
Language Model
-
Language models provide us with a way to quantify the likelihood fo a sequence -- i.e., plausible sentences. -> 말이 되면 확률값이 높다.
-
P("Call me Ishmael") = P(w1 = "call", w2 = "me", w3 = "Ishmael") X P(STOP) -> v+ is the infinite set of sequences of symbols from v; each sequence ends with STOP
-
Language modeling is the task of estimating P(w)
-
예시
1) OCR : Image to Text ( Optical character recognition )
2) Machine translation -> 1. 원본의 문장을 얼마나 추실하게 전달했느냐(충실도, Fidelity to source text) 와 2.번역된 게 얼마나 정확하냐(Fluency of the translation) 를 본다.
3) Query auto completion : 검색어 자동완성 ( 확률이 높은 순서대로 나열 )
4) Speech recognition -> 시리, 빅스비, 아리아, 알렉사, ...
Markov assumption : Estimation
- 현재 혹은 다음에 올 상태는 이전의 상태(단어)들에 의해 결정된다.
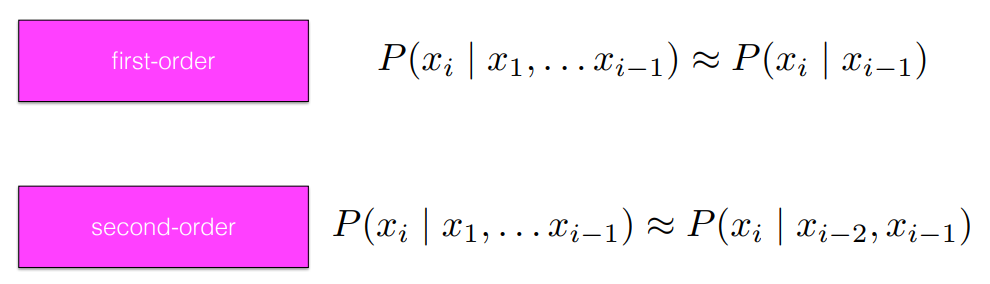
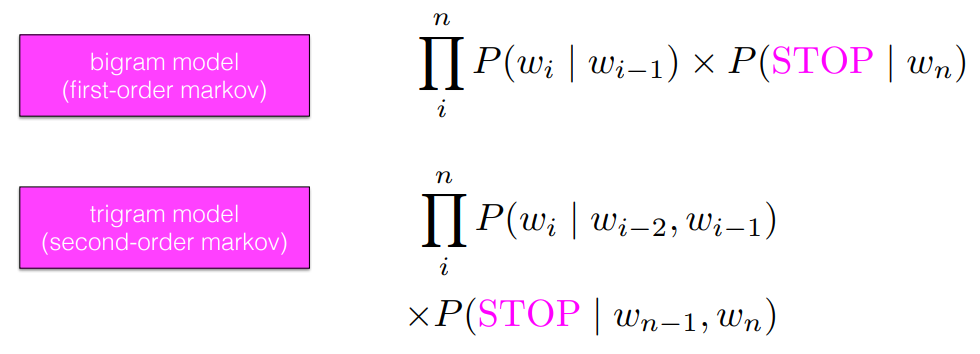


Markov assumption : Generating
- 어떤 단어 다음에 특정 단어가 나올 확률을 Language model을 통해서 미리 계산해서 둔다.
- What we learn in estimating languege models is P(word | context), where context -- at least here -- is the previous n-1 words
- We have one multinomial over the vocabulary (including STOP) for each context
- LM 또한 확률분포를 다루기 때문에 확률분포 값이 0이 되는 곳이 있다면 전체 확률이 0이 된다. 따라서 Smoothing 을 통해서 해결한다. -> How can best re-allocate probability mass가 또 하나의 이슈이다.
Interpolation
- As ngram order rises, we have the potential for higher precision but also higher variablilty in our estimates. -> ngram에서 n이 커질 수록 정확도가 커지지만 다양성이 늘어난다.
- A linear interpolation of any two language models p and q is also a valid language model -> 여러 모델을 비중을 다르게 하여 동시에 사용할 수도 있다. (예1. p= bigram, q= trigram / 예2. p = the web, q = pollitical speeches) ..
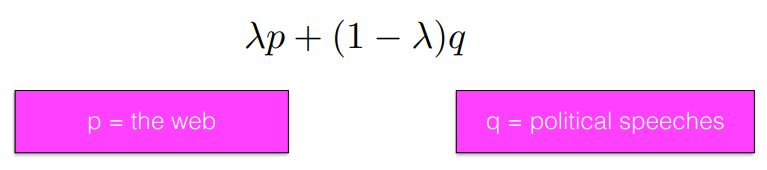
- 꼭 2개가 아니고 더 많은 개수를 같이 쓸 수도 있다.
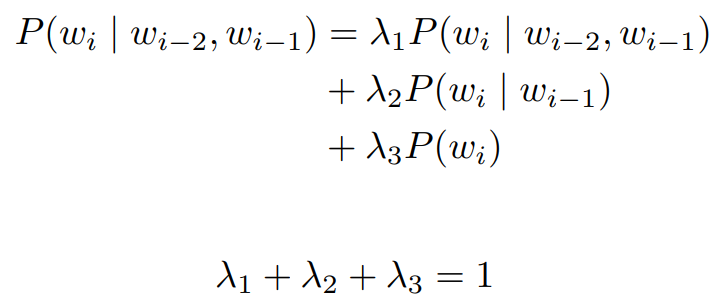
- how do we pick the best values of λ? : λ -> 사람이 개입해서 바꿀 수 있다. hyper parameter
1) Grid search over development corpus
2) Expectation-Maximization algorithm
여러 가지 LM 모델들
- Unigram, bigram, trigram, 4gram model, ..
Evaluation
- The best evaluation metrics are external - how does a better language model influence the application you care about? -> 외부의 특정 조건 (Accuracy, Precision, ... 등등 외부 지표가 좋다)
- Speech recognition (word error rate), machine translation (BLEU score) topic models (sensemaking) -> BLEU 스코어 : 번역이 잘 되었는지 평가하는 외부 지표
- A good language model should judge unseen real language to have high probability
- Perplexity = inverse probability of test data, averaged by word
- To be reliable, the test data must be truly unseen
-> Perplexity 는 외부 지표가 없을 때 사용할 수 있는 지표인데, test set으로 검증했을 때 확률이 높아야 한다. 꼭 test set 으로 검증해야 한다.
- perplexity 는 Generation의 성능을 판단하는 지표로 낮을 수록 좋다.
- ngram에서 n이 커질 수록 perplexity 가 낮아진다.
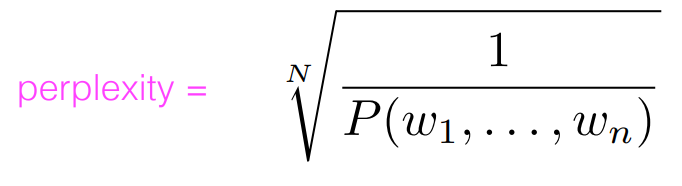
출처 : https://people.ischool.berkeley.edu/~dbamman/nlp21.html
