[ASR study]Discriminative Training
Maximum Mutual Information Estimation
maximum likelihood estimation(MLE)는 관측치의 확률을 높히는데에 초점을 둔다.
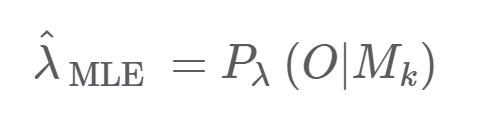
다음은 MLE식이다. 람다는 구하고자 하는 파라미터이고 , O는 mfcc같은 feature , M_k는 은닉마코브모델의 상태인 subphone의 sequence이다.
이는 M_k가 나올때 관측치 확률을 최대화하는 것이기 때문에 관측치에만 초점이 맞춰져있고 M_k를 최대화한다는 보장이 없다
그래서 Maximum Mutual Information Estimation(MMIE) 를 적용한다
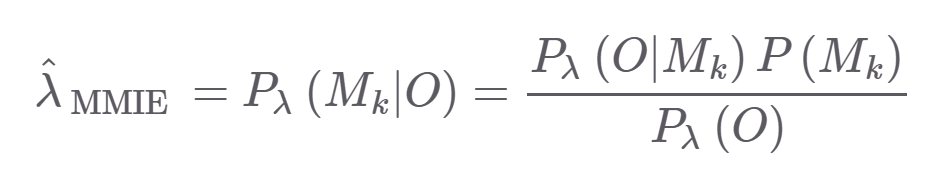
해당 식은 관측치가 주어졌을 때 정답 sequence가 나오는 확률을 나타내며 우측 식에서는 관측 O와 정답 M_k이 동시에 나타날 확률을 높히는 것이다. 좀 더 자세히보면

분자에서는 관측치 O와 sequence M_k가 동시에 나타날 확률이고
분모는 관측치 O와 다른 sequence가 나타날 확률들 합이다. 따라서 분모는 낮게 , 분자는 높게 하는게 목적이다.
오른쪽 식은 은닉마코브 모델로 구하는데 , 모든 sequence M_k에 대해서 구하는 것은 너무 많은 연산량이 든다는 문제점이 있다
따라서 top-k개에 대해서만 오답 확률을 계산한다.
acoustic models based on poterior classifier
HMM-GMM에서 P(o_t|q_j) 를 계산한다. 이는 마코브 모델을 이용해 q_j state일 때 관측치 o_t일 확률을 나타낸다. 이를 사후 확률(poterior) P(q_j|o_t)로 대체할 수 있다
이는 분류모델이기 때문에 입력(프레임),출력(음소),모델(svm)이 다양하다.
분류 확률 P(q_j|o_t)를 추정하기 위해서는 식의 변형이 필요하다
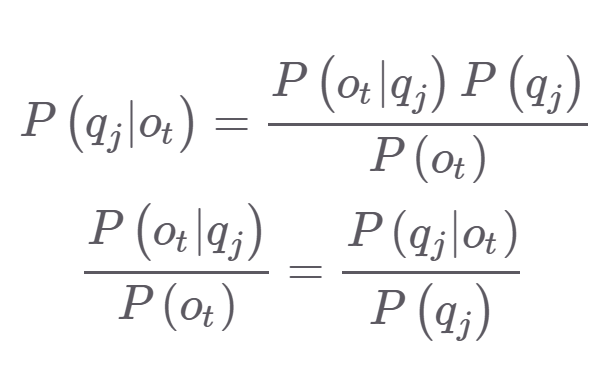
첫번째 줄의 식은 우변과 같이 우리가 HMM-GMM구조에서 알고 있는 hidden state에 대한 우도로 나타낼 수 있다. 이때 P(o_t)는 관측된 sequence이고 상태와 관계없이 모두 동일하기에 디코딩에 영향 미치지 않는다.
이렇게 HMM-GMM구조의 결과값으로 분류기의 레이블을 나타낼 수 있으며
이 레이블을 토대로 분류기를 학습하고 , 이 결과를 또 HMM-GMM에 넣는 iterate를 통해 학습을 한다.
ref : https://ratsgo.github.io/speechbook/docs/am/discriminative

좋은 내용 공유해주셔서 감사합니다 ~ 식의 흐름이 잘 정리가 되어져있어서 이해하기 좋네요