
Logistic regression 모델로 h를 학습시키는 방법 : Classification
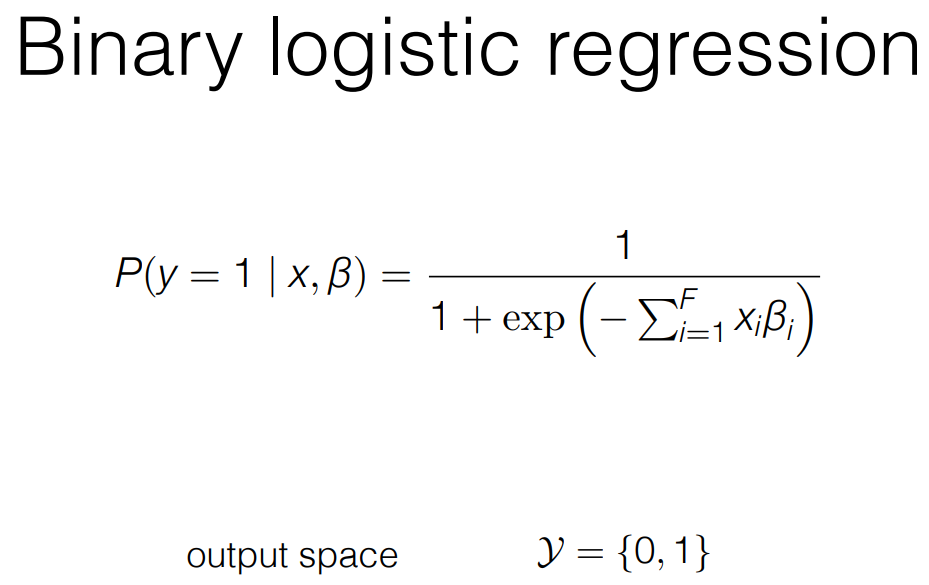
- 확률이 0이 되는 것을 막기 위해서 BIAS를 주고 이런 방식으로 h햇을 학습시킨다.
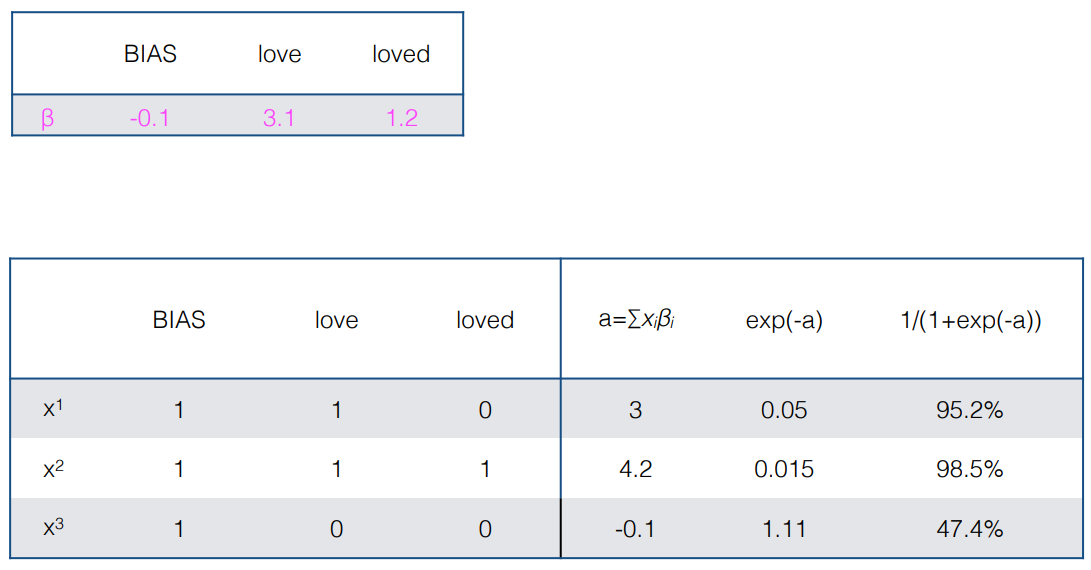
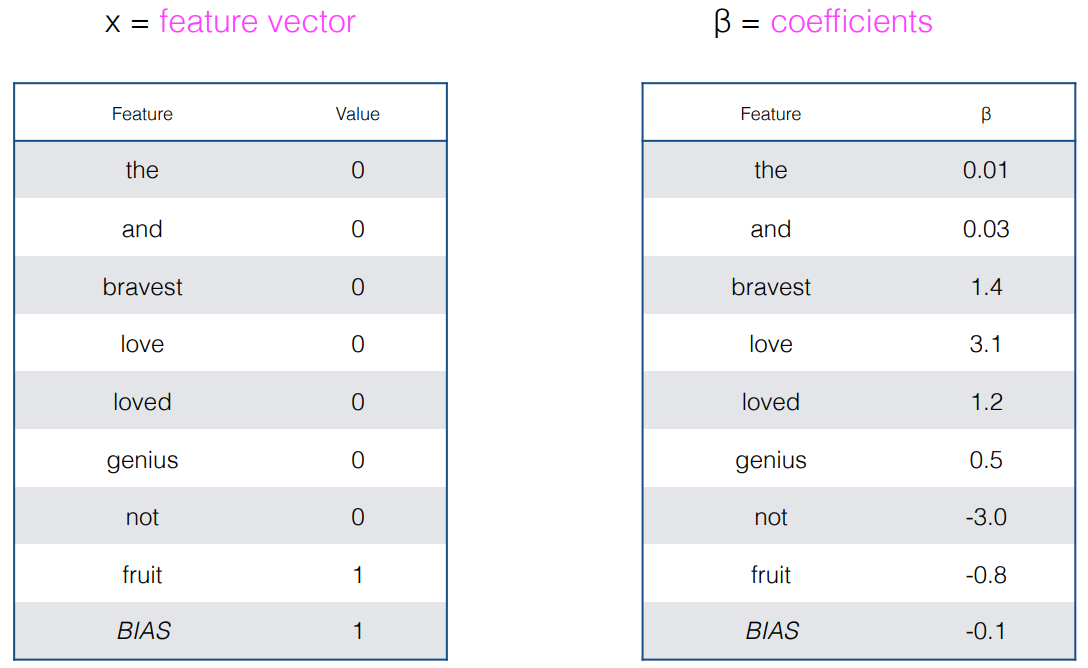
[참고]
- Features
- As a discriminative classifier, logistic regression doesn't assum features are independent like Naive Bayes does. -> 독립X
- Its power partly comes in the ability to create richly expressive features without the burden of independence.
- We can represent text through features that are not just identities of individual words, but any feature that is scopred over the entirety of the input
- Features are where you can encode your won domain understanding of the problem. ( unigram, bigram .. ngram, prexies(words that start with "un-", has word that shows up in positive sentiment dictionary)
- 단어의 단순한 유무 말고, input에 대한 정보 추가가 가능하다.
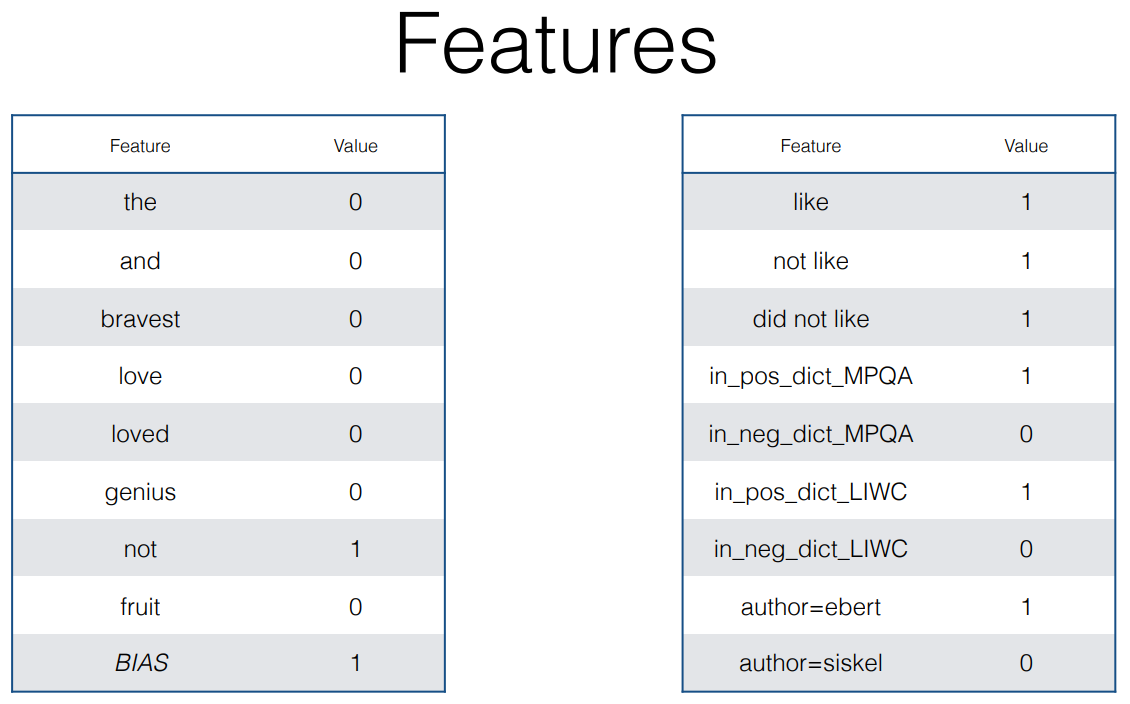
[참고]
Conditional likelihood
- For all training data, we want the probability of the true label y for each data point x to be high
- This principle gives us a way to pick the values of the parameters β that maximize the probability of the training data
<x,y> -> y를 잘 근사하기 위한 파라미터 β를 잘 설정해야 한다.
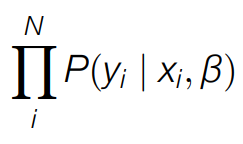
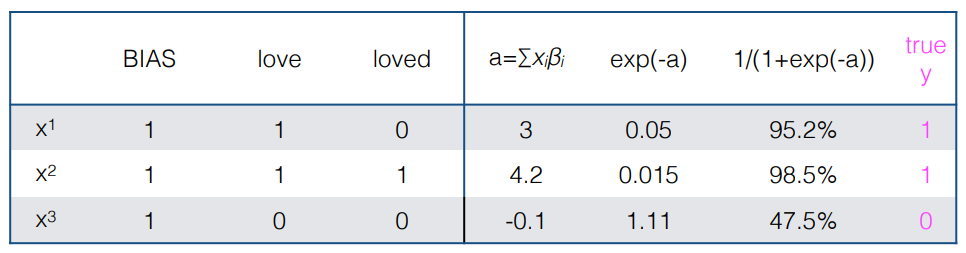
[참고]
β
- The value β of that maximizes likelihood also maximizes the log likelihood (최대우도법)
- log 를 사용하면 확률값을 다룰 때 더 용이하다.
- 이렇게 β 값을 최적화 하는 과정에서 기울기 감소 문제가 발생할 수 있다. -> lr 을 잘 조정해서 극복할 수 있다.
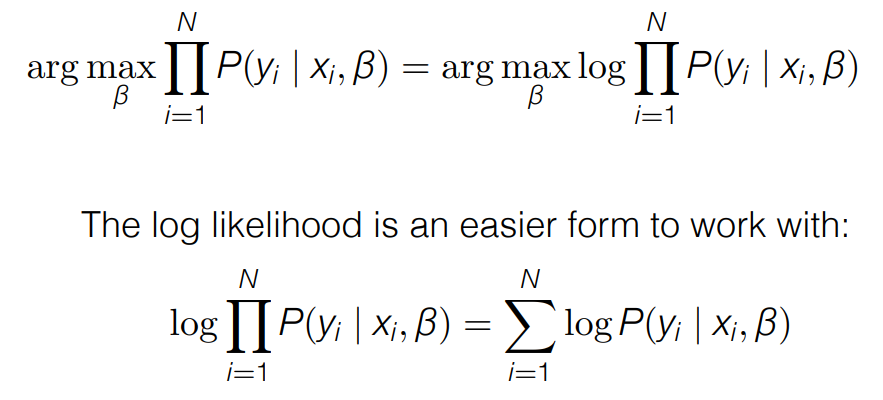
문제점
- β 값을 최적화 하는 과정에서 기울기 감소 문제
- Calculate the derivative of some loss function with respect to parameters we can change, update accordingly to make predictions on training data a little less wrong next time.
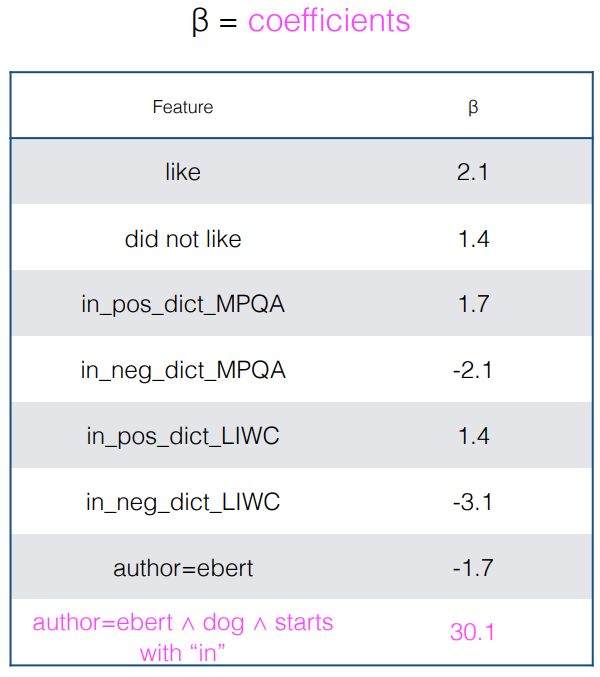
- 상대적으로 그다지 중요하지 않은 feature 들이 영향을 크게 줄 수도 있다.
문제 해결
- We could threshold features by minimun count but that also throws away information
- We can take a probabilistic approach and encode a prior belief that all β should be 0 unless we have strong evidence otherwise
- 포괄적으로 문장을 설명할 수 있도록 한다. (너무 자세하지 않게)
- L2 regularization -> feature 복잡도를 낮춘다.
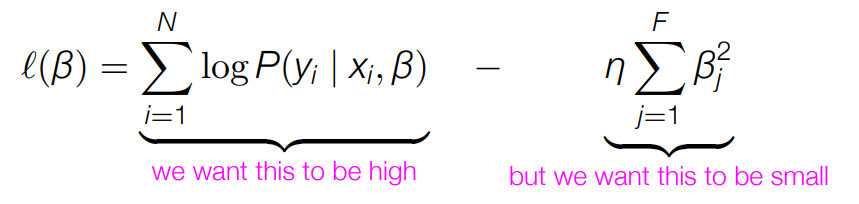
- L1 regularization -> 필요없는 feature 는 0으로 바꿔버린다.
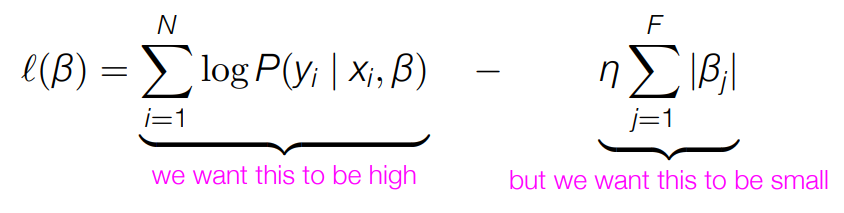
출처 : https://people.ischool.berkeley.edu/~dbamman/nlp21.html

데이터사이언스와 자연어처리를 공부하고 있습니다.