인공지능
- 인공지능은 훈련된 데이터를 바탕으로 가장 최적의 반응을 찾는 것.
- 통계적인 방법으로 오차를 해소
- 조건에 따른 결과값을 출력하는 것에서
- 출력된 다수의 결과값 중에서 가중치가 반영된 최적의 반응을 출력하는 것.
텍스트 데이터 학습의 문제점
- 텍스트를 숫자행렬로 표현할 수 있는가.
- 텍스트의 입력 데이터 순서를 인공지능에 어떻게 반영하는가.
→ 사전을 이용하여 단어의 의미를 나타내는 벡터를 짝짓는다면?
→ 딥러닝을 통해 벡터를 생성
데이터 얻기
여러 txt 파일을 가져와서
하나의 데이터로 묶어서
데이터 확인
예제 문장
>i feel hungry
i eat lunch
now i feel happy데이터를 숫자로
너무 긴문장은 없애고
단어별로 쪼개고
# 처리해야 할 문장을 파이썬 리스트에 옮겨 담았습니다.
sentences=['i feel hungry', 'i eat lunch', 'now i feel happy']딕셔너리로 표현해서
# 파이썬 split() 메소드를 이용해 단어 단위로 문장을 쪼개 봅니다.
word_list = 'i feel hungry'.split()
print(word_list)[텍스트: 인덱스]구조를 만들고
index_to_word={} # 빈 딕셔너리를 만들어서
# 단어들을 하나씩 채워 봅니다. 채우는 순서는 일단 임의로 하였습니다. 그러나 사실 순서는 중요하지 않습니다.
# <BOS>, <PAD>, <UNK>는 관례적으로 딕셔너리 맨 앞에 넣어줍니다.
index_to_word[0]='<PAD>' # 패딩용 단어
index_to_word[1]='<BOS>' # 문장의 시작지점
index_to_word[2]='<UNK>' # 사전에 없는(Unknown) 단어
index_to_word[3]='i'
index_to_word[4]='feel'
index_to_word[5]='hungry'
index_to_word[6]='eat'
index_to_word[7]='lunch'
index_to_word[8]='now'
index_to_word[9]='happy'
print(index_to_word)데이터를 숫자로 표현하고
# 텍스트데이터를 숫자로 바꾸기
word_to_index={word:index for index, word in index_to_word.items()}
print(word_to_index)가진 데이터를 숫자로 변환하고
# 문장 1개를 활용할 딕셔너리와 함께 주면, 단어 인덱스 리스트로 변환해 주는 함수를 만들어 봅시다.
# 단, 모든 문장은 <BOS>로 시작하는 것으로 합니다.
def get_encoded_sentence(sentence, word_to_index):
return [word_to_index['<BOS>']]+[word_to_index[word]
if word in word_to_index
else word_to_index['<UNK>']
for word in sentence.split()]
print(get_encoded_sentence('i eat lunch', word_to_index))
def get_encoded_sentences(sentences, word_to_index):
return [get_encoded_sentence(sentence, word_to_index)
for sentence in sentences]
# sentences=['i feel hungry', 'i eat lunch', 'now i feel happy'] 가
# 아래와 같이 변환됩니다.
encoded_sentences = get_encoded_sentences(sentences, word_to_index)
print(encoded_sentences)디코딩하기 (문자를 다시 숫자로)
def get_decoded_sentence(encoded_sentence, index_to_word):
return ' '.join(index_to_word[index]
if index in index_to_word
else '<UNK>'
for index in encoded_sentence[1:])
#[1:]를 통해 <BOS>를 제외
print(get_decoded_sentence([1, 3, 4, 5], index_to_word))
def get_decoded_sentences(encoded_sentences, index_to_word):
return [get_decoded_sentence(encoded_sentence, index_to_word)
for encoded_sentence in encoded_sentences]
# encoded_sentences=[[1, 3, 4, 5], [1, 3, 6, 7], [1, 8, 3, 4, 9]] 가
# 아래와 같이 변환됩니다.
print(get_decoded_sentences(encoded_sentences, index_to_word))Embedding 레이어
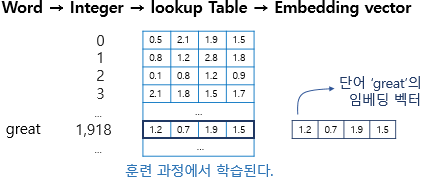
Embedding 레이어
- 단어의 의미를 나타내는 벡터를 훈련 가능한 파라미터로 놓고
- 딥러닝을 통해 최적화
- 문장 벡터가 일정하지 않으면 에러가 발생
문장 패딩
raw_inputs = tf.keras.preprocessing.sequence.pad_sequences(raw_inputs,
value=word_to_index['<PAD>'],
padding='post',
maxlen=5)
print(raw_inputs)시퀀스를 다루는 RNN
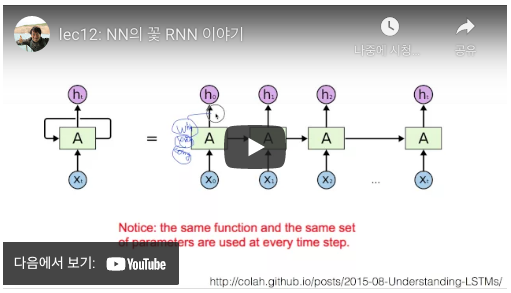
- RNN은 시퀀스(Sequence) 형태의 데이터를 처리하기에 최적인 모델
- 다음말이 무얼지
- 시간의 흐름에 따라 새롭게 들어오는 입력에 따라 변하는 현재의 상태를 묘사하는
- State Machine

김성훈 교수의 모두의 딥러닝 강좌 12강.RNN
왜 CNN을 쓰지 않고 RNN을 쓸까?
- 텍스트를 처리하기 위해 RNN이 아니라 1-D Convolution Neural Network(1-D CNN)를 사용할 수도
- 이미지 분류기를 구현하면서 2-D CNN을 사용
- 이미지 분류기 모델에는 이미지 전체가 한꺼번에 입력으로 사용
- 1-D CNN은 문장 전체를 한꺼번에 한 방향으로 길이 7짜리 필터로 스캐닝 하면서 7단어 이내에서 발견되는 특징을 추출하여 그것으로 문장을 분류하는 방식으로 사용
- CNN 계열은 RNN 계열보다 병렬처리가 효율적이기 때문에 학습 속도도 훨씬 빠르게 진행된다는 장점
vocab_size = 10 # 어휘 사전의 크기입니다(10개의 단어)
word_vector_dim = 4 # 단어 하나를 표현하는 임베딩 벡터의 차원 수입니다.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(tf.keras.layers.Conv1D(16, 7, activation='relu'))
model.add(tf.keras.layers.MaxPooling1D(5))
model.add(tf.keras.layers.Conv1D(16, 7, activation='relu'))
model.add(tf.keras.layers.GlobalMaxPooling1D())
model.add(tf.keras.layers.Dense(8, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid')) # 최종 출력은 긍정/부정을 나타내는 1dim 입니다.
model.summary()Model: "sequential_2"
Layer (type) Output Shape Param #
\=================================================================
embedding_4 (Embedding) (None, None, 4) 40
conv1d (Conv1D) (None, None, 16) 464
max_pooling1d (MaxPooling1D) (None, None, 16) 0
conv1d_1 (Conv1D) (None, None, 16) 1808
global_max_pooling1d (Global (None, 16) 0
dense_4 (Dense) (None, 8) 136
dense_5 (Dense) (None, 1) 9
\=================================================================
Total params: 2,457
Trainable params: 2,457
Non-trainable params: 0
- 간단히는 GlobalMaxPooling1D() 레이어 하나만 사용하는 방법
- 전체 문장 중에서 단 하나의 가장 중요한 단어만 피처로 추출
- 추출한 것으로 문장의 긍정/부정을 평가하는 방식
vocab_size = 10 # 어휘 사전의 크기입니다(10개의 단어)
word_vector_dim = 4 # 단어 하나를 표현하는 임베딩 벡터의 차원 수입니다.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(tf.keras.layers.GlobalMaxPooling1D())
model.add(tf.keras.layers.Dense(8, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid')) # 최종 출력은 긍정/부정을 나타내는 1dim 입니다.
model.summary()Model: "sequential_3"
Layer (type) Output Shape Param #
\=================================================================
embedding_5 (Embedding) (None, None, 4) 40
global_max_pooling1d_1 (Glob (None, 4) 0
dense_6 (Dense) (None, 8) 40
dense_7 (Dense) (None, 1) 9
\=================================================================
Total params: 89
Trainable params: 89
Non-trainable params: 0
각 모델의 파라미터에 대한 이해 필요
