OS : CentOS 7.9 64bit
MySQL : 8.0.27 - commercial
Node : 3대
Orchestrator Server 1대, Master Server 1대, Slave Server 1대MySQL Node 설정 정보
- server-id = 1(2)
- log-bin = /mysql_data/log/mysql-bin
- binlog_format = row
- max_binlog_size = 1G
- gtid-mode=ON
- enforce-gtid-consistency=ON
Orchestrator는 GTID 사용을 권장합니다. (Binlog Position 사용 시, Pseudo GTID를 사용합니다.)
Pseudo GTID : https://github.com/openark/orchestrator/blob/master/docs/pseudo-gtid.md
호스트 정보
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.64.23.240 orche_master
10.64.23.241 orche_slave
10.64.23.250 orche_manager

Orchestrator?
MySQL/MariaDB의, 시각화 기능을 지원하는 HA 솔루션입니다. MHA와는 다르게 HTTP API 및 웹 인터페이스를 제공합니다.
공식 GIthub URL : https://github.com/openark/orchestrator
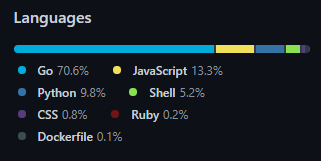
Orchestrator의 개발 언어 분포도는 아래와 같습니다. (주로 구글에서 만든 Go 언어를 사용하고 있습니다.)
MySQL 유저 생성
(DB 2대가 GTID Replication 된 환경이 필요합니다)
Master와 Slave 모든 DB에서 Orchestrator가 접속하여 컨트롤 및 모니터링 용도를 위한 유저를 생성해야 합니다.
--- 필수 구성
mysql> CREATE USER 'orchestrator'@'%' IDENTIFIED BY 'password';
mysql> GRANT SUPER, PROCESS, REPLICATION SLAVE, RELOAD ON . TO 'orchestrator'@'%';
mysql> GRANT SELECT ON mysql.slave_master_info TO 'orchestrator'@'%';
--- pesudo_gtid 사용 시
mysql> GRANT DROP ON pseudo_gtid.* to 'orchestrator'@'%';
--- NDB Cluster 사용 시
mysql> GRANT SELECT ON ndbinfo.processes TO 'orchestrator'@'%';
Orchestrator 스키마 생성 [Orchestrator Manager Server]
Orchestrator 에서 DB 구성 정보를 저장하고 관리하는데 사용하는 스키마가 필요합니다.
orchestrator 스키마 테이블 종류
mysql> show tables;
+--------------------------------------------+
| Tables_in_orchestrator |
+--------------------------------------------+
| access_token |
| active_node |
| agent_seed |
| agent_seed_state |
| async_request |
| audit |
| blocked_topology_recovery |
| candidate_database_instance |
| cluster_alias |
| cluster_alias_override |
| cluster_domain_name |
| cluster_injected_pseudo_gtid |
| database_instance |
| database_instance_analysis_changelog |
| database_instance_binlog_files_history |
| database_instance_coordinates_history |
| database_instance_downtime |
| database_instance_last_analysis |
| database_instance_long_running_queries |
| database_instance_maintenance |
| database_instance_peer_analysis |
| database_instance_pool |
| database_instance_recent_relaylog_history |
| database_instance_stale_binlog_coordinates |
| database_instance_tags |
| database_instance_tls |
| database_instance_topology_history |
| global_recovery_disable |
| host_agent |
| host_attributes |
| hostname_ips |
| hostname_resolve |
| hostname_resolve_history |
| hostname_unresolve |
| hostname_unresolve_history |
| kv_store |
| master_position_equivalence |
| node_health |
| node_health_history |
| orchestrator_db_deployments |
| orchestrator_metadata |
| raft_log |
| raft_snapshot |
| raft_store |
| topology_failure_detection |
| topology_recovery |
| topology_recovery_steps |
+--------------------------------------------+
Orchestrator 전용 유저와 스키마를 생성 후, 권한을 부여합니다.
mysql> CREATE USER 'orchestrator'@'127.0.0.1' IDENTIFIED BY 'password';
mysql> CREATE DATABASE IF NOT EXISTS orchestrator;
mysql> GRANT ALL PRIVILEGES ON orchestrator.* TO 'orchestrator'@'%';
Orchestrator 패키지 설치 및 구성
.rpm, .tar.gz, .deb 형식의 Orchestrator를 다운 받을 수 있습니다. Orchestrator 패키지 설치
설치 시, 샘플 conf 파일이 주어지는데, 이를 토대로 작성할 수 있습니다.
#cd /usr/local/orchestrator
#cp orchestrator-sample.conf.json orchestrator.conf.json
#vi orchestrator.conf.json
아래 값을 환경에 맞게 수정합니다.
Bankend MySQL server에 접속하기 위한 설정 정보입니다.
"MySQLTopologyUser": "orchestrator",
"MySQLTopologyPassword": "123",
"MySQLOrchestratorHost": "127.0.0.1",
"MySQLOrchestratorPort": 3306,
"MySQLOrchestratorDatabase": "orchestrator",
"MySQLOrchestratorUser": "orchestrator",
"MySQLOrchestratorPassword": "123",
"DefaultInstancePort": 3306,
Orchestrator는 기본적으로 조회되는 (/etc/hosts)에서 MySQL DB로 접속 하는 방식을 사용합니다. (Host discover)
소개에서 기술되어있는 hosts의 alias를 따라 접속할 수 있습니다.
다만, 실 사용 시 많은 서버를 /etc/hosts 에 등록하기 어려울 수 있으므로 IP discover 방식을 사용할 수도 있습니다.
아래와 같이 변경합니다.
"HostnameResolveMethod": "none",
"MySQLHostnameResolveMethod": "",
Orchestrator 구동 및 테스트
1) systemd service 사용
#systemctl start orchestrator
2) orchestrator 실행 사용
#cd /usr/local/orchestrator
#./orchestrator http
2번 방식으로 실행 시, foreground 형태로 실행되며, 현재 Orchestrator 서버의 자세한 정보를 볼 수 있습니다.
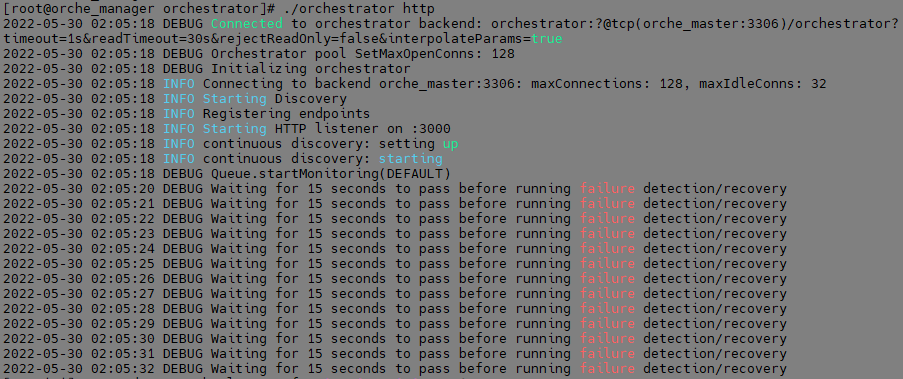
기본 포트를 변경하지 않았다면 ("ListenAddress" ":3000") 3000번대 포트로 접속할 수 있습니다.
Browser : http://ip:3000
접속 시 로그
웹 브라우저
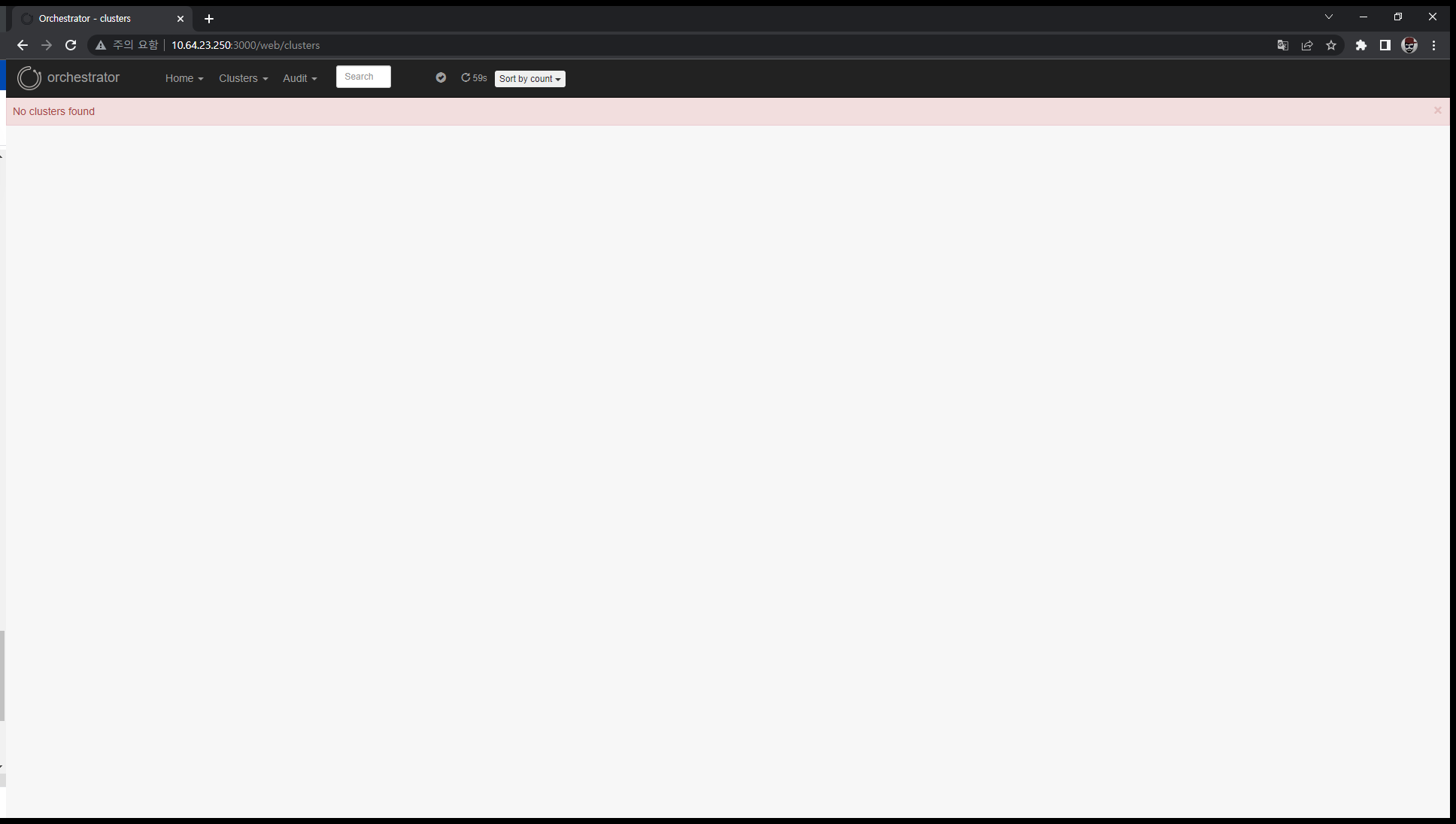
초기 화면에는 아무런 토폴로지가 나타나지 않습니다.
상단 메뉴의 Clusters → Discover 이동 후, Master의 IP와 PORT 기입하여 탐색합니다.
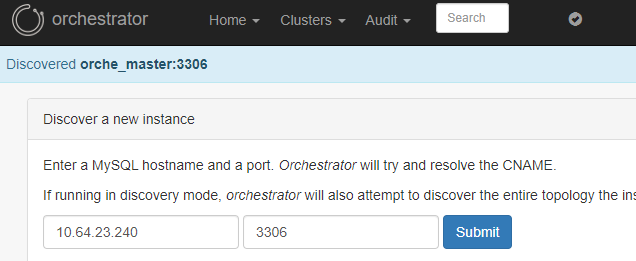
다시 Clusters → Dashboard에 접속하면, 하나의 목록이 나타납니다.
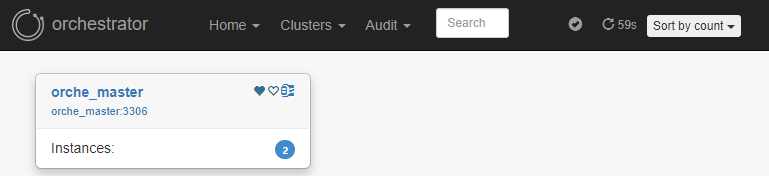
클릭 시, 현재 구성 토폴로지를 실시간으로 볼 수 있습니다
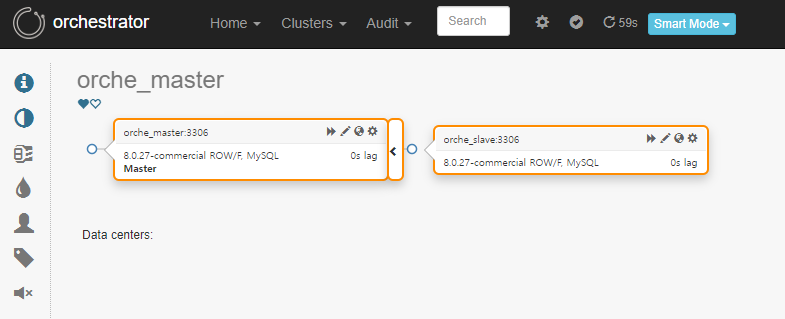
Orchestrator Manual Take-Over
Slave server를 Master Server 가장 좌측 바운더리에 드래그 하여, 수동 Take-Over 할 수 있습니다. (Manual Take-Over)
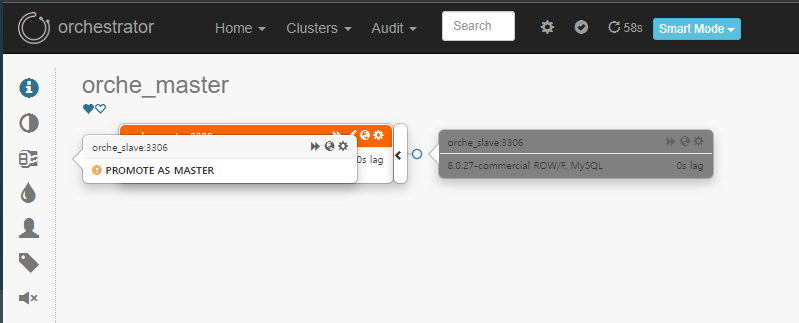
잠시 에러 화면이 보이는데, 이것은 Clusters → Discovery 당시 Master 호스트를 등록하여 발생한 에러입니다. 다시 Clusters → Dashboard를 눌러주어 페이지를 갱신합니다.
→ orche_master가 orche_slave로 변경되었습니다.
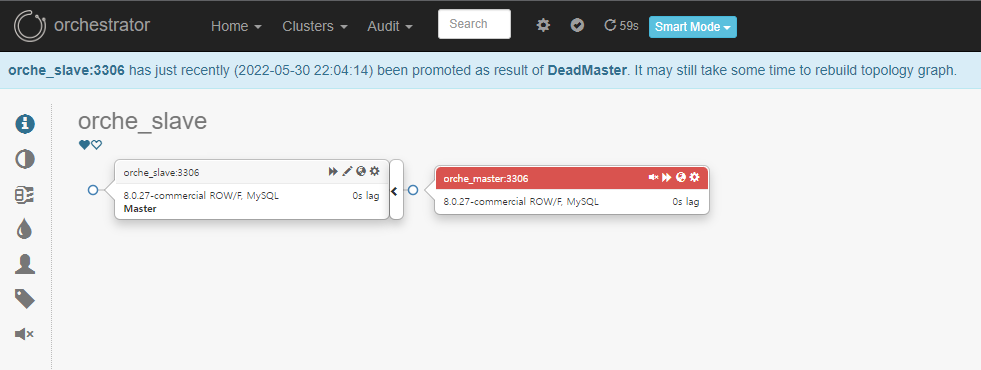
Take-Over 하였다고 하여 기존의 Master가 Slave가 된 것이 아닙니다. 수동을 Master Server 서버를 눌러 Start Replication 합니다.
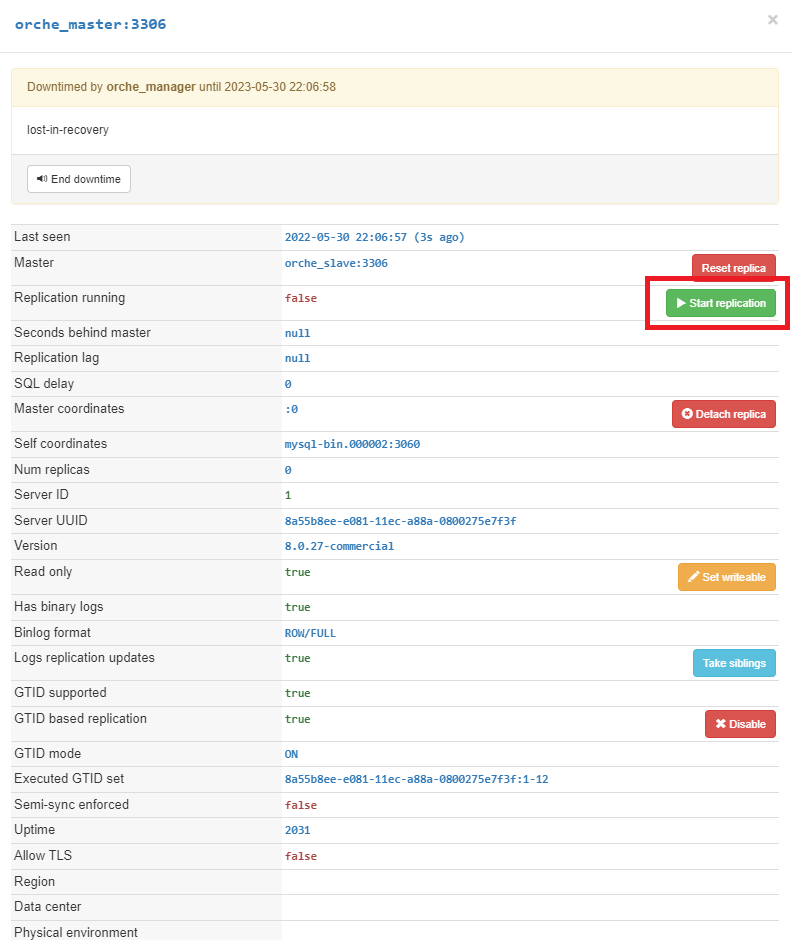
기존 Master가 Slave로 Take-Over 되었습니다. 원복은 해당 절차를 다시 반복합니다.
Orchestrator Fail-Over
구성된 토폴로지에서, Master Server를 종료 해보도록 하겠습니다.
#mysqladmin -uroto -p shutdown
2022-05-31T04:18:37.496172Z mysqld_safe mysqld from pid file /mysql_data/data/orche_master.pid ended
[1]- Done mysqld_safe --user=mysql (wd: /mysql_data/log)
#ps -ef | grep mysqld
root 23719 18327 0 00:18 pts/0 00:00:00 grep --color=auto mysqld
Orchestrator Manager에서 지속적으로 ERROR 메시지가 출력됨을 볼 수 있습니다.
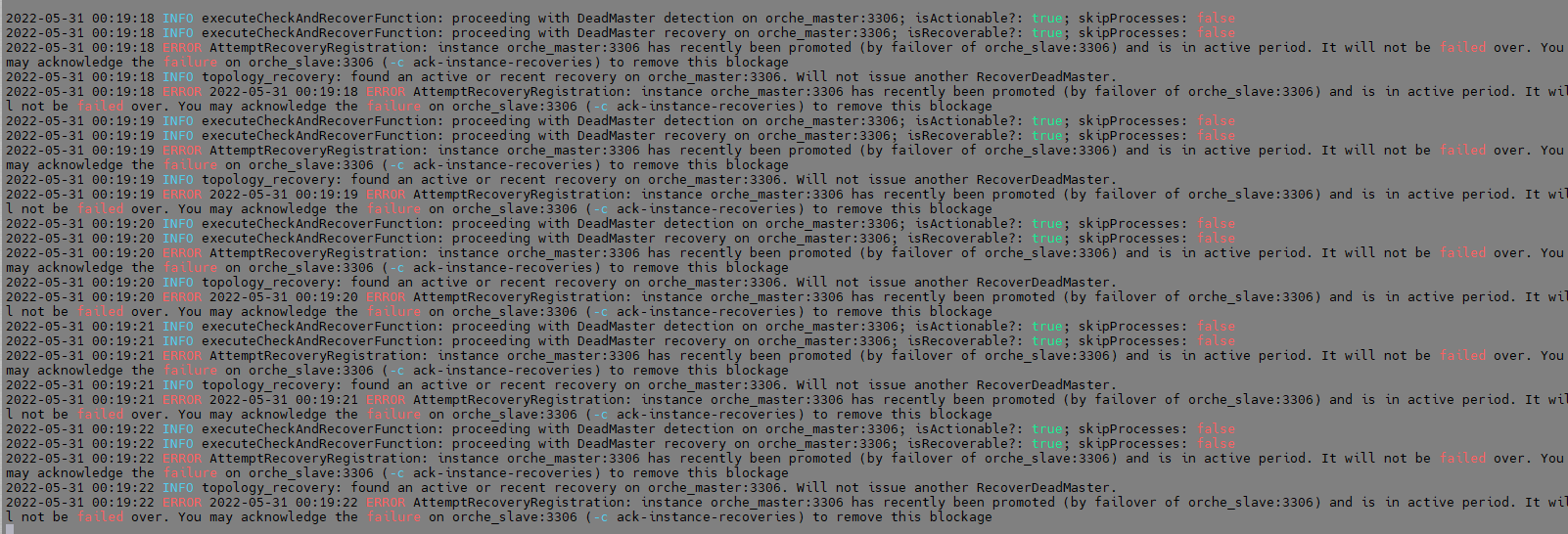
토폴로지의 오른쪽 느낌표 버튼을 클릭하여 각 노드의 에러 내역을 확인할 수 있습니다, 또한 conf 파일에서 설정한 log에서도 Failure가 감지됩니다. (Default : /tmp/recovery.log)
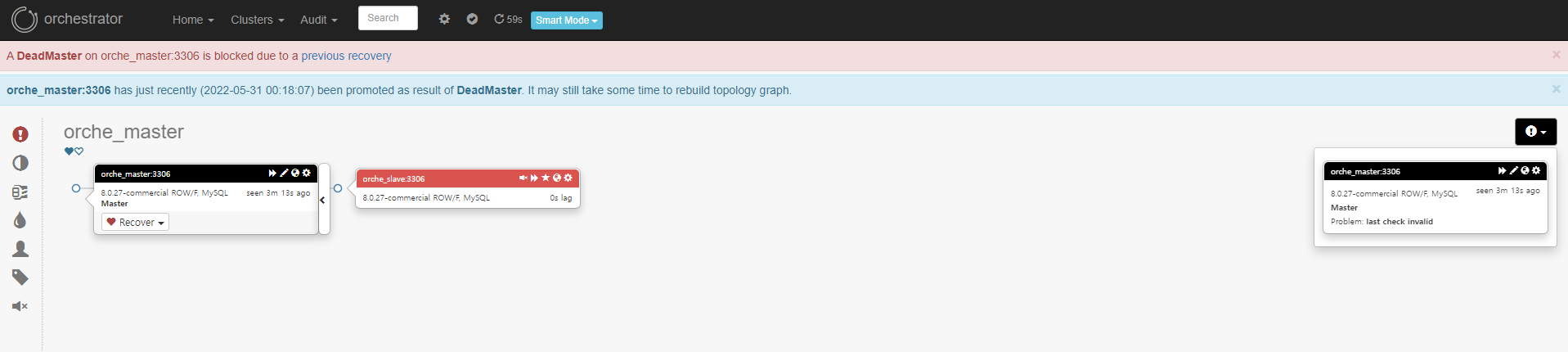

Orchestrator Fail-Over
Orchestrator에서의 기본 Fail-Over 방식은 Manual 입니다. 즉, 수동으로 특정 Slave Server를 선택하여 승격(Promote) 하여 장애를 처리(Failover) 해야합니다.
토폴로지에서, Master Node의 Recovery를 클릭하면 승격 할 Slave Server를 선택할 수 있습니다.
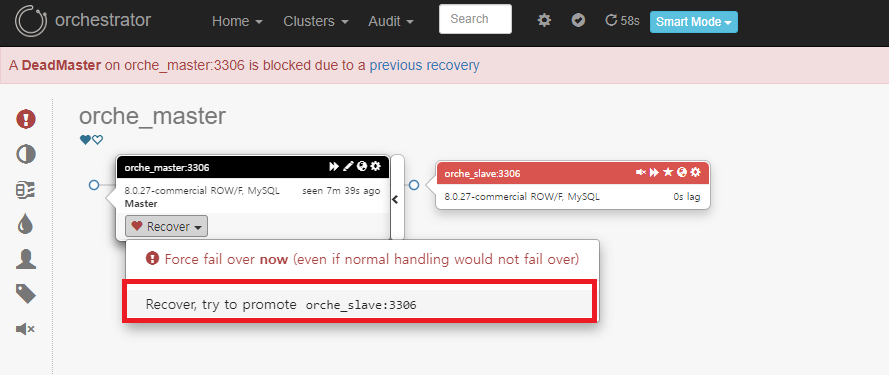
승격 후, Master Node와 Slave Node가 분리되었음을 알 수 있습니다. (Promotion)
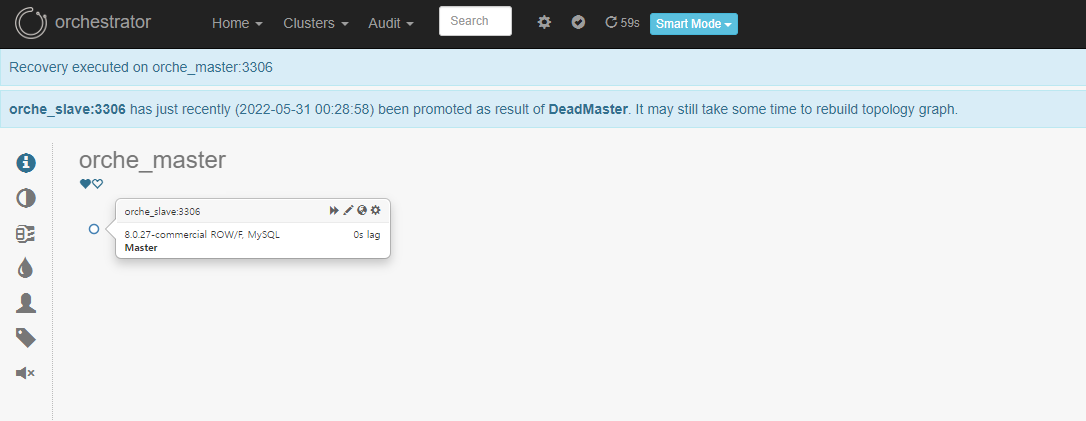
recocery.log 출력

다운된(장애가 발생된 Master Node) Server를 다시 재기동합니다. (복구 되었다는 가정)
#mysqld_safe --user=mysql &
데이터 유실이 없는지 확인하기 위해, Promote 된 Slave Server에 스키마를 생성합니다.
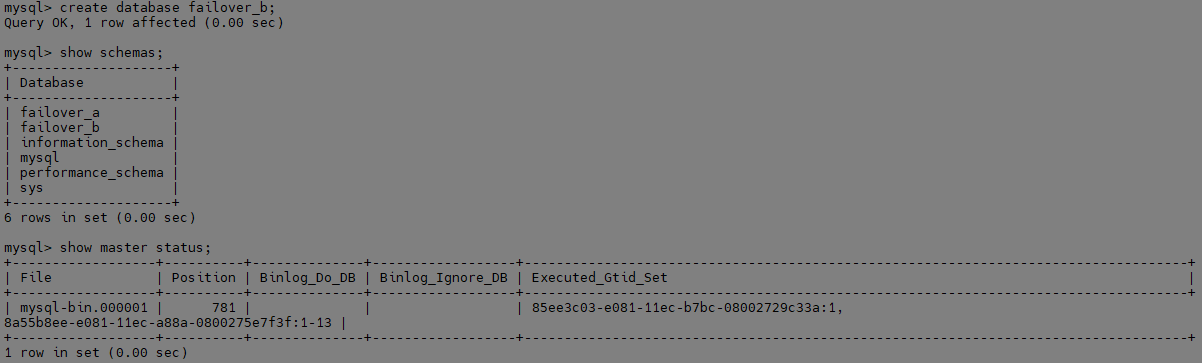
Slave Server에서 스키마를 생성하자(트랜잭션을 발생하자), 기존 Master GTID와 함께 자신의 GTID가 함께 만들어집니다.
다시 Replication을 설정합니다. (Down 되었던 Master Server)
mysql> change master to
master_host='orche_slave',
master_user='repl',
master_password='123',
master_auto_position=1;
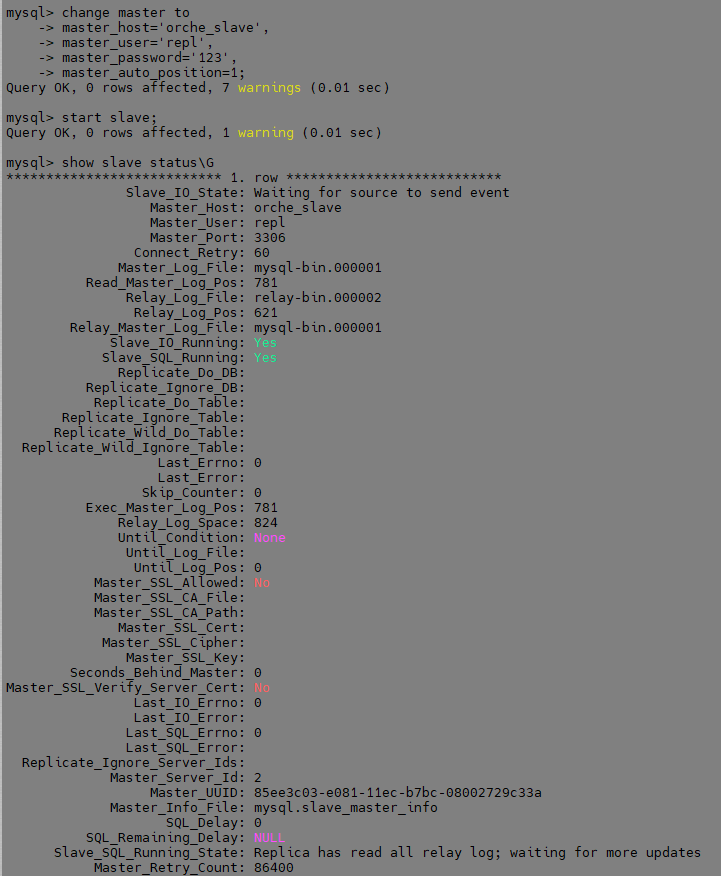
Slave가 정상적으로 구성되었고, 구성 되기 전 만든 스키마를 확인합니다. (failover_b)
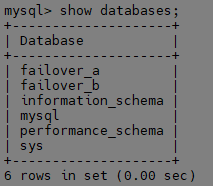
데이터 유실 없이 잘 동작함을 증명할 수 있습니다.
Orchestrator Automated Recovery(Failover)
Automated Recovery가 발생할 시, 승격 되는 노드를 지정할 수 있습니다.
conf.json 파일에서 지정하지 않으면, 앞서 설명한 것처럼 수동 복구가 기본입니다. 일부 파라미터 수정이 필요합니다.
-
RecoverMasterClusterFilters
Master 장애에 대해 자동 복구할 클러스터를 지정하는 파라미터입니다.
예를 들어 "orche_slave", "orche_slave2"가 지정되어 있다면, 여러 Slave에서 지정된 2개에 대해서만 자동 복구가 실행됩니다.
클러스터명을 명시적으로 입력 가능하고, 정규식(Regex)으로도 입력 가능합니다.
ex) "RecoverMasterClusterFilters": [
"myoltp", // cluster name includes this string
"meta[0-9]+", // cluster name matches this regex
"alias=olap", // cluster alias is exactly "olap"
"alias~=shard[0-9]+" // cluster alias matches this pattern
] -
RecoverIntermediateMasterClusterFilters
복제 구성에서 중간 Master 에 대한 복구 여부를 설정하는 파라미터입니다. -
PromotionIgnoreHostnameFilters
Slave 노드 중, Master 승격 대상에서 제외 할 Hostname을 입력합니다.
동일하게 정규식을 사용하여 입력할 수도 있습니다. -
RevoceryPeriodBlockSeconds
장애 발생 후, 자동 복구 시 파라미터 지정 시간 동안은 자동 복구를 차단하게 됩니다. (default : 3600s)
플랩 방지 메커니즘이라고 합니다.
해당 포스팅과 맞게 conf.json 파일을 수정하겠습니다.
테스트를 위해 RevoceryPeriodBlockSeconds 값을 10초로 설정하고, 자동 복구 클러스터를 "orche"로 지정하겠습니다. (orche가 포함된 Hostname 전부)
변경 후, 브라우저에서 Home → Status → Reload configuration을 클릭하여 변경한 설정을 적용합니다.
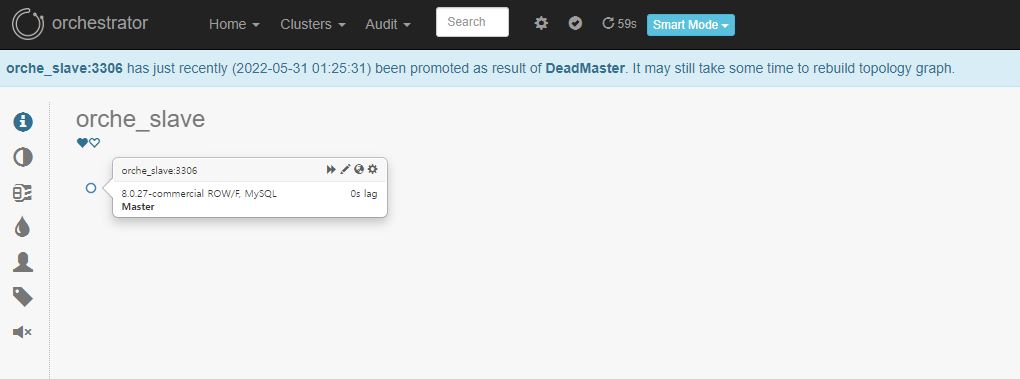
Master Server 인스턴스를 중지 하겠습니다. (장애 발생)
수동 절체와 다르게, 자동으로 Slave가 자동 승격 됨을 알 수 있습니다. 재구성을 위해서는, 기존 Master server를 재기동하여(장애 처리 완료 가정), 동일하게 복제를 구성합니다.

안녕하세요. 구축관련해서 혹시
2023-10-25 07:48:32 ERROR Error initiating orchestrator: Error 1091: Can't DROP INDEX
resolved_timestamp_idx; check that it exists; query=DROP INDEX resolved_timestamp_idx ON hostname_resolve
[mysql] 2023/10/25 07:49:02 packets.go:37: read tcp 127.0.0.1:14956->127.0.0.1:3306: i/o timeout
2023-10-25 07:49:02 FATAL Cannot initiate orchestrator: invalid connection; query=
INSERT IGNORE INTO active_node (anchor, hostname, token, last_seen_active)
이런 에러로그 보셨을까요?