
Classification
- h(x) = y

- Supervised learning

[참고]

[참고]
감성 사전 : <x,y> pair 를 넣어서 h를 학습시켜 놓은 것
우리는 이 감성 사전을 이용해서 h를 학습시키고, classification 하면 됨

Why SA is hard?
-
Sentiment as tone -> 시간에 따라 변하는 것
-
Sentiment is a measure of a speaker's private state, which is unobservable. -> 사적 상태를 알 수 없다.
-
Sometimes words are a good indicator of sentiment; many times it requires deep world + contextual knowledge-> 문맥적 지식 ( 반어법, 풍자 )를 알아야 한다.
어떻게 Classification function 을 학습시킬 것인가?
-
x는 representation of the data 이어야 한다. 즉, vectorization 된 word를 input으로 넣어준다.
-
어떤 수학적 Model 을 주고 학습하게 할 것인가?
- Naive Bayes 모델, logistic regression, convolutional neural network, etc... 에 따라 달라진다. (이번 시간은 Naive Bayes 모델을 이용한 classification function에 대해서 볼 것이고, 다음 번에는 logistic regression, convolutional neural network 를 각각 볼 것이다.)

Naive Bayes 모델로 h를 학습시키는 방법 : Discriminative models
- Naive Bayes
-
Given access to <x,y> pairs in training data, we can train a model to estimate the class probabilites for na new review.
-
With a bag of words representation, we can use Naive Bayes
-
Probabilistic model; not as accurate as other models, but fast to train and the foundation for many other probabilistic techniques.
-
h햇을 학습하는 과정
- h햇을 학습하는 과정은 확률분포를 추정하는 과정과 같다.
- h햇이 어떤 확률분포를 따르는지 추정하는 과정이다.
- 최대가 되는 Likelihood 를 찾아내서 Bayes' Rule 을 이용하여 h햇을 학습시킨다.
우변(가능도, 사전확률)을 이용해서 training 시키고 좌변(사후확률)을 이용해서 testing 한다.


Naive Bayes' 방법으로 h햇을 학습시킬 때 bag of words 를 이용해서 한다. bag of words 는 단순히 단어의 개수만을 나타내기 때문에 h햇을 학습시킬 때 개수가 많은 단어가 더 강한 영향을 끼칠 수 있다. 이런 일을 방지하기 위해 단어의 개수가 아닌 단어의 존재 유무를 h햇을 학습시킬 수도 있다.
[참고]

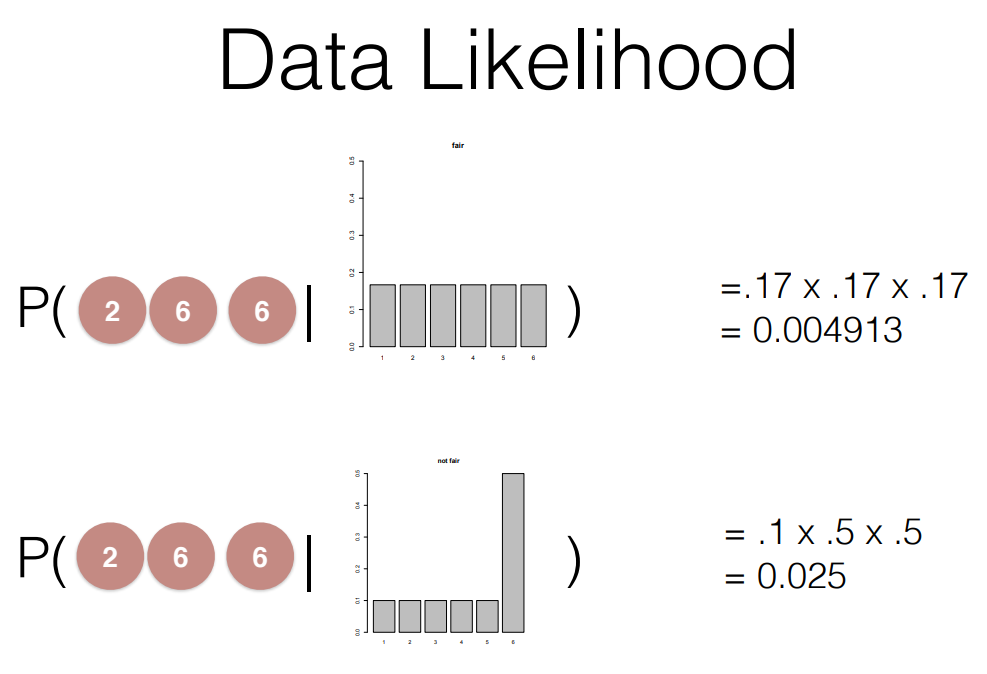
[참고]
서로 독립이라고 가정하고 h를 학습시키기 때문에 확률분포가 0인 부분이 있으면 전체 확률이 0이 된다. Smoothing 이라는 방법을 통해서 각 확률분포에 약간의 확률 값을 더해준다. Smoothing 의 종류에는 MLE 등이 있다.
Naive Bayes 모델로 h를 학습시키는 방법 : Generative models
- Generative models specify a joint distribution over the labels and the data. With this you could generate new data.
- P(X, Y) = P(Y)P(X|Y) -> 순서에 따라 다음에 올 확률이 가장 높은 X는?
- 별로 효과적이지는 않다.
- Generation 으로 이런 결과를 만들어 낼 수 있다.

출처 : https://people.ischool.berkeley.edu/~dbamman/nlp21.html
