크롤링 연습에 가장 좋은 것이 바로 주식 데이터 불러오기다.
동학개미로서 참을 수 없었기 때문에 KOSPI 전종목을 불러오는 코드를 통해 실습을 진행해보았다.
코드를 하기 전 준비물은 전종목 kospi 종목코드다.
kospi 종목코드에 관한 정보는 KRX 정보데이터시스템에서 csv로 추출하여 가져왔다.
종목코드를 기준으로 종목 정보는 네이버 금융에서 크롤링했다.
코드는 다음과 같다.
import time
import requests
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
stocklist = pd.read_csv("data_1607_20220906.csv", ',', encoding='CP949')
stock_codes = list(stocklist['종목코드'])
df = pd.DataFrame()
for code in stock_codes:
a = np.random.randint(3)
time.sleep(a+1)
# url 정의
url = f"https://finance.naver.com/item/main.naver?code={code}"
# requests 요청
resp = requests.get(url)
# html 변환
html = BeautifulSoup(resp.text, 'html.parser')
# 종목명
stock = html.select('div.wrap_company a')[0].text
print(f"<{stock}>")
try:
price = html.select('p.no_today')[0].text.strip().split('\n')[0]
print("{}의 현재가는 {}원 입니다.".format(stock, price))
price = int(price.replace(',', ''))
except:
print("{}의 현재가는 N/A원 입니다.")
price = np.nan
# 시가총액, 외국인소진률, PER, PBR
# 시가총액
try:
market_sum = html.select('em#_market_sum')[0].text.strip().split()
if len(market_sum) == 1:
print(f"{stock}의 시가총액은 {market_sum[0]}억원 입니다.")
if len(market_sum[0]) <= 3:
ms = int(market_sum[0])
else:
ms = int(market_sum[0].split(',')[0]) * 1000 + int(market_sum[0].split(',')[1])
else:
print(f"{stock}의 시가총액은 {market_sum[0] + ' ' + market_sum[1]}억원 입니다.")
if len(market_sum[1]) <= 4:
ms = int(market_sum[0][:-1]) * 10000 + int(market_sum[1])
else:
ms = int(market_sum[0][:-1]) * 10000 + int(market_sum[1].split(',')[0]) * 1000 + int(market_sum[1].split(',')[1])
except:
print(f"{stock}의 시가총액은 N/A원 입니다.")
ms = np.nan
# 외국인소진율(경로셀렉터)
try:
foreign = html.select('table.lwidth em')[2].text
print(f"{stock}의 외국인소진율은 {foreign} 입니다.")
frn = float(foreign[:-1])
except:
print(f"{stock}의 외국인소진율은 N/A% 입니다.")
frn = np.nan
# per
try:
per = float(html.select('table.per_table em#_per')[0].text)
print(f"{stock}의 PER은 {per}배 입니다.")
except:
print(f"{stock}의 PER은 N/A배 입니다.")
per = np.nan
# pbr
try:
pbr = float(html.select('table.per_table em#_pbr')[0].text)
print(f"{stock}의 PBR은 {pbr}배 입니다.")
except:
print(f"{stock}의 PBR은 N/A배 입니다.")
pbr = np.nan
print("=" * 50)
series = pd.Series([code, price, ms, frn, per, pbr], index=['종목코드', '현재가', '시가총액(억원)', '외국인소진율(%)', 'PER', 'PBR'])
df[stock] = series결과는 다음과 같다.
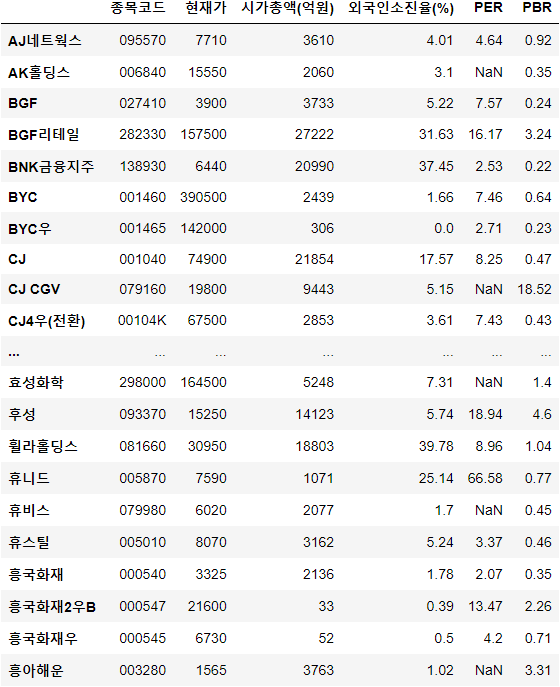
적자인 기업의 PER은 계산할 수 없기 때문에 그런 경우 예외처리로 NaN을 넣어 대체하였다.
이를 통해 알 수 있는 정보는 kospi에 적자인 기업이 꽤 많다는 점이다.
이런 식으로 파이썬을 통해 주식데이터를 분석하기 용이한 DataFrame 타입으로 저장하는 작업까지 진행해보았다.
다음번엔 업비트 Open API에서 코인 ohlcv정보 긁어오기에 도전해보도록 하겠다!
Adios!

데이터 사이언티스트를 꿈꾸는 3년차 제품총괄입니다.