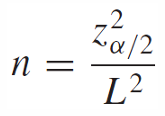Discrete Data Analysis (1)
10.1 Inferences on a Population Proportion
Proportion of Success in Bernoulli Trials
Binomial 분포를 따르는 성공 횟수의 랜덤 변수 X가 있다.
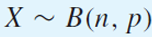
이때 성공의 비율은 전체 횟수 n으로 성공 횟수 X를 나눈 Y로 볼 수 있다.
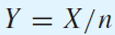
이를 대입하면 Y의 평균과 분산은 다음과 같다.

n이 커질수록 Y의 분산이 작아져서, Y는 실제 성공확률인 p에 매우 가까워진다.
Normal approximation
discrete한 값들을 continuous하게 보정하는 연속합보정을 통해 다음과 같이 근사할 수 있다.
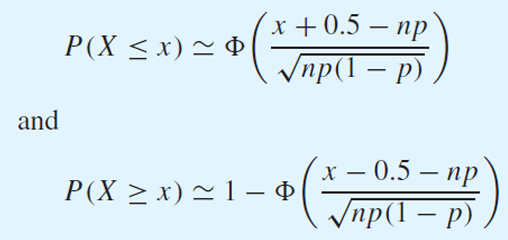
하나의 막대로 표현된 P(X=2)가 있을 때 막대의 중앙이 2이므로 이를 P(1.5 < X < 2.5)로 근사하는 원리이다.
Population Proportion
두 카테고리의 확률
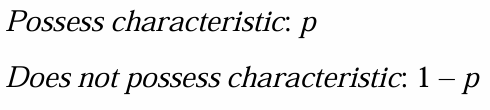
두 카테고리의 관측수
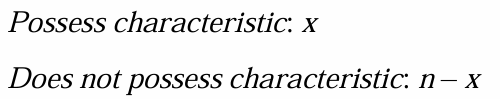
우리가 p를 알지 못한다면 다음과 같이 추정할 수 있다.
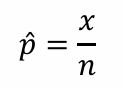
이를 대입하여 평균과 분산을 구하면
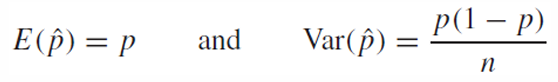
때문에 충분히 큰 n에 대해 표본의 비율은 다음과 같은 분포를 따른다.
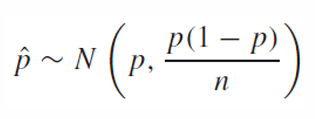
여기서 중요한 점은 np와 n(1 - p)가 5보다 커야 이항분포를 정규분포로 근사할 수 있다.
성공확률 p가 중간에 가까워지고 n이 커질수록 정규분포에 비슷해지기 때문이다.
결과적으로 성공횟수와 실패횟수가 5보다 커야된다.
x, n - x > 5
이를 정규화하면
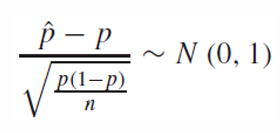
Two-Sided Interval
위에서 표준 정규 분포로 정규화했기 때문에 이를 대입하면
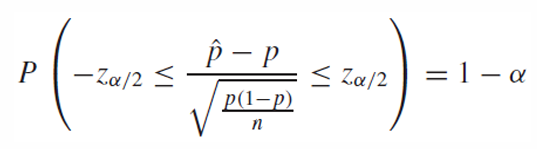
결국 p에 대한 식으로 정리하여, 유의수준 1 - a에서 다음과 같은 신뢰구간을 구할 수 있다.
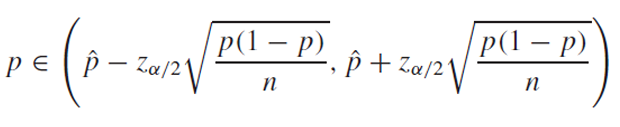
critical point와 standard error를 곱하여 더하거나 빼는데, standard error의 p의 값을 우리는 알지 못한다.
때문에 이를 p hat으로 추정하여 나타낸다.
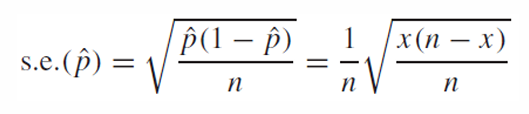
결국 최종적으로 우리가 구할 수 있는 신뢰구간은 다음과 같다.
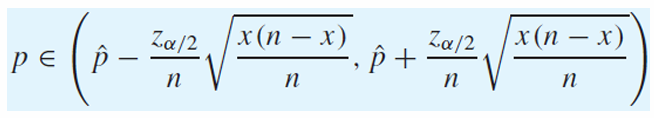
One-Sided Interval
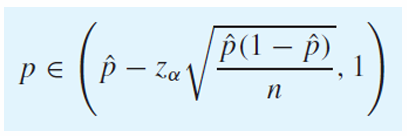
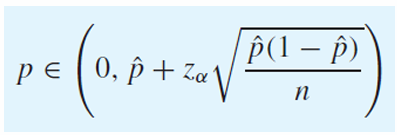
p는 확률이므로 upper bound와 lower bound는 각각 1과 0이 된다.
Two-Sided Hypothesis Testing
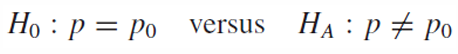
z-statistic
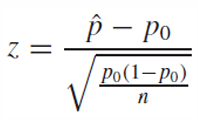
이때 귀무가설이 참이라고 가정했을 때의 값인 p0가 평균과 분산에 들어간다.
-> z-statistic을 구할 때는 p0를 대입해야 귀무가설이 참이라는 가정 하에서 z-statistic이 어떤 분포를 따르는지를 알고 p-value를 계산할 수 있다. critical point와 귀무가설을 검증하기 위해 비교하려면 귀무가설이 참이라고 가정했을 때의 p0를 대입해야 기각여부를 알 수 있는 것이다.
-> 신뢰구간을 구할 때는 귀무가설이 아니라 표본에서 관측된 값을 기준으로 계산하기 때문에 p hat을 대입하고, p0가 이 신뢰구간에 포함되는지의 여부를 확인하여 기각여부를 알 수 있는 것이다.
p hat을 x/n으로 대입하여 정리하면
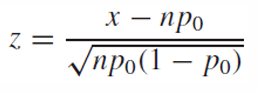
p-value
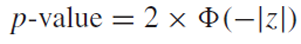
continuity correction(연속합보정)
우리는 연속합보정을 통해 더욱 정확하게 근사할 수 있다.
만약 분자가 x - np0 > 0.5 라면
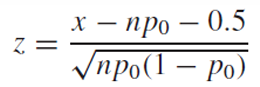
x - np0 < -0.5라면
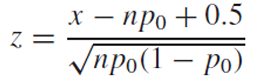
주의할 점은 p hat을 치환한 이후의 식에서 연속합보정을 해야 한다.
sample size n이 커질수록 연속합보정은 의미가 적어진다.
z-statistic의 절댓값이 critical point보다 작거나 같다면 귀무가설을 채택하고, 크다면 귀무가설을 기각한다.
One-Sided Hypothesis Testing
H0 : p >= p0
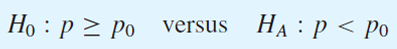
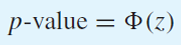
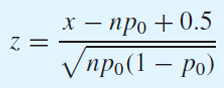
H0 : p < p0

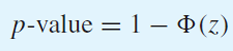
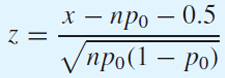
Sample Size Calculation
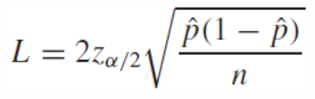
주어진 신뢰구간의 길이에 따른 필요한 sample size n을 구하는 식으로 정리할 수 있다.
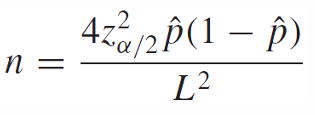
여기서 p(1 - p)의 최댓값은 1/4이다.
따라서 필요한 sample size n의 최악의 경우를 보장하는 최솟값은 다음과 같다.