
Discourse
- Discourse covers linguistic expression beyond the boundary of the sentence -> 문장의 밖에서도 의미가 전달 됨
1) Dialogues : the structure of turns in conversation -> 대화
2) Monologues : the structure of entire passages, documents -> 하나의 문장이 쭉 이어진 독백
Coreference

=> You!, your father, you, him, I, your father 이 각각 누구를 가르키는지를 알아내는 게 coreference 이다.


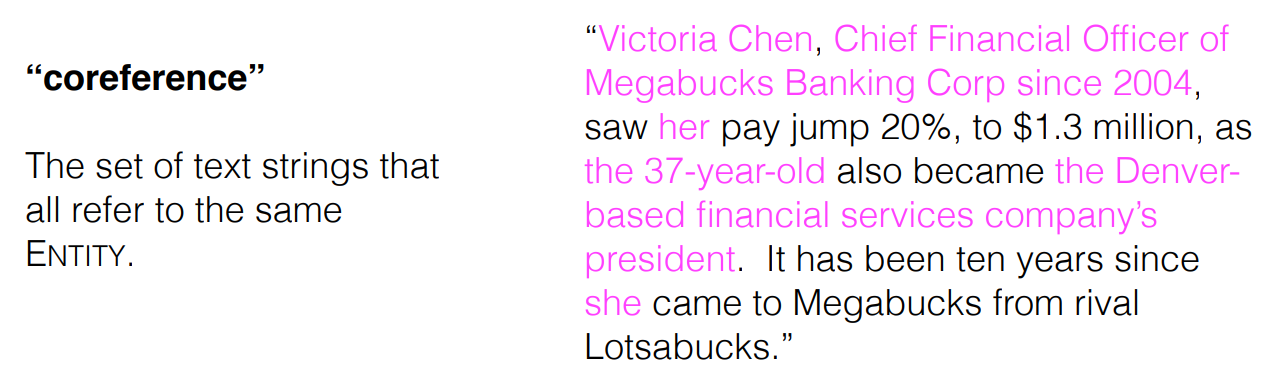
=> she, her, it, that 등이 고유명사 entities(VICTORIA CHEN, MEGABUCKS, LOTSABUCKS) 중에서 뭐를 가리키는지
=> company, 37-year-old, president ... 등이 뭐를 가리키는지
Event Coreference

Verb semantics
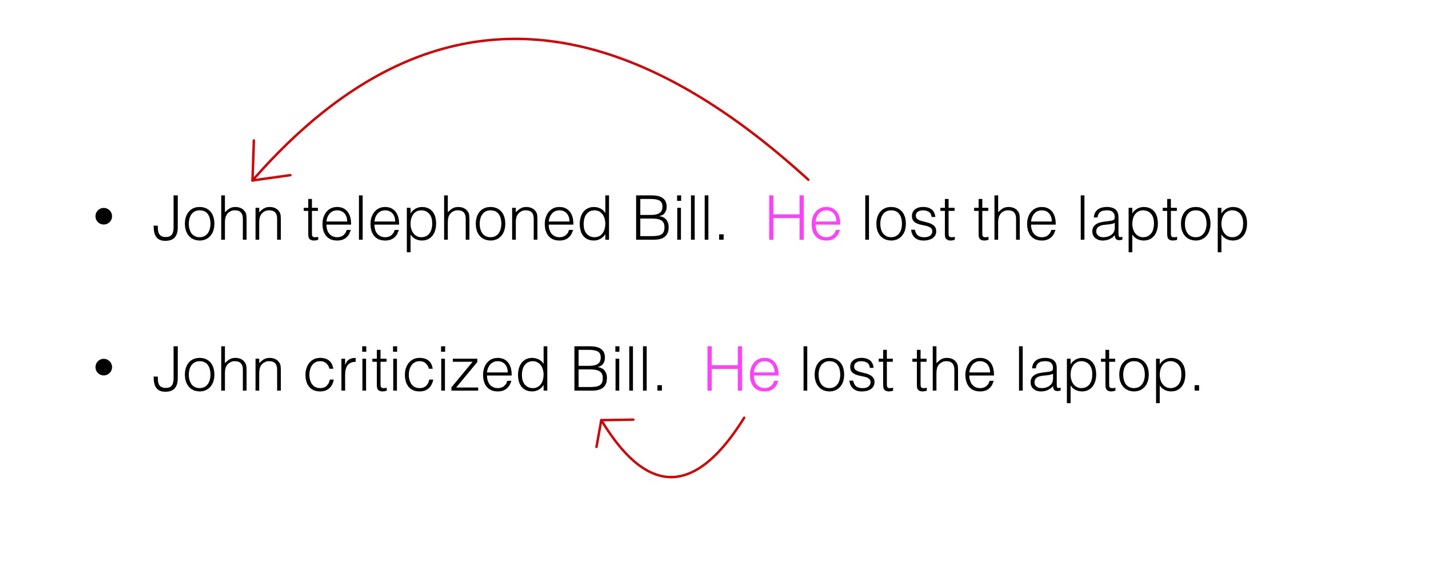
=> 지칭하는 대상이 다를 수도 있다.
Selectional restrictions

=> 파란색 동그라미 = mention
Mention Detection
- Mention 후보들을 다 뽑아놓기 (고유명사 후보를 뽑기)
- All NPs, possessive pronouns, and named entity mentions are candidate mentions. Recall is more important that precision -> 재현율이 정밀도 보다 더 중요하다.
Mention 방법 : rule-base

=> 여러 단계의 filter 를 거쳐서 결과를 낸다.
=> Speaker Sieve : 화자, String Match : John-John, Relaxed String Match : 애칭, Strict Head Match B,C : 같은 문장 구조
Mention-ranking models

=> 처음부터 끝까지 내려가면서 link 인지 not-link인지 확인하면서 classification 한다.

- The core machinery in a mention-ranking model is parameterizing the probability of a link between two mentions
Featurized
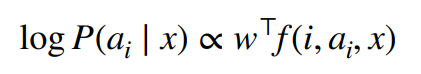
=> i : feature, ai : mention, x : input
- Features use information about the mention type(nominal, proper, pronoun), first/last word of mention, complete mention string, words immediately to left/right of mention, distance between mentions.
- Decision to link to antecedent ai is based on a linear scoring function involving a set of learned weights w and a feature function f.
- Mention 과 input의 연관성을 볼 건데, 여러 feature를 넣어주고 weight 를 조정해준다.
Neural coref
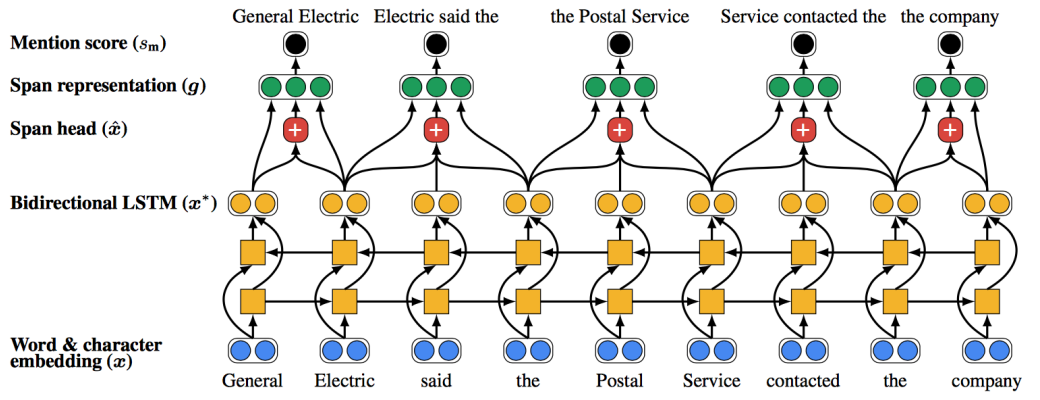
=> LSTM : 순차적으로, 두 Mention이 연결됐는지 아닌지 확인한다.
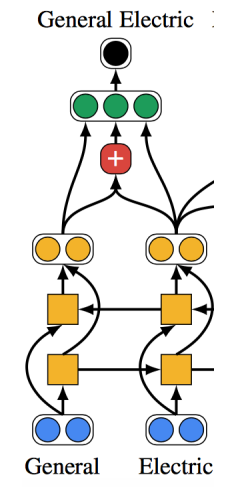
- Representation for mention =
- BiLSTM output for first token in mention
- BiLSTM output for last token in mention
- Attention over BiLSTM output for all tokens in mention
- Features : size of the mention
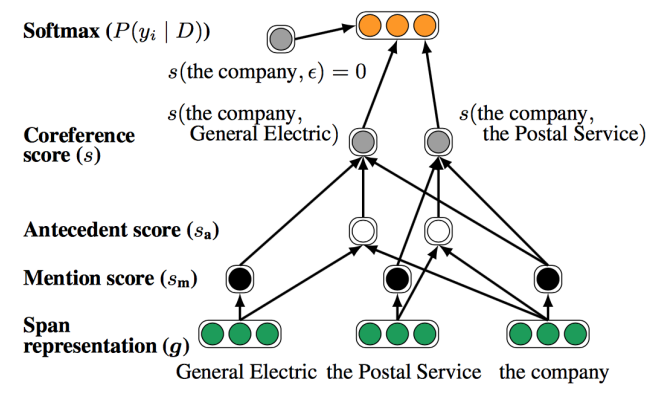
- Representaion for mention pair (mi, mj) :
- mi representaiton gi
- mj representation gj
- elementwise
product of gi and gj
- Features scoped over pair : distance between mi and mj
=> LSTM의 여러 과정을 score 매겨서 softmax 로 classification 한다.


=> 0 ~ 8 로 갈수록 distance가 멀어짐 - 그 때마다 weight parameter
[참고]
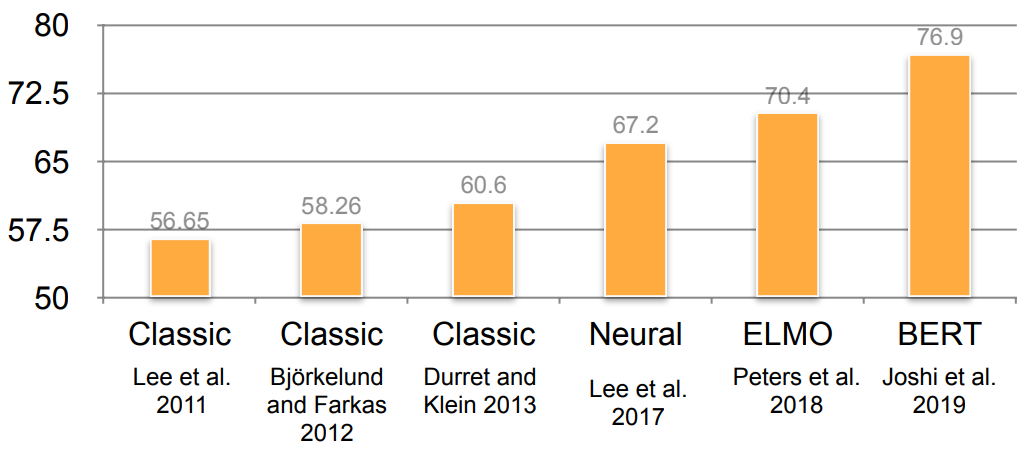
Evaluation
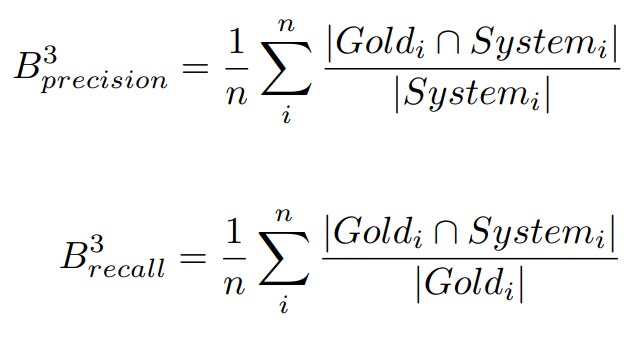
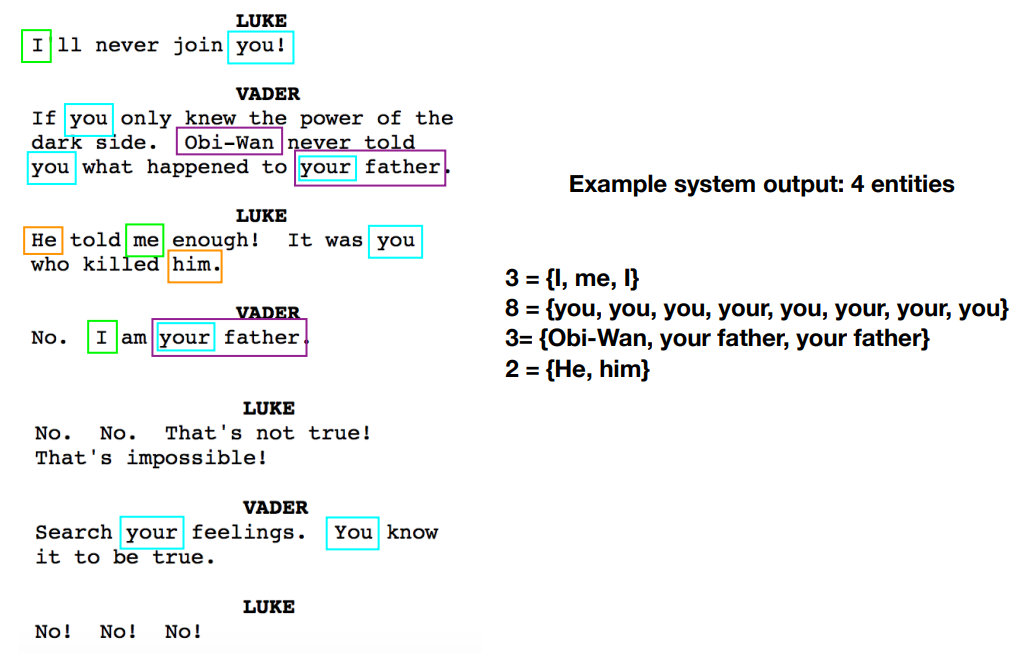

=> 왼쪽이 예측, 오른쪽이 정답 -> 하나씩 내려가면서 정확도/정밀도 등 평가

데이터사이언스와 자연어처리를 공부하고 있습니다.