR