크롤링 타겟 URL이 순서 또는 특정 규칙에 따라 페이지별로 바뀌는 부분을 이용해 반복문을 통해 다수의 페이지를 긁어오는 방식.
패턴 URL 크롤링은 가장 많이 쓰이는 크롤링으로 여러 페이지를 한번에 긁어오는데 상당히 유용한 방법이다.
로또 당첨 번호를 예시로 패턴 URL에 대해 알아보도록 하자.
네이버에 1031회 로또 당첨번호를 검색해보면,
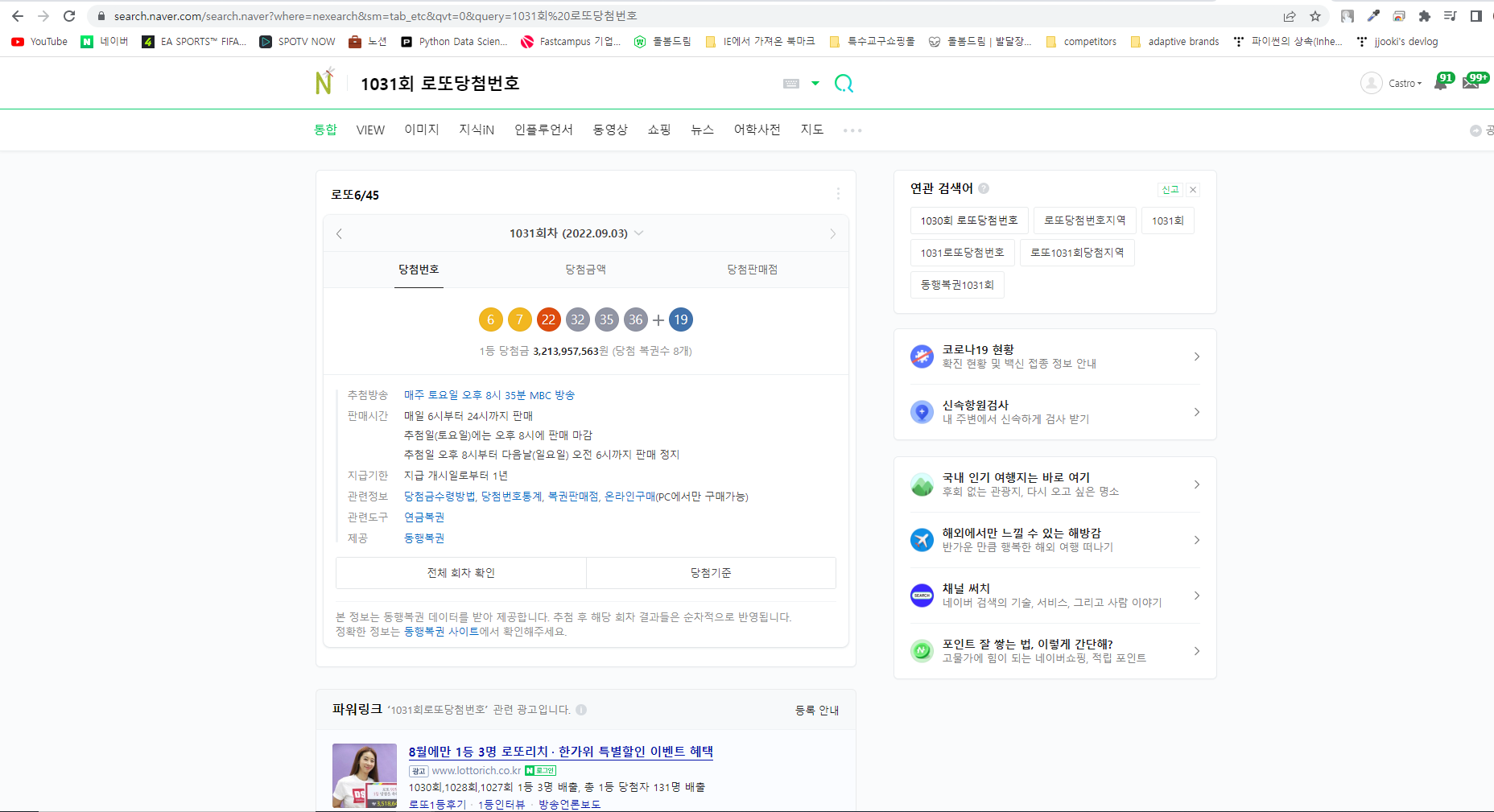
이런 화면이 나온다.
URL을 확인해보면
직전 회차인 1030회 당첨번호도 한번 확인해보자.
두 URL의 차이를 자세히 살펴보면, query= 옆에 나오는 숫자가 회차번호라는 사실을 유추할 수 있다!
그러면 지금까지 나온 로또 당첨번호를 1회차부터 쭉 크롤링할 수 있다는 뜻이다.
가설을 증명하기 위해 123회 로또 당첨번호를 query=123이 들어간 url을 통해 검색해보도록 하겠다.
123회 로또당첨번호가 검색된다!
앞선 포스팅에서 배웠던 방식으로 로또번호의 selector를 찾은 후 모든 당첨번호(+보너스번호)를 긁어오는 코드는 다음과 같이 짤 수 있다.
import pandas as pd
import time
import requests
from bs4 import BeautifulSoup
whole_lotto_num = pd.DataFrame()
for num in range(1,11):
lotto_num = []
a = np.random.randint(3)
time.sleep(a+1)
# url 설정
url = f'https://search.daum.net/search?nil_suggest=btn&w=tot&DA=SBC&q={num}%ED%9A%8C%EC%B0%A8+%EB%A1%9C%EB%98%90%EB%B2%88%ED%98%B8'
# requests로 데이터 요청하기
resp = requests.get(url)
# 정보를 html 변환 (보기 쉽게)
html = BeautifulSoup(resp.text, 'html.parser')
# 필요정보 선별
lotto = html.select('span.ball')
# DataFrame 저장
whole_lotto_num[f'{num}회차'] = pd.Series([int(item.text) for item in lotto if item.text != '보너스'], index=['1', '2', '3', '4', '5', '6', '보너스'])
whole_lotto_num.T.head()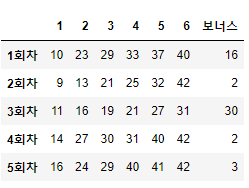
이렇게 데이터프레임으로 저장까지 하면, 데이터 가공도 손쉽게 할 수 있게 된다.
패턴 URL 크롤링을 활용하여 다음 포스팅에서는 KOSPI 전종목 주식데이터를 수집해보도록 하겠다.
Adios!

데이터 사이언티스트를 꿈꾸는 3년차 제품총괄입니다.