
Neural Networks
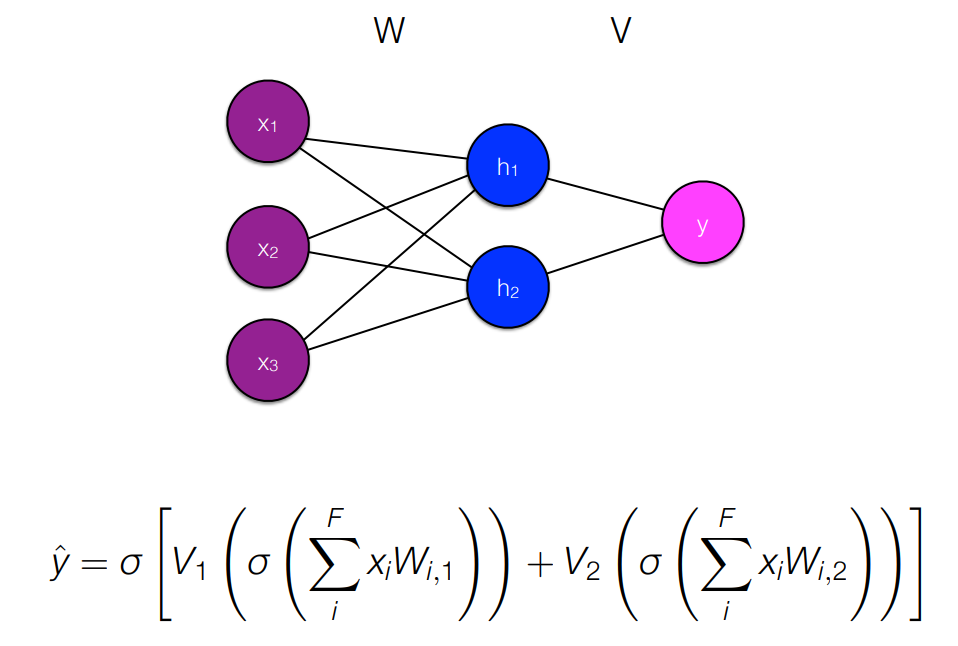
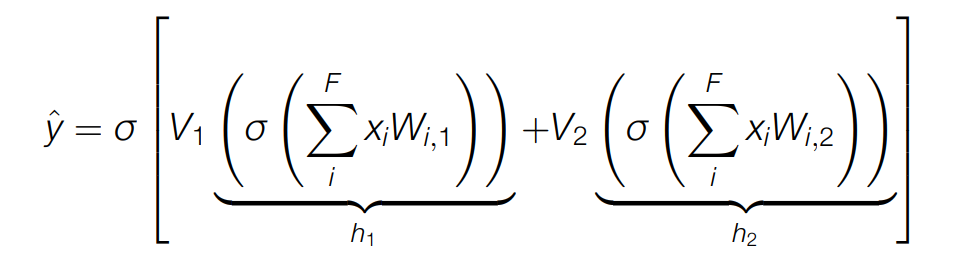
- Prediction 과 Backpropagation 의 반복이다. 처음에 Weight 값을 임의의 값으로 설정하고 y-y햇이 최소화되게끔 업데이트한다.
[참고]
- Discrete, high-dimensional representation of inputs (one-hot vectors, indicator vector) -> low-dimensional distributed representation
- Static representation -> contextual representations, where representations of words are sensitive to local context
- Non-linear interactions of input features
- Multiple layers to capture hierarchical structure
[참고]
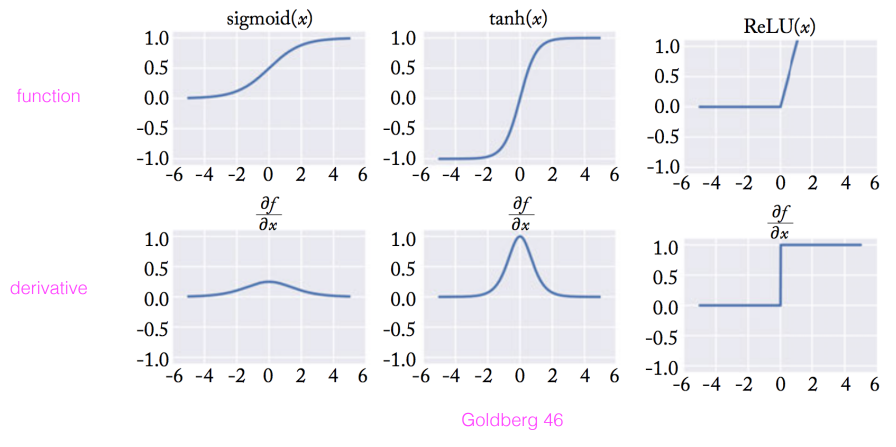
Activation function : 앞에서 주어진 신호를 다음 레이어로 보낼지 말지 결정
- y-y햇 즉, 오차를 줄여나가는 과정에서 기울기 소멸 문제가 발생한다. 이 때 LeLU 함수를 활성화 함수로 사용하면 기울기 소멸 염려도 없다. 또한 가장 대중적이고 속도가 빠르다.
- ReLU and tanh are both used extensively in modern system.
- Sigmoid is useful for final layer to scale output between 0 and 1, but is not often used in intermediate layers
Neural Networks 의 장점
- Tremendous flexibility on design choices (exchange feature engineering for model engineering) -> Model을 바꾸기 쉽다.
- Articulate model structure and use the chain rule to derive parameter updates
문제점
-컴퓨터로 무한정 노드를 늘릴 수가 있다. 하지만 쓸 데 없고 상대적으로 덜 중요한 곳에 계산을 사용하지말고 필요한 x에 β를 잘 (적당히) 할당할 수 있게 해야한다.
- Regularization : Increasing the number of parameters = Increasing the possibility for overfitting to training data -> 과대적합을 막기 위해서 규제를 한다.
1) L2 Regularization
2) Dropout : When training on a <x,y> pair, randomly remove some node and weights
3) Early stopping : Stop backpropagation before the training error is too small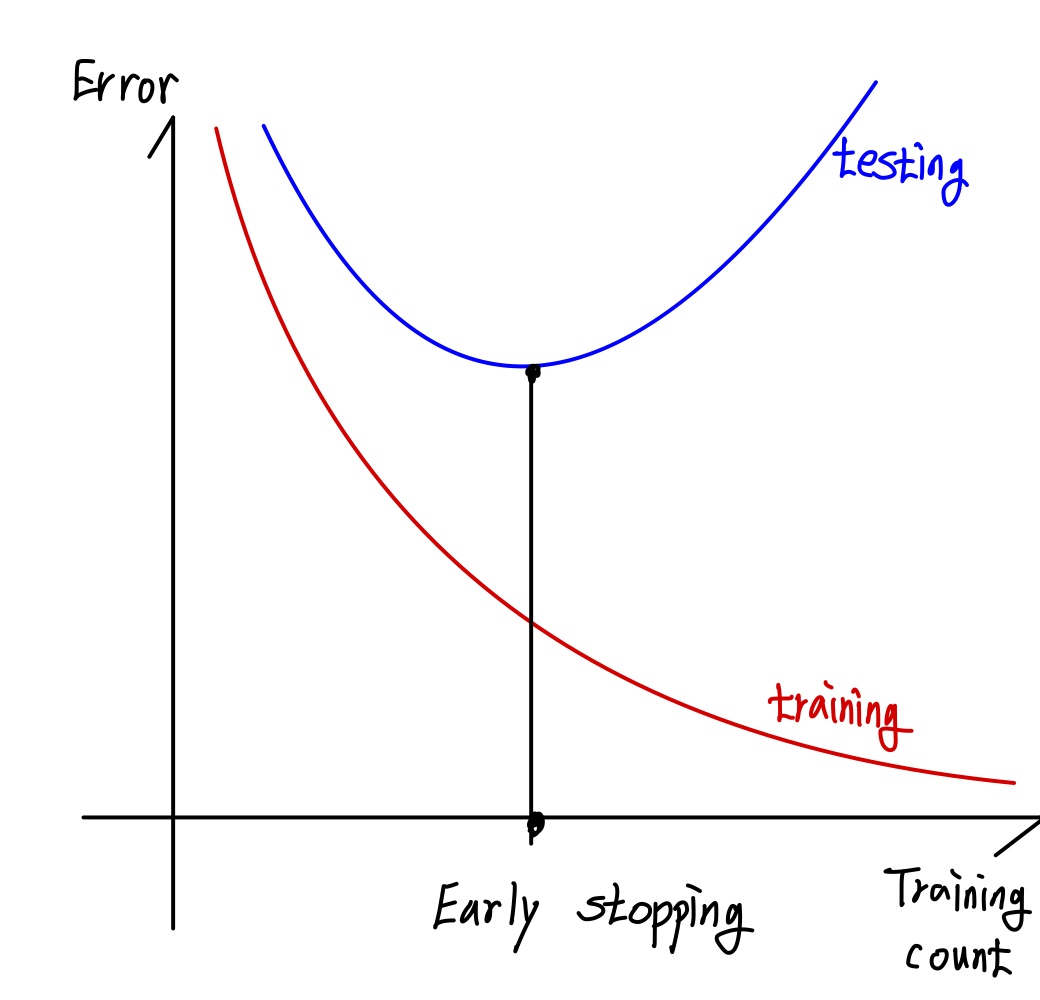
Neural Networks 를 이용한 여러 가지 h를 학습시키는 방법 : Classification
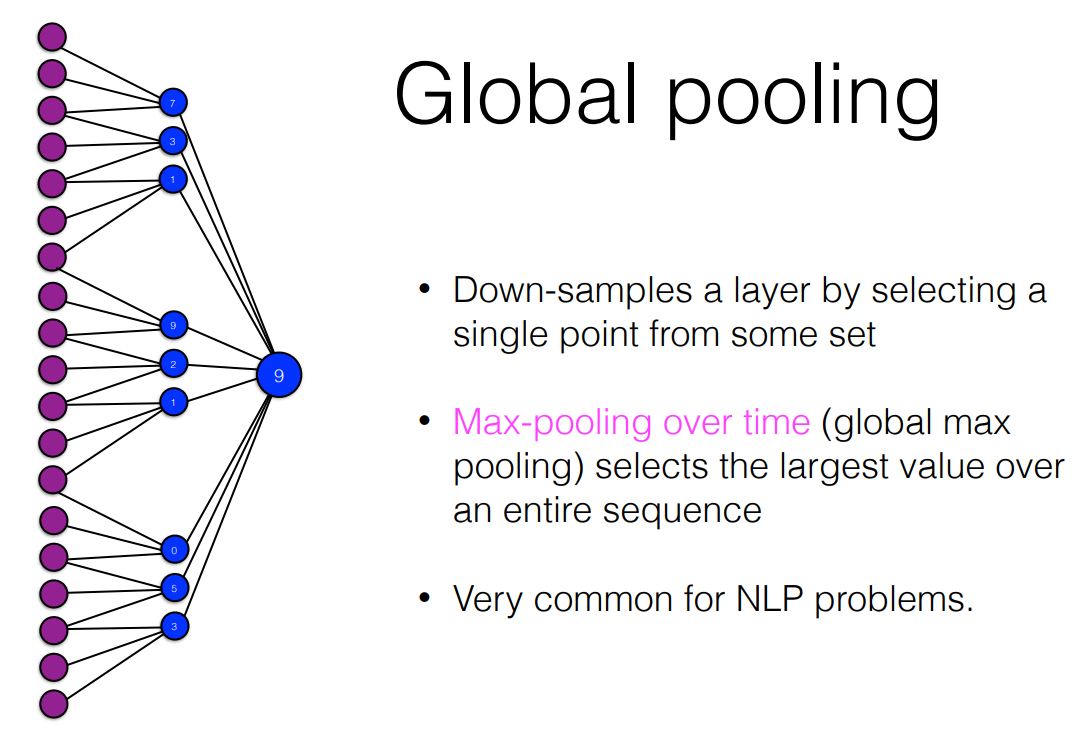
- 다 계산하면 복잡하니까 hidden-layer의 큰 값만 뽑아내서 진행

- 모든 hidden layer에서 가장 큰 값으로 진행
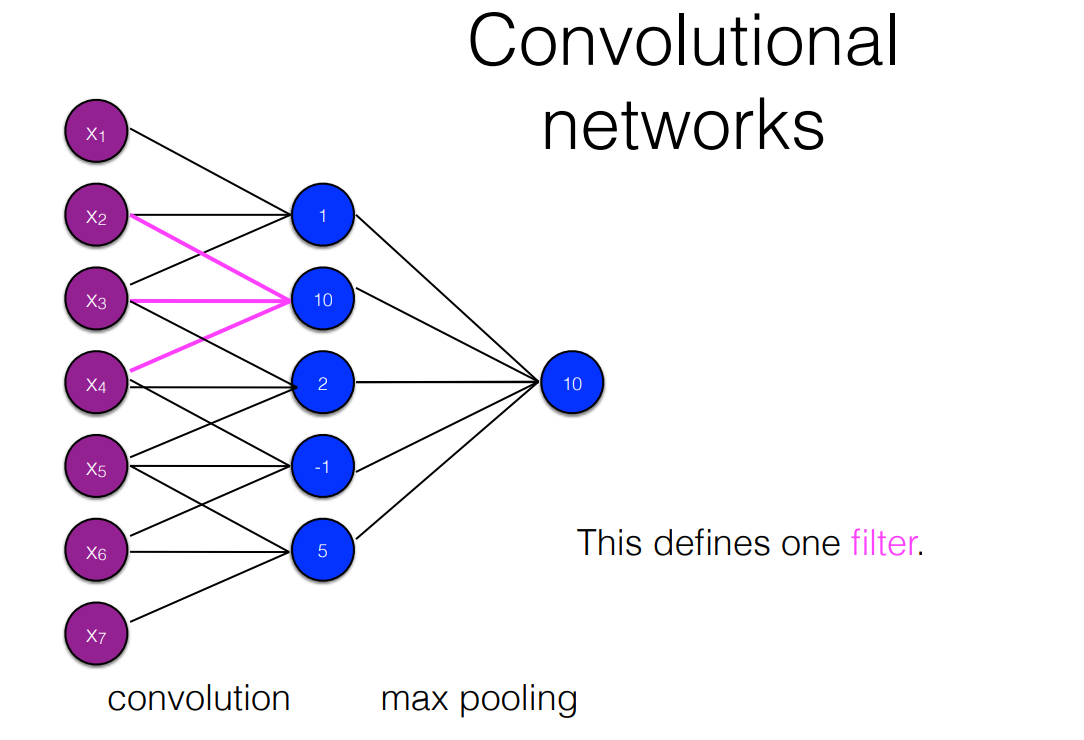
- CNN
- We can specify multiple filters; each filter is a separate set of parameters to be learned
- With max pooling, we select a single number for each filter over all tokens
- If we specity multiple filters, we can also scope each filter over different window sizes
출처 : https://people.ischool.berkeley.edu/~dbamman/nlp21.html

데이터사이언스와 자연어처리를 공부하고 있습니다.