웹 크롤링의 뼈대는 앞선 포스팅을 통해 알아보았으니, 이번엔 웹 데이터를 어떻게 가져오고 선별은 어떻게 하는지를 알아보도록 하겠다.
우선, 웹 페이지가 무엇인지 대략적으로 알아야 웹페이지에 있는 특정데이터를 가져올 수 있을 것이다.
웹페이지
그렇다면, 웹페이지는 무엇일까?
개발을 찍먹이라도 해본 분이라면 다들 HTML, CSS, JS가 웹페이지의 3요소라는 사실은 다들 알 것이다.
건물로 비유하자면,
철근콘크리트 - HTML
익스테리어 및 인테리어 - CSS
상하수도, 전기, 가스, 엘레베이터 - JS
라고 이해하면 쉬울 것이다.
HTML이 웹페이지의 뼈대를 이루고, CSS는 웹페이지의 디자인을 컨트롤하는 데 쓰이며, JS는 웹페이지가 돌아가게끔 하는 로직을 담당하는 것이기 때문에 이 세가지가 모두 유기적으로 구성되어 하나의 웹페이지를 만드는 것이라고 보면 된다.
그렇다면 우리는 어디에서 데이터를 긁어오면 되는 것인가?
바로 HTML이다.
HTML
HTML에 대해서 부가적인 설명을 덧붙이자면, HTML이란 다음과 같다.
Hyper Text Markup Language의 약어.
www(world wide web)을 구성하는데 사용하는 국제표준 언어로서 컨텐츠와 레이아웃을 담는 언어
즉 하이퍼텍스트 언어로 각종 컨텐츠들이 담긴 레이아웃을 만드는 언어다.
HTML을 살펴보면 웹페이지가 담고 있는 정보가 어디에 있는지 찾을 수 있다.
HTML의 구성은 다음과 같다.
<tag> contents </tag>
e.g. <span class="stock\_price" id="003212"> 20,122 </span>셀렉터
그렇다면, 우리는 저 contents를 어떻게 가져올 수 있을까?
HTML의 컨텐츠를 선별해서 가져올 수 있도록 해주는 것이 바로 파이썬의 BeautifulSoup.select함수다.
해당 함수에 tag로 구성되어 있는 셀렉터를 Input으로 넣어 그곳의 contents를 가져와주는 함수다.
그렇다면, 셀렉터가 무엇인지 알아야 적용하고 데이터를 수집할 수 있다는 뜻이다.
셀렉터의 종류는 다음과 같다.
단일 셀렉터 [e.g. html.select('span')]
: 말 그대로 단순히 태그만 가지고 그 안의 정보를 긁어오는 방식이다.복합셀렉터(클래스 포함 셀렉터) [e.g. html.select('span.txt')]
: 태그 중에서 별도의 클래스를 가지는 것들의 내용만 담고 싶을 때 사용한다.복합셀럭터(id 포함 셀럭터) [e.g. html.select('span#1234')]
: 태그 중에서 별도의 id를 가지는 내용만 담고 싶을 때 사용한다.경로 셀렉터 [e.g. html.select('div.table > ul > li > em#1234') 또는 html.select('div.table ul li em#1234')]
: 일반적으로 html은 한 컨텐츠를 찾기 위해선 여러 태그를 거쳐서 접근해야 하는 경우가 많다.
이럴 때 각 태그의 hierarchy를 맞춰 복합셀렉터를 나열하면 된다.
컨텐츠를 가져오기 위해서는 셀렉터를 이용해야 한다는 것은 이제 알게 되었다.
그렇다면 그 컨텐츠가 어느 셀렉터에 있는지는 어떻게 알 수 있을까?
결국, HTML 내부를 뜯어봐야 알 수 있다.
그렇다면 웹페이지의 HTML 코드는 어떻게 보고 셀렉터는 어떻게 구성할 수 있을까?
웹페이지의 HTML 코드 확인하기
요즘 웹 브라우저 업계 1위를 당당히 차지하고 있는 것이 바로 Chrome이다.
Google이 만든 웰메이드 웹 브라우저다.
우리는 이 Chrome을 활용하여 HTML을 확인할 수 있다!
우선 네이버 스포츠 해외축구 탭의 메인 뉴스 기사 제목을 수집하기로 했다고 하자.
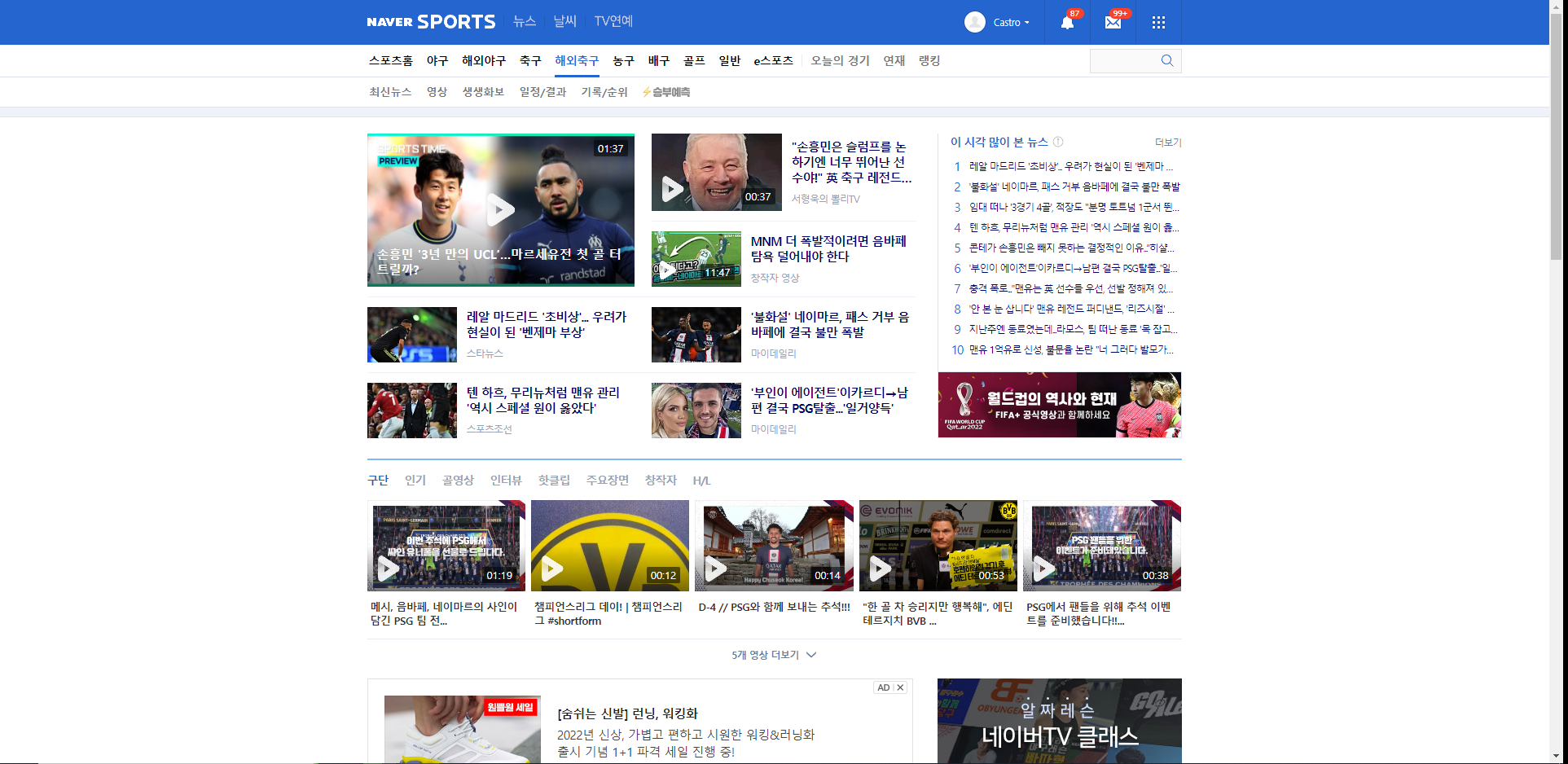
지금 레알 마드리드가 벤제마의 부상으로 '초비상'이라는 기사가 눈에 띈다 ㅠㅠ(필자는 참고로 레알마드리드 12년차 팬이다)
눈물을 머금고 저 기사 제목의 html 상의 위치를 확인해보자.
텍스트 위에 마우스를 올린 후 우클릭을 한 후 '검사' 버튼을 누르면 다음과 같은 개발자도구 화면이 뜬다.
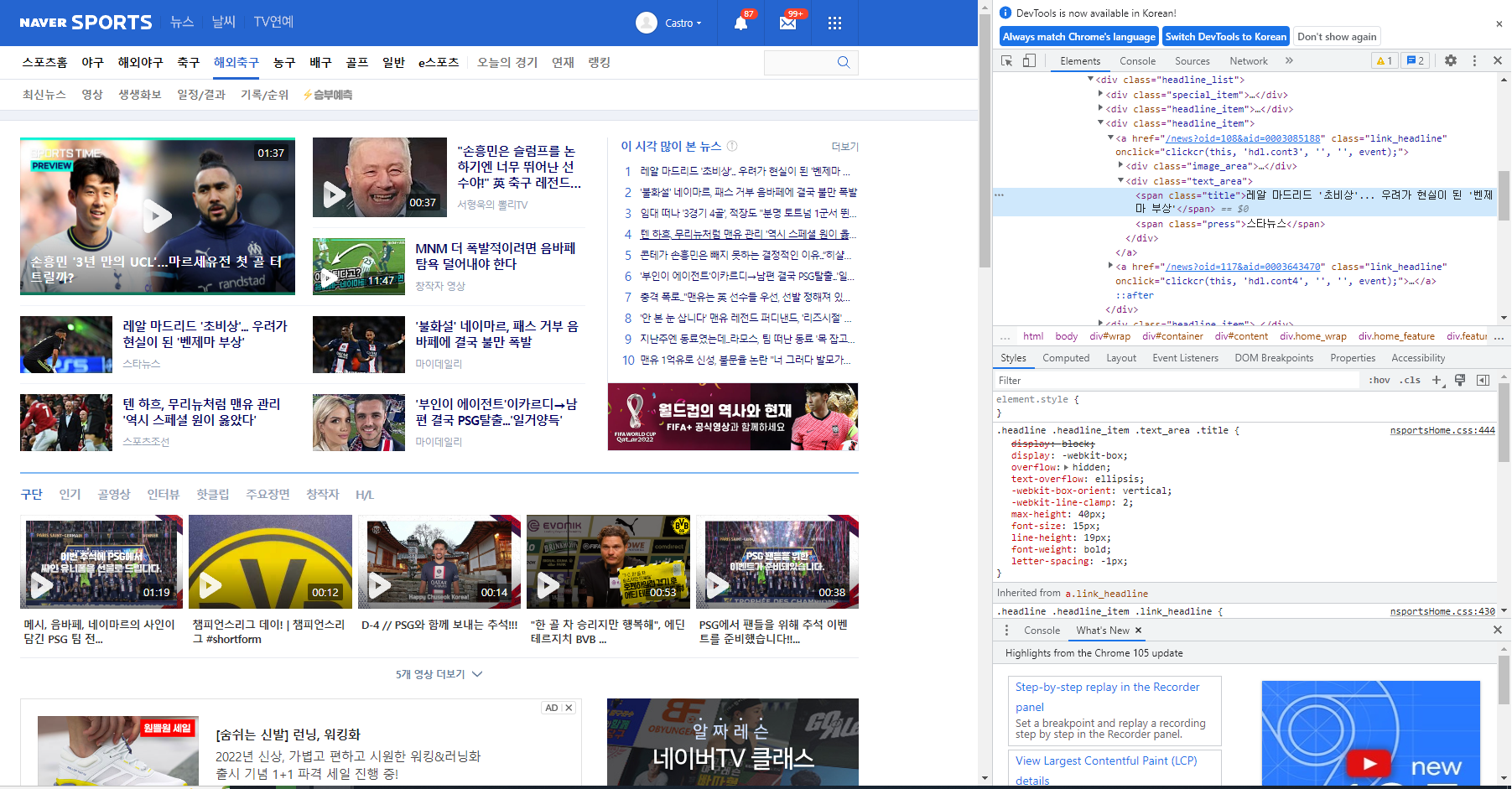
<span class="title">레알 마드리드 '초비상'... 우려가 현실이 된 '벤제마 부상'</span>
이라는 html 코드가 뜰 것이다.
이 부분을 우클릭하여 copy > copy selector 를 하면,
#content > div > div.home_feature > div.feature_main > div > div > div:nth-child(3) > a:nth-child(1) > div.text_area > span.title
이런 텍스트가 복사되는 것을 확인할 수 있다.
이것이 바로 저 뉴스 제목의 셀렉터다.
import requests
from bs4 import BeautifulSoup
# url정의
url = 'https://sports.news.naver.com/wfootball/index'
# requsts로 url에 정보요청
resp = requests.get(url) # url로 로컲컴퓨터에서 데이터를 요청하는 작업
# 정보를 html 변환 (보기 쉽게)
html = BeautifulSoup(resp.text, 'html.parser')
# html 내에서 우리가 보고 싶은 정보만 선별
html.select('#content > div > div.home_feature > div.feature_main > div > div > div:nth-child(3) > a:nth-child(1) > div.text_area > span.title')셀렉터를 활용하여 위 코드를 통해 뉴스 제목을 불러올 수 있다.
이것이 웹페이지 크롤링의 기본이라고 할 수 있겠다!
그럼 다음 시간에는 URL의 패턴을 가지고 여러 페이지의 데이터를 수집하는 '패턴 URL 크롤링'에 대해서 알아보도록 하자.
