[ASR study] wavenet : generative model for raw audio
introduction
최근(2016) augoregressive generative 모델이 많이 발전했는데 이는 pixel이나 words에 대한 joint probability를 학습했다. pixel rnn에 영감을 받아 이를 오디오에도 적용한 모델을 고안해보았다.pixelcnn에 기반으로 한 wavenet을 소개한다
pixelrnn, pixelcnn이란?
이미지 생성 초기 모델로 augoregressive한 방식으로 이미지를 생성
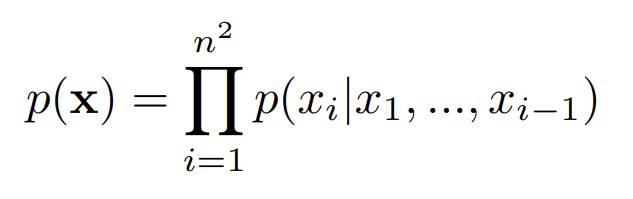
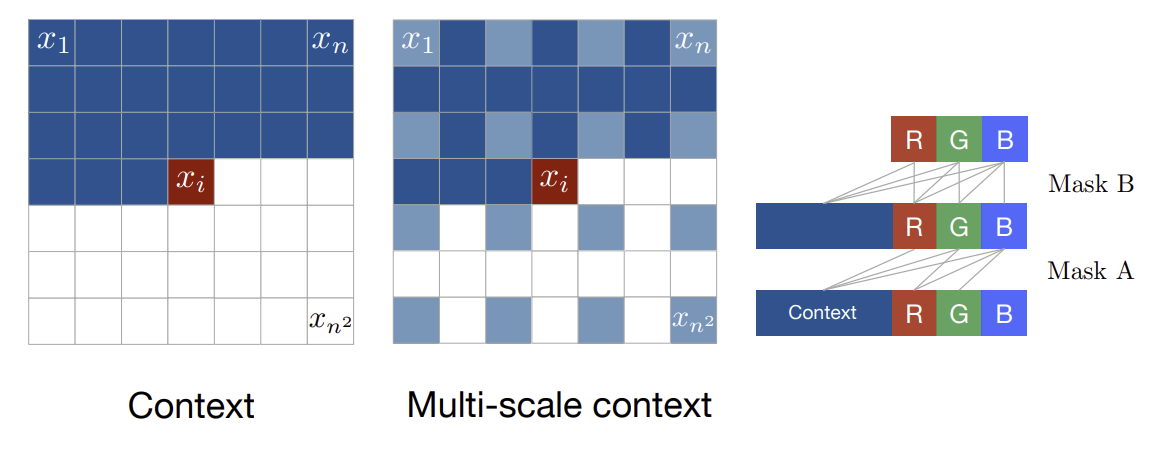
기존 context로 다음 pixel을 예측하는 방식으로 학습한다.
wavenet
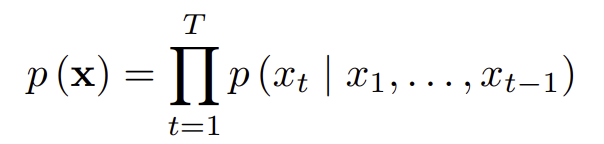
wavenet 또한 pixel rnn과 마찬가지로 augoregressive하게 생성한다
no pooling, same input output size
softmax distribution
오디오 데이터는 16bit로 나타내면 65536개의 output이 존재한다. 이를 모두 계산하기는 어렵기 때문에 u-law 방식을 적용해서 8bit(256)으로 양자화를 진행한다
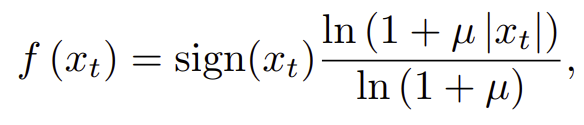
식은 다음과 같다. 기존 데이터인 x_t가 해당 식에 의해
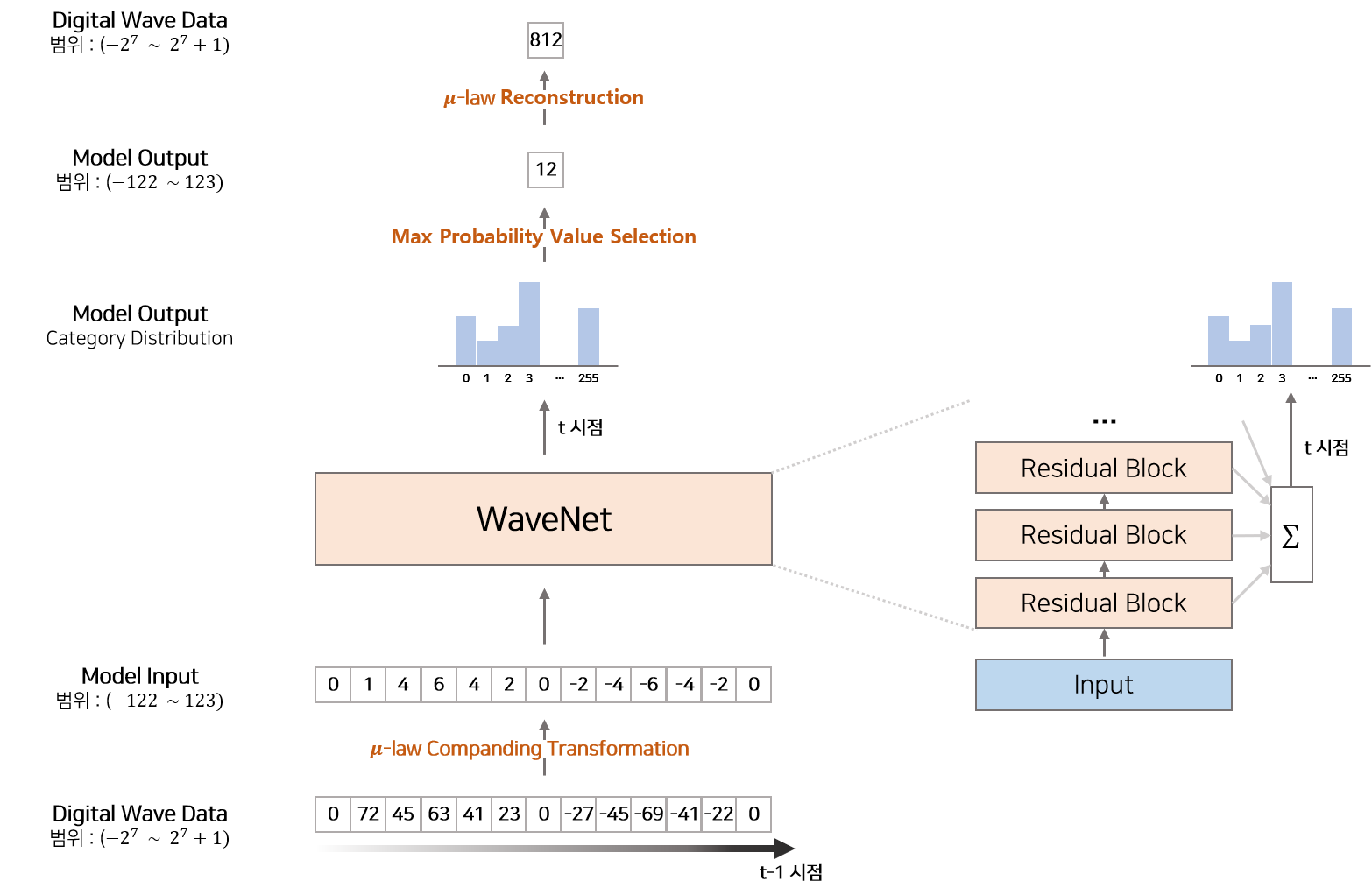
기존 wavedata 값이 u-law companding에 의해 양자화되고 wavenet을 거치면 256개의 softmax distribution이 나온다. 이에 대해 reconstruction으로 값을 복원한다.
DILATED CAUSAL CONVOLUTIONS
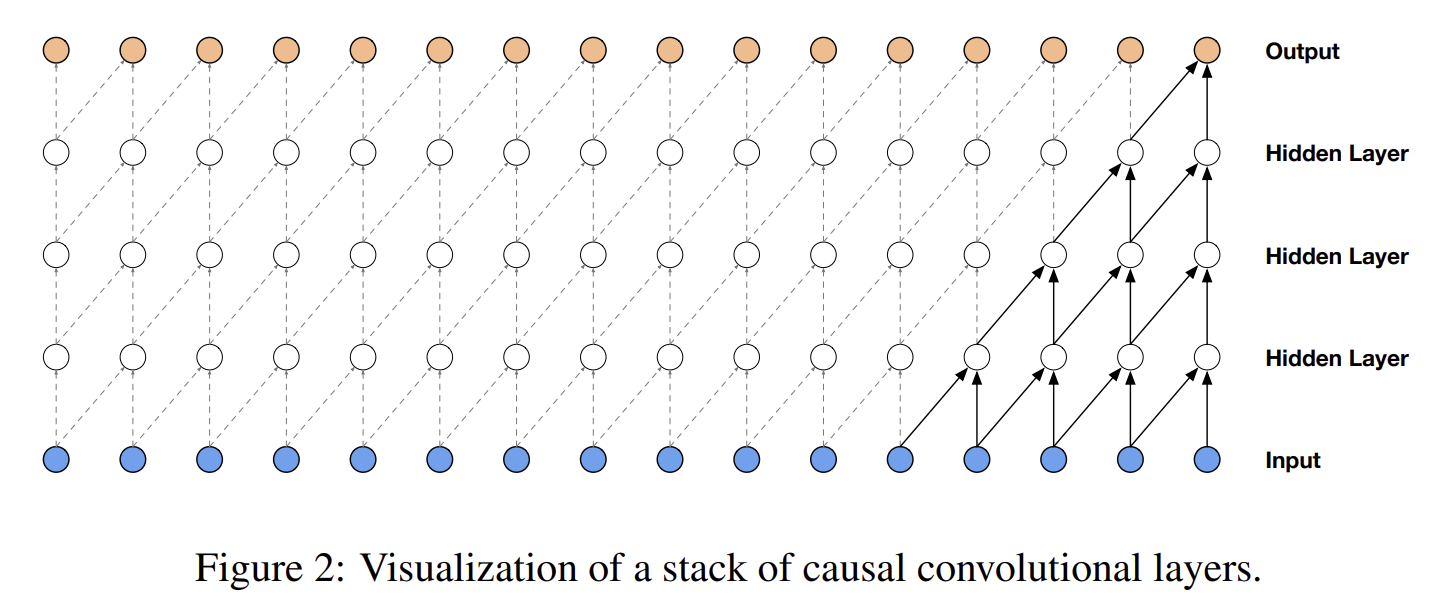
우선 causal convolution 연산을 알아야 한다. causal convolution이란? conv 연산을 하는데 있어 rnn과 같이 순서의 정보도 추가한 conv이다.
2개의 state를 conv해서 전개하는데 있어서 sequential한 데이터가 들어가 다음 state로 넘어가기 때문에 이를 layer를 많이 쌓으면 receptive field(수용 범위)가 넓어져 RNN과 비슷하게 된다는 장점이 있다.
하지만 여기에는 치명적인 단점이 있는데 , 범위를 넓게 잡기 위해서는 layer를 매우 많이 쌓아야 한다는 것이다. n개의 context를 위해 n-1개의 layer가 필요하다.
특히 오디오 데이터는 1초에 16000 sample인데 이를 위해서는 수천 layer가 필요하다
파라미터를 효율화하고 receptive field를 넓게 하기 위해 dilated를 도입한다
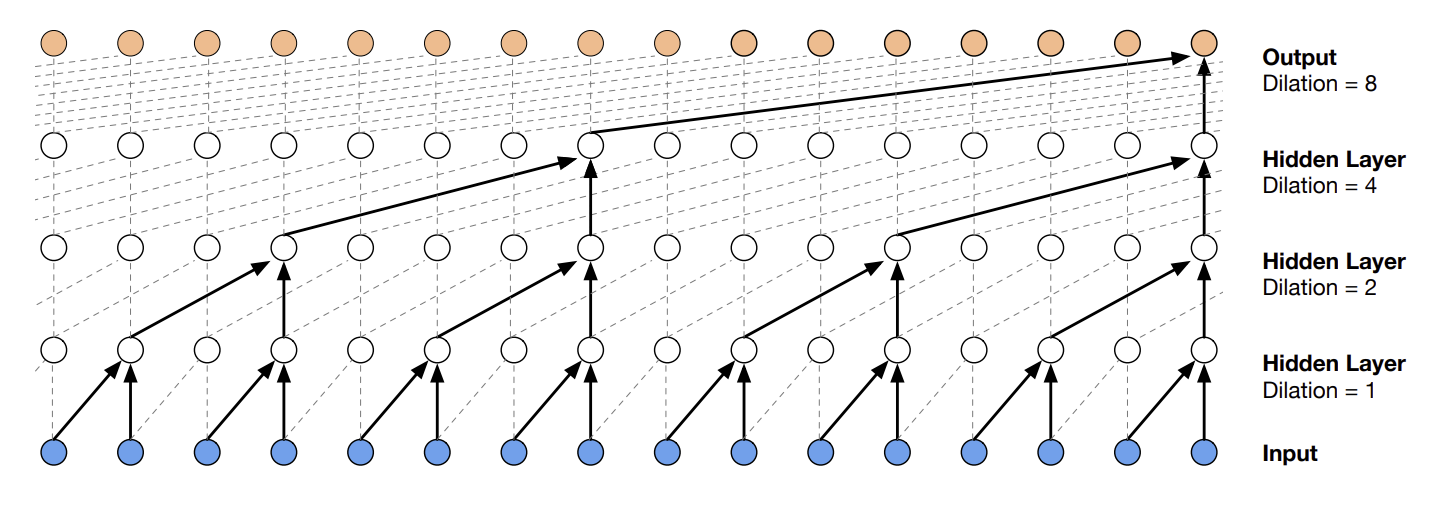
delated causal conv는 그림과 같이 처음에 n개의 범위에 대해서 conv 연산을 수행한 후 , 다음 layer에서는 사이사이는 생략하고 n/2개의 state를 보고 이렇게 2의 제곱 단위로 계속 conv를 수행한다. 이렇게 하면 장점이 여럿 있는데
1.local , global context 모두 볼 수 있다.
2.긴 범위를 보는데 필요한 파라미터가 효율적이다
기본적으로 이런 dilated causal conv를 사용한다.
Residual connection & gated activation units
dilated causal conv의 내부 구조는 다음과 같다.
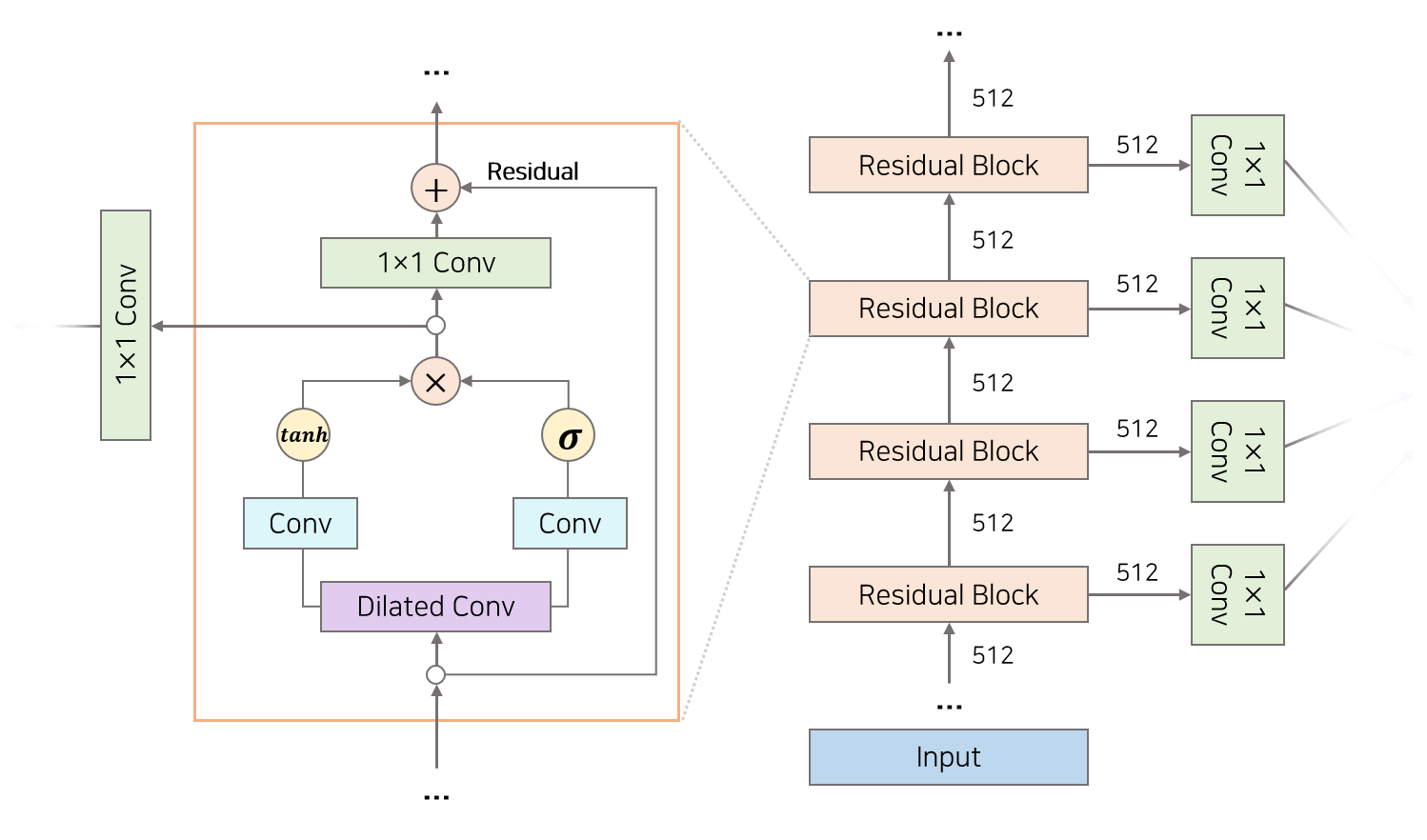
dilated causal conv의 결과인 벡터는 gate와 filter로 나뉘어서 가서 conv 연산을 또 수행하며 element-wise를 한다. 이는 pixelCNN에서 가져온 구조라고 한다
식은 다음과 같다
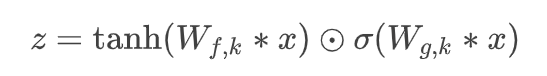
여기서 필터는 지역적 특징 , 게이트는 수도꼭지의 역할을 한다
(Q: 결과값 z는 1보다 작은 값들인데 .. 이 역할은 벡터의 방향을 바꾸는 역할만하나?)
여기에 residual connection으로 output과 input이 합쳐져 깊은 layer를 쌓을 수 있게 한다.
skip connection
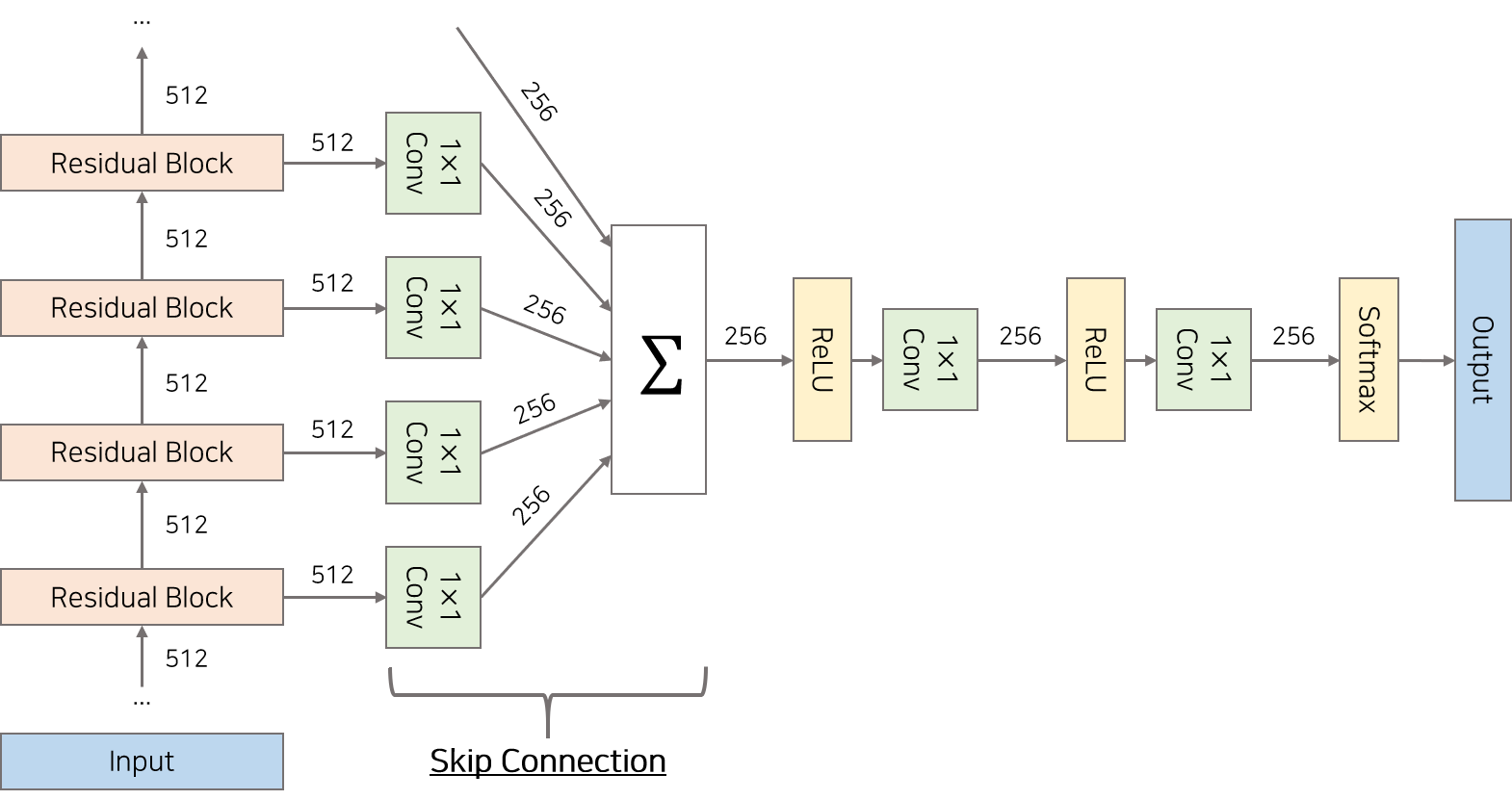
DCC를 한 후의 최종 결과는 맨 위의 output만 사용되는 것이 아닌 , 모든 layer의 output이 skip connection을 통해 사용된다. 1 x 1 conv 연산을 거친 후 더해준다. 이렇게 되면 global , local에 대한 정보 모두 더하는 것이 된다.
그리고 relu , 1 x 1 conv 등을 거쳐서 소프트 맥스를 거쳐 최종 output이 출력된다.
conditional wavenets
audio generation은 조건화를 해야할 경우가 종종 있다. 예를 들어 TTS에서 남자 목소리를 내야할 경우 , 또는 특정 단어에 대한 TTS가 나와야하는 경우 등.
이는 수식으로 다음과 같이 나타낼 수 있다.
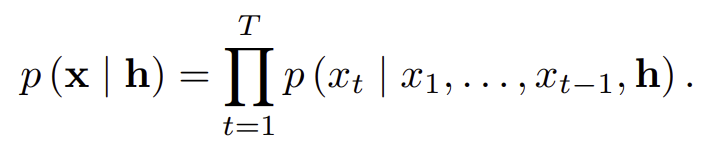
이 h를 학습에 반영하는 방법은 2가지이다.
1.global
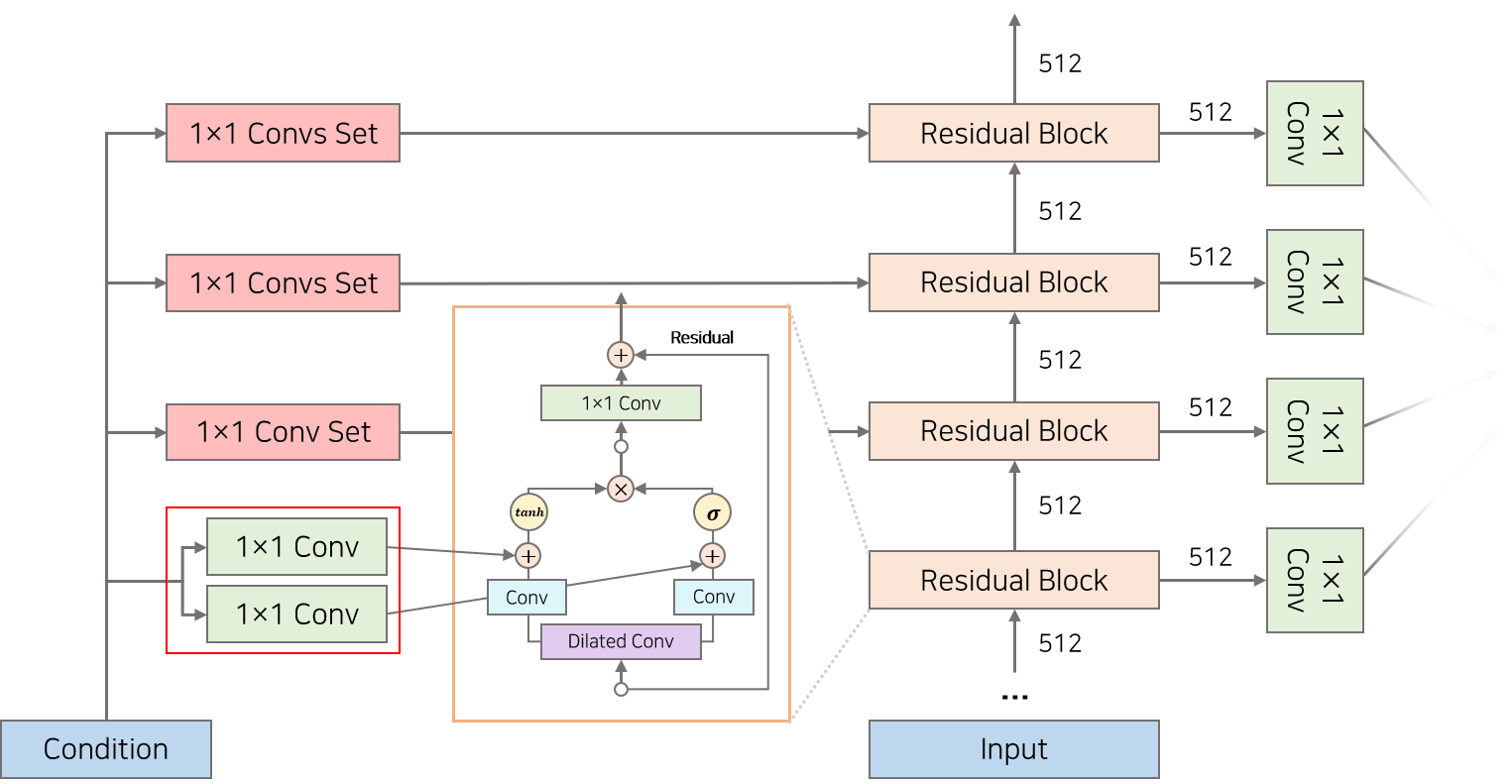
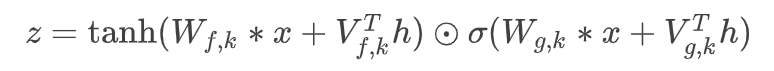
filter,gate에서 1x1 conv를 할 때 condition에 해당하는 h를 같이 conv해서 더해주는 것이다. 이때 h에 대한 정보는 모든 레이어에서 동일하게 인식되어야 하므로 글로벌하게 같은 값을 넣어준다.
2.local
시간에 따라 정보가 달라지는 TTS같은 경우에는 시간에 따라 cell에 다른 정보를 각각 넣어주어야 한다. 예를 들어 'text'면 ttt-eeeee-xxttt 이런식
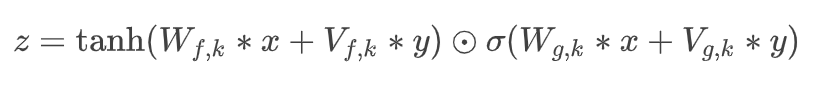
그런데 time series에 정확히 해당 단어나 음소에 해당하는 정보를 조건화해서 넣어주기가 어렵다. 이를 위해 upsampling이라는 것을 사용할 수 있는데 이를 조건 정보를 일률적으로 길게 해주는 것이다. 가령 길이가 64000이고 text가 'this is kiwi'라면 , 문장을 upsampling해서 길이 64000에 맞게 해주는것.
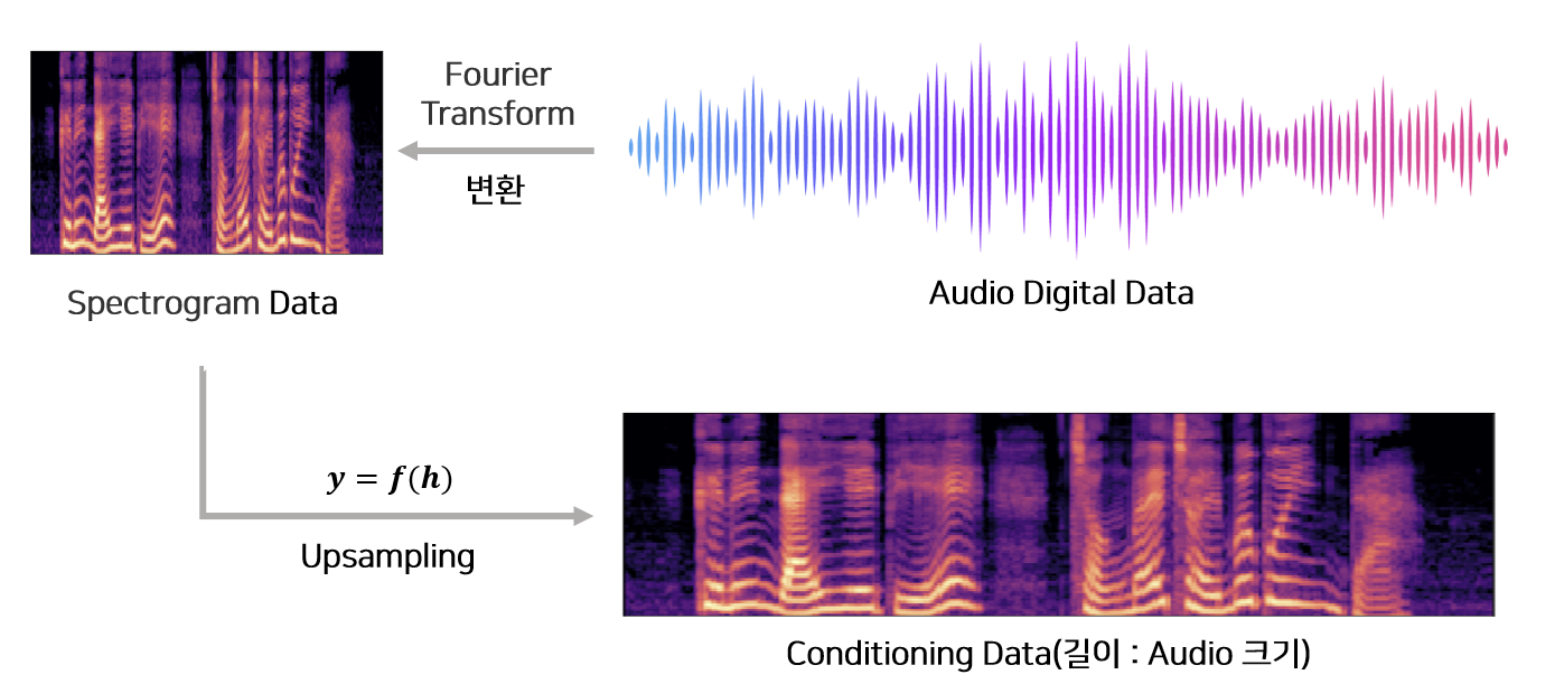
이는 upsampling의 예시이다. 해당 audio signal에 해당하는 조건이 있다면 이를 upsampling하여서 대상의 오디오 길이에 맞춰서 준다.
experiment
처음에는 text를 주지 않고 speaker에 대한 ID만 one-hot encoding으로 제공했다. human like word를 생성하게 하였다. 실험 결과 109 명의 speaker의 특징을 잘 잡아냈다.
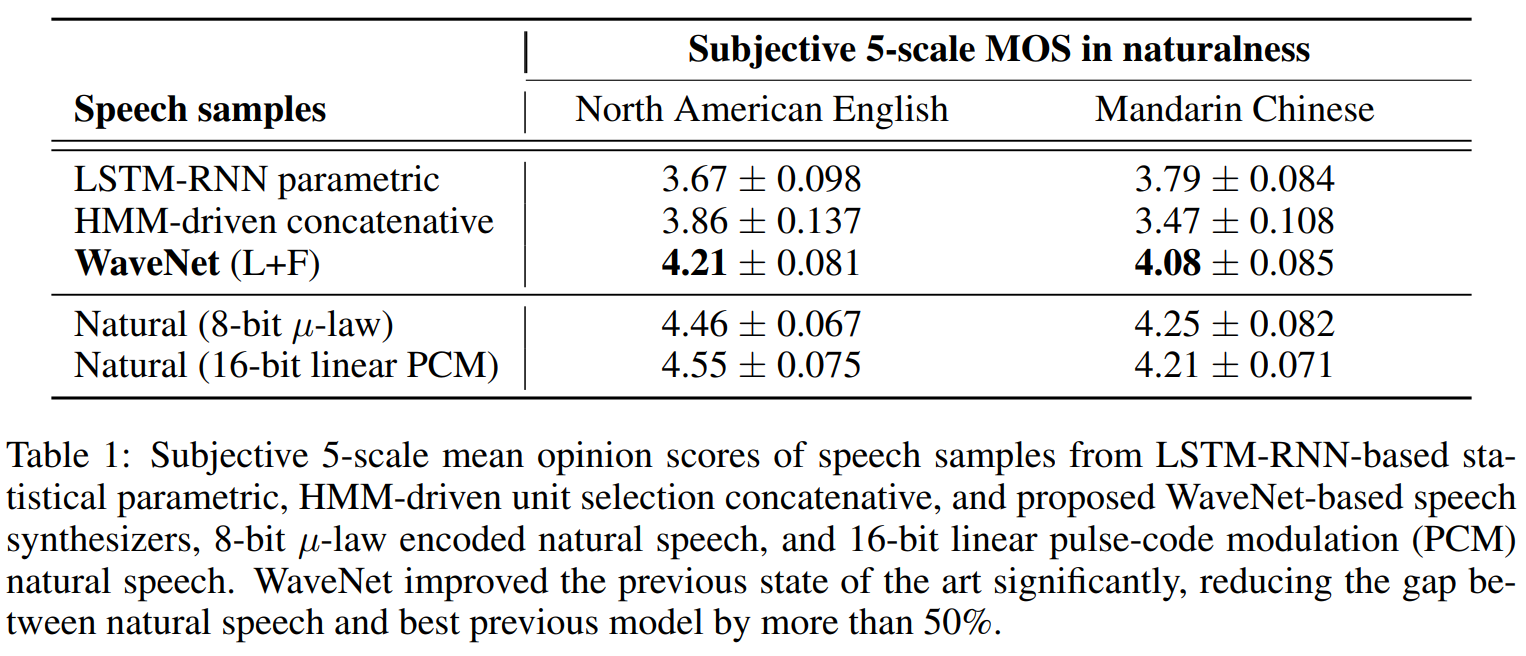
TTS를 할 때는 1명의 speaker로만 조건화하고 훈련했다. 사람의 주관적인 평가 1~5점 면에서 선호하는 것을 고르는 테스트를 했다. natural한 소리와 비슷한 결과를 얻고 다른 baseline을 매우 앞섰다.
code
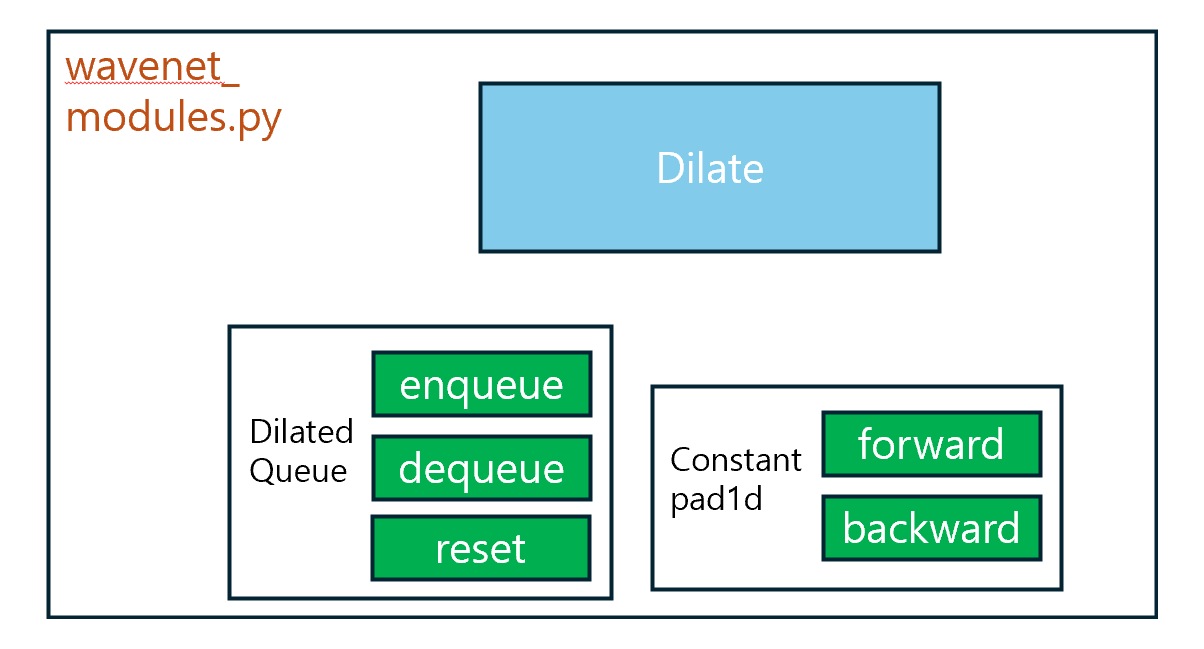
dilate function

유효한 dilate size대로 패딩을 주는 함수
conv1d를 하면 dilate 연산이 되도록 shape을 변경해주는 역할을 한다
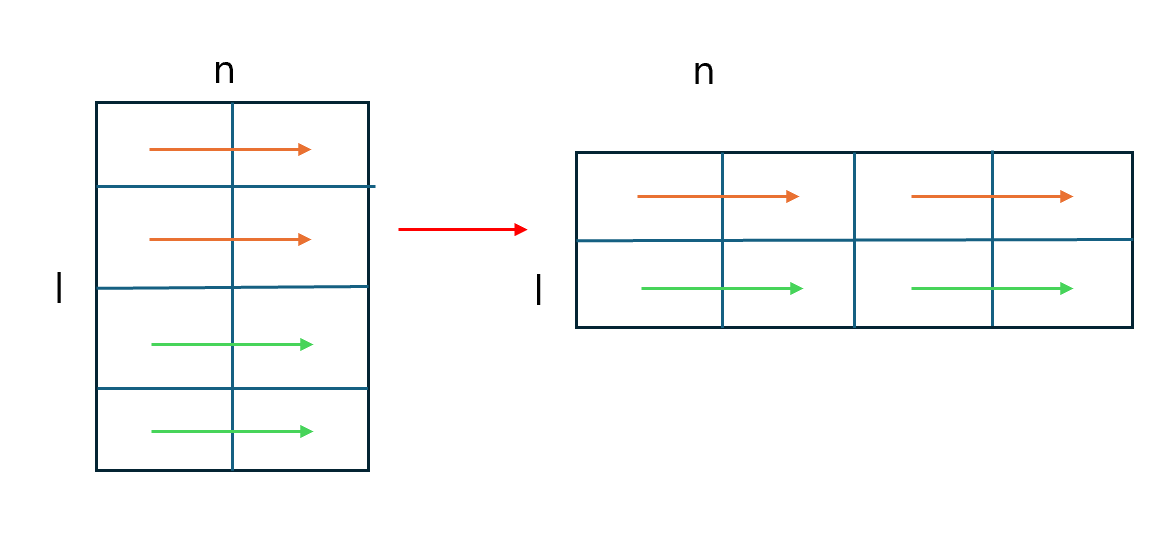
n은 늘리고 l을 줄임으로써 옆에있는 것을 바로 conv할 수 있게
dilate Queue class
fast generation에서 쓰기 위한 class

밑에 wavenet 초기화에 이렇게 들어간다

wavenetmodel.py // wavenet
block,layer 그리고 각 단계에서 conv연산 등은 init에서 초기화 된 상태
각 layer들이 있는 block이 여럿 쌓인 형태
def wavenet(self, input, dilation_func):
x = self.start_conv(input)
skip = 0
# WaveNet layers
for i in range(self.blocks * self.layers):
# |----------------------------------------| *residual*
# | |
# | |-- conv -- tanh --| |
# -> dilate -|----| * ----|-- 1x1 -- + --> *input*
# |-- conv -- sigm --| |
# 1x1
# |
# ---------------------------------------> + -------------> *skip*
(dilation, init_dilation) = self.dilations[i]
residual = dilation_func(x, dilation, init_dilation, i)
# dilated convolution
filter = self.filter_convs[i](residual)
filter = F.tanh(filter)
gate = self.gate_convs[i](residual)
gate = F.sigmoid(gate)
x = filter * gate
# parametrized skip connection
s = x
if x.size(2) != 1:
s = dilate(x, 1, init_dilation=dilation)
s = self.skip_convs[i](s)
try:
skip = skip[:, :, -s.size(2):]
except:
skip = 0
skip = s + skip
x = self.residual_convs[i](x)
x = x + residual[:, :, (self.kernel_size - 1):]
x = F.relu(skip)
x = F.relu(self.end_conv_1(x))
x = self.end_conv_2(x)
return xwavenetmodel.py //forward
shape확정, transpose
def forward(self, input):
x = self.wavenet(input,
dilation_func=self.wavenet_dilate)
# reshape output
[n, c, l] = x.size()
l = self.output_length
x = x[:, :, -l:]
x = x.transpose(1, 2).contiguous()
x = x.view(n * l, c)
return xlength가 쭉 늘어진 형태
wavenetmodel.py // generate


train/valid


