[LLM review] Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels
introduction
LLM 발전으로 zero shot ranking 많이 발전했다. 일찍이 방법은 pointwise로 , 하나를 가지고 점수를 메기는 방식이었고 거기에 pairwise , listwise 방식도 나왔다. 하지만 얘네는 long list를 만들 수 없다
relevence에 대하여 classify하는게 있는데 대부분 yes or no이다. 하지만 directly하지는 않지만 관련이 있는 경우도 있다.
binary한 option을 주는건 biased answer로 주는 경우도 있고 , 보다 fine-grained 한 선택지는 주는게 정확도를 높힌다는 연구도 있다.
따라서 LLM 한테 zero shot으로 fine-grained relevance label을 주려고 한다. 'highly relevant' , 'somewhat relevant' , 'not relevant' 여기서 likelyhood score를 모은다.
실험 결과 이로인해서 보다 ranking performance를 높히고 이전에 구별 불가능했던 document를 구별하게 한다.
method
preliminaries
query와 document d_i 를 넣는다. 거기서 yes,no 에 대한 log-likelihood를 구한다
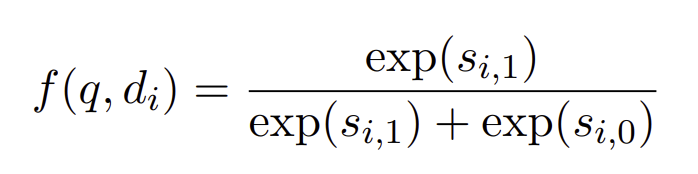
그리고 softmax 씌운다
prompts
class를 'not relevant' ,'somewhat relevent' ,'highly relevant'로 나눈다.

뿐만아니라 , 다음과 같이 0~4까지 해서 log-likelihood를 사용할 수도 있다.

expected relevance
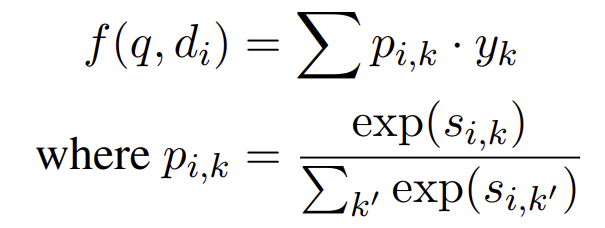
각 라벨에 값이 y_k로 할당되어 있을때 p_i,k 를 구하고 더함으로써 expected value를 구할 수 있다.
peak relevance likelihood (PR)
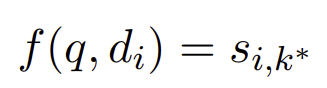
그냥 관련성이 높은 라벨의 likelihood를 가져오는 것.
제일 간단한 방법
expreiment

비교 대상은 이렇게 4개이다.
기본적으로 모두 expectation 기법을 써서 구해진다.
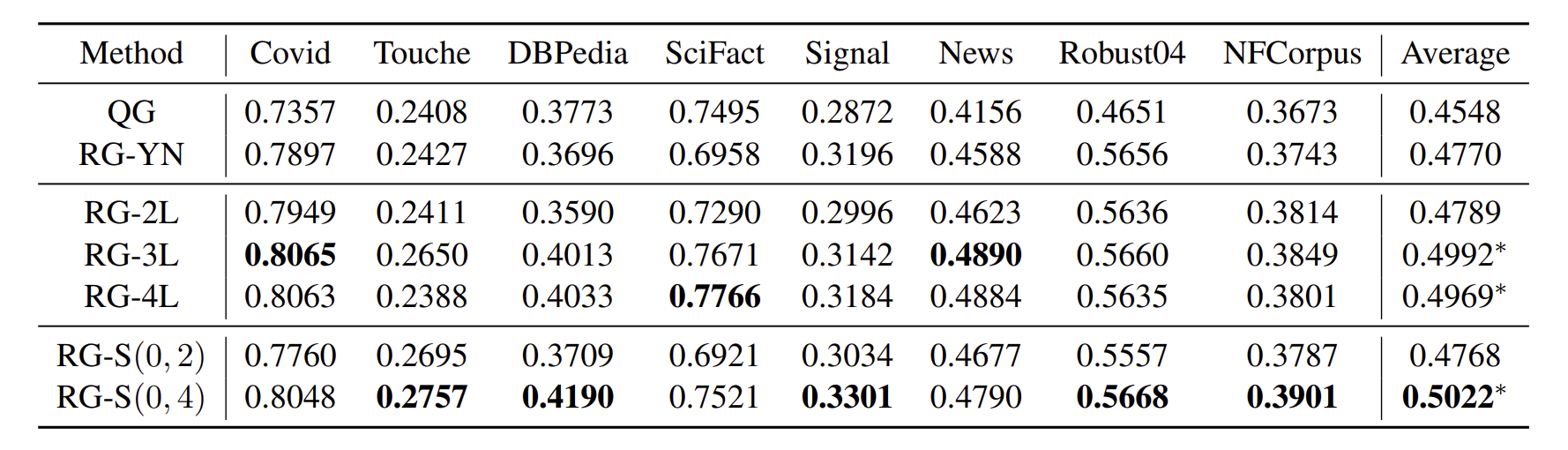
대부분 더 finegrained하게 한 것들이 잘 나왔으며 , 심지어 binary classify에서도 잘 나왔다.
finegrained relevance label이 더욱 정확하고 prompt자체 또한 nuanced understanding이 가능하게 했다는 해석이 가능하다.
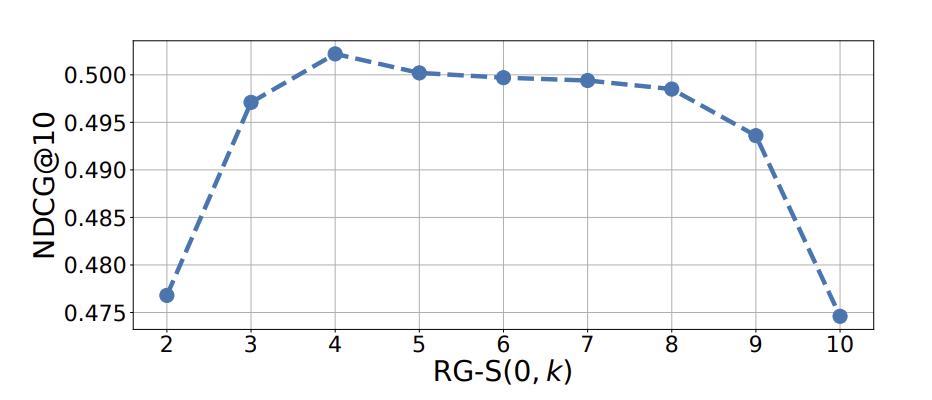
k=4일때 가장 performance 좋다. (why?)
-> 과도한 granularity에서는 이해하기 어렵다는.
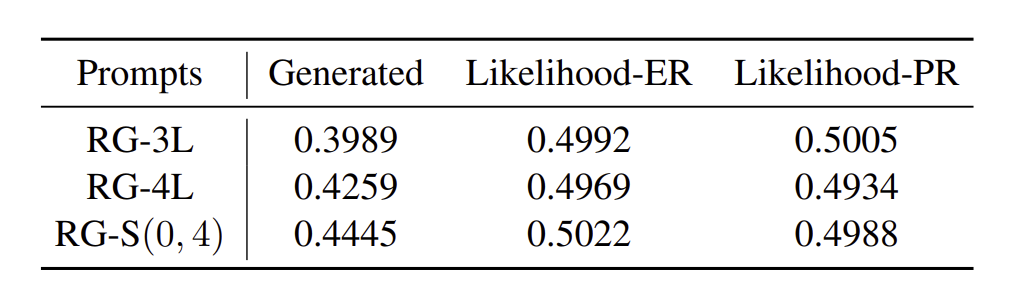
왜 어떨땐 4가 더 높고 어떨땐 비슷하지?
ER,PR이 가장 좋았다. generated보다는 압도적으로 좋다.
PR,ER 결과가 비슷한데 , 이는 그저 relevance의 가짓수를 높힌거 자체가 relevance의 차이를 더욱 알아차리는데 prompting했다고 해석하고 있음.
-> 다 좋은데 PR이 먹히는 rationale이 뭘까?
