
[Model Predictive Control, Reinforcement Learning 을 이용한 자율주차 시스템]
목표 : Matlab의 Auto Parking Valet 예제 따라하며 공부해보기.
😊Automatic Parking valet Matlab Official
1.사전지식
MPC control : MPC는 현재 상태와 미래 예측을 바탕으로, 제어 목표를 달성하기 위해 제어 입력을 조정하는 고급 제어 기법 중 하나, 이 예제에서는 차량이 지정된 path를 지나가며 빈 주차 공간을 탐색할때 사용한다.
Reinforcemet Learning : 에이전트는 상태(state)에서 행동(action)을 선택하고, 그 결과로 보상(reward)을 받아 다음 상태로 이동한다. 이 과정을 반복하면서 최적의 행동 전략(policy)을 학습하게 된다. 이 예제에서는 차량이 주차하는 방법을 학습할때 강화학습이 사용된다.
Actor-Critic Agent : 강화학습의 한 방법으로, 정책 기반 방법(Actor)과 가치 기반 방법(Critic)을 결합한 방식이다.
->Actor : 현재 상태에서 어떤 행동을 취해야 할지 결정하는 역할을 한다.. 즉, 정책(policy)을 업데이트하며 최적의 행동을 선택한다.
->Critic : Actor가 선택한 행동에 대해 얼마나 좋은지 평가해주는 역할을 한다. 즉, 가치 함수(value function)를 업데이트하며 Actor에게 피드백을 제공한다.
2.주차장 정보 설정 및 기본 탐색 경로 설정
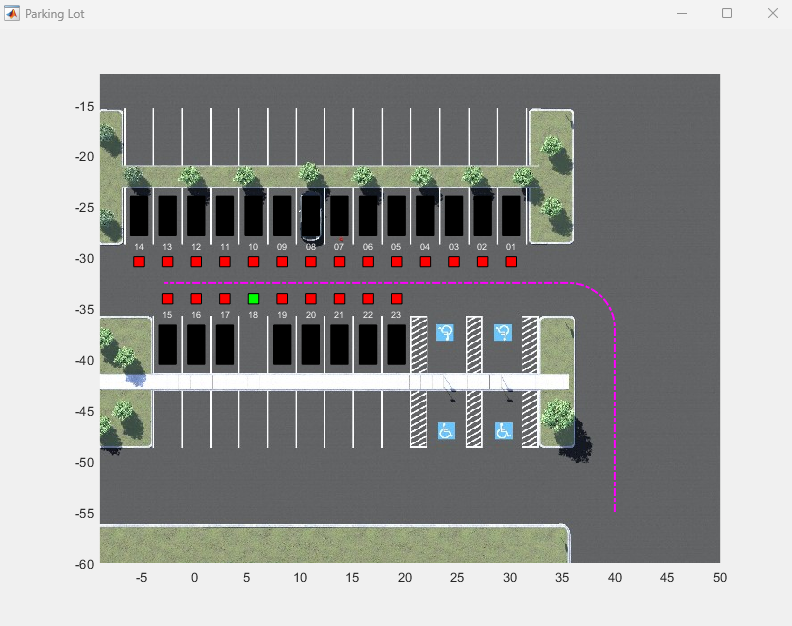
🟢주차장의 비어있는 주차자리를 설정하고, 자동차의 기본 경로(주차자리 탐색을 위해 돌아다니는 경로)및 초기상태, 목표상태를 설정해준다.
Ts = 0.1;
Tf = 50;
parkingLot = ParkingLotManager;
xRef = parkingLot.createReferenceTrajectory(Ts,Tf);
info = parkingLot.getInfo();
freeSpotIndex = 18;
mdl = "rlAutoParkingValet3D";
setupActorVehicles(mdl,freeSpotIndex);
visualizer = ParkingLotVisualizer(freeSpotIndex,Ts,Tf);
set(gcf,Visible="on");
egoInitialPose = [40 -55 pi/2];
vehiclePose = [10 -32.5 pi];
egoTargetPose = parkingLot.findGoalPose(vehiclePose,freeSpotIndex);3. 센서 관련 설정
🟢예제에서 자동차가 비어있는 주차자리를 찾는 과정은 Mode Selector를 통해 이루어진다.
Mode Selector는 두가지 모드를 가지고 있고, 특정 조건이 되었을때 모드가 바뀌게 된다.
Simulink 블록 다이어그램에서 Controller를 더블클릭해보면 MPC블록, RL블록을 볼 수있다.
- MPC control Mode : 2번에서 설정해준 기본 탐색 경로를 따라 자동차가 주행할때 사용하는 제어모드이다. MPC는 동적이고 복잡한 상황에서 유리한 제어기법이다. 이 예제에서는 MPC모드에서 자동차가 주행할때 Lidar를 사용하며, 빈 주차자리도 Lidar를 이용하여 searchDist 안에 탐지가 되면 아래의 강화학습모드(자율주차모드)로 바뀌게 된다.자세한건 관련 문서를 찾아보자
- Reinforcement Learning Mode(Auto Parking Valet Mode): 빈 주차자리를 발견하고, AutoParking을 수행하려할때 강화학습 모드가 쓰이게 된다. 이때 사전 학습된 자율주차 강화학습 모델을 이용하여 자율주차를 수행하게 된다. 강화학습또한 자세한 내용은 관련문서를 참조하자.

searchDist = 10;4. MPC controller 객체 생성
createMPCForParking3D;5. Reinforcement Learning contolloer 객체 생성 및 학습 파라미터 설정
🟢이 예제에서는 강화학습의 방법론중 Actor - Critic Agent 방식을 사용한다.
자동차가 parkingmode에 들어섰을때, 특정 좁은 구역(주차를 수행할 구역, 강화학습으로 주차방법을 학습해나갈 구역)을 설정하고, 그때 학습에 사용할 actor의 파라미터, critic network(actor의 행동에 따른 보상체계)의 파라미터를 설정하는 부분이다.
1️⃣Create Environment(강화학습에 사용할 자율주차 구역,허용오차,강화학습모델 경로 설정)
load("ObservationBus.mat","ObservationBus")
obsInfo = bus2RLSpec("ObservationBus");
obsNames = [obsInfo(1).Name, obsInfo(2).Name];
nAct = 1;
actInfo = rlNumericSpec([nAct 1],LowerLimit=-1,UpperLimit=1);
actNames = "actionInput";
agentBlock = mdl + "/Controller/RL Controller/RL Agent";
env = rlSimulinkEnv( ...
mdl, ...
agentBlock, ...
obsInfo, ...
actInfo, ...
UseFastRestart="off");
env.ResetFcn = @autoParkingValetResetFcn3D;2️⃣Create Agent
Actor 및 Critic 네트워크의 초기가중치를 동일하게 유지하도록 시드를 고정.
환경에서의 무작위 요소(액션 노이즈) 등도 동일하게 적용된다.
학습 과정이 동일한 방식으로 진행되도록 보장한다.
.....음... 정확히 이해는 못했다. 암튼 학습하는 루프마다 같은 초기 조건을 유지해서 오직 자율주차과정의 학습에만 집중하도록 하겠다는,,, 그런뜻이지 않을까?
rng(0)3️⃣Create Critics
Critic Network는 현재상태와 액션을 입력받아 가치를 예측한다.
현재의 Lidar데이터, pose데이터, 액션데이터를 기반으로 Q value(보상정도)를 결정하는 critic network를 만드는 과정이다.
% Lidar path
lidarPath = [
imageInputLayer( ...
obsInfo(2).Dimension, ...
Name="lidarData", ...
Normalization="none")
convolution2dLayer([5 5],8,Padding="same")
reluLayer
maxPooling2dLayer([3 3],Padding="same",Stride=[3 3])
convolution2dLayer([5 5],8,Padding="same")
reluLayer
maxPooling2dLayer([3 3],Padding="same",Stride=[3 3])
flattenLayer
tanhLayer
fullyConnectedLayer(512)
reluLayer
fullyConnectedLayer(256,Name="lidar_fc")];
% Pose path
posePath = [
featureInputLayer(obsInfo(1).Dimension(1),Name="poseInfo")
fullyConnectedLayer(64,Name="pose_fc")];
% Action path
actionInput = [
featureInputLayer(actInfo(1).Dimension(1),Name="actionInput")
fullyConnectedLayer(32,Name="action_fc")];
% Concatenated path
mainPath = [
concatenationLayer(1,3,Name="concat")
reluLayer
fullyConnectedLayer(256)
reluLayer
fullyConnectedLayer(128)
reluLayer
fullyConnectedLayer(1,Name="criticOutLyr")];
% Convert to layerGraph object and connect layers
criticNet = layerGraph(lidarPath);
criticNet = addLayers(criticNet,posePath);
criticNet = addLayers(criticNet,actionInput);
criticNet = addLayers(criticNet,mainPath);
criticNet = connectLayers(criticNet,"lidar_fc","concat/in1");
criticNet = connectLayers(criticNet,"pose_fc","concat/in2");
criticNet = connectLayers(criticNet,"action_fc","concat/in3");
criticdlnet = dlnetwork(criticNet);
summary(criticdlnet)
critic = rlQValueFunction(criticdlnet,obsInfo,actInfo,...
ObservationInputNames=obsNames, ActionInputNames=actNames);
4️⃣Create Actors(actor를 생성할때는 actor의 행동에 대한 파라미터도 같이 설정한다.)
행동을 취하는 actor를 생성한다.
Actor가 행동(Action) 선택:
현재 상태(State)를 보고 "어떤 행동을 할까?" 결정
예를 들어, 조향(steering)과 속도(throttle)를 결정
환경(Environment)에서 행동 실행 → 새로운 상태 & 보상 받음
자동차가 주차하려고 액션을 수행하면
새로운 라이다 데이터, 포즈 정보, 보상(주차 성공 여부) 등을 받음
Critic이 평가 (Q-value 계산)
Critic 네트워크가 "이 액션이 얼마나 좋은 액션이었는지" Q-value로 평가
만약 Critic이 "방금 한 행동이 별로 안 좋았어(Q-value 낮음)" 하면
Actor가 "다음엔 더 좋은 행동을 해야겠다"라고 학습
반복 (주차 성공할 때까지!)
Actor는 Critic의 평가를 보고 점점 더 똑똑한 주차 방법을 학습
% Lidar path
lidarPath = [
imageInputLayer( ...
obsInfo(2).Dimension, ...
Name="lidarData", ...
Normalization="none")
convolution2dLayer([5 5],8,Padding="same")
reluLayer
maxPooling2dLayer([3 3],Padding="same",Stride=[3 3])
convolution2dLayer([5 5],8,Padding="same")
reluLayer
maxPooling2dLayer([3 3],Padding="same",Stride=[3 3])
flattenLayer
tanhLayer
fullyConnectedLayer(512)
reluLayer
fullyConnectedLayer(256,Name="lidar_fc")];
% Pose path
posePath = [
featureInputLayer(obsInfo(1).Dimension(1),Name="poseInfo")
fullyConnectedLayer(64,Name="pose_fc")];
% Concatenated path
mainPath = [
concatenationLayer(1,2,Name="concat")
reluLayer
fullyConnectedLayer(256)
reluLayer
fullyConnectedLayer(128)
reluLayer
fullyConnectedLayer(actInfo(1).Dimension(1),Name="criticOutLyr")
tanhLayer];
% Convert to layerGraph object and connect layers
actorNet = layerGraph(lidarPath);
actorNet = addLayers(actorNet,posePath);
actorNet = addLayers(actorNet,mainPath);
actorNet = connectLayers(actorNet,"lidar_fc","concat/in1");
actorNet = connectLayers(actorNet,"pose_fc","concat/in2");
actordlnet = dlnetwork(actorNet);
summary(actordlnet)
actor = rlContinuousDeterministicActor(actordlnet,obsInfo,actInfo);
agentOpts = rlTD3AgentOptions(SampleTime=Ts, ...
DiscountFactor=0.99, ...
ExperienceBufferLength=1e6, ...
MiniBatchSize=256);
agentOpts.ExplorationModel.StandardDeviation = 0.1;
agentOpts.ExplorationModel.StandardDeviationDecayRate = 1e-4;
agentOpts.ExplorationModel.StandardDeviationMin = 0.01;
agentOpts.ActorOptimizerOptions.LearnRate = 1e-3;
agentOpts.ActorOptimizerOptions.GradientThreshold = 1;
agentOpts.ActorOptimizerOptions.L2RegularizationFactor = 1e-3;
agentOpts.CriticOptimizerOptions(1).LearnRate = 1e-3;
agentOpts.CriticOptimizerOptions(1).GradientThreshold = 1;
agent = rlTD3Agent(actor,critic,agentOpts);5️⃣Train Agent (모델 학습)
Agent = Actor + Critic + 학습알고리즘.
Agent는 Environment와 상호작용하며 목표를 학습하는 주체 (거의 그냥 Actor랑 비슷하다고 이해하면 된다. 시뮬레이션 환경의 자동차라고 생각을 하면 될듯.)
따라서 이 부분은 강화학습 모델을 학습시키는 부분이다.
내 컴퓨터에서 직접 학습을 시켜보고 싶으면 doTraining을 True로 해주면 된다.
내 로컬 컴퓨터의 환경을 불러와서 학습을 진행하는 함수인 setDeviceForAgent... 함수는 웹페이지 맨 아래에 코드가 위치해있다. 함수파일 만들어주면 된다.
False로 설정할경우, 기존에 다른사람이 학습해둔 모델을 불러오게된다.
trainOpts = rlTrainingOptions(...
MaxEpisodes=10000,...
MaxStepsPerEpisode=200,...
ScoreAveragingWindowLength=200,...
Plots="training-progress",...
StopTrainingCriteria="AverageReward",...
StopTrainingValue=116,...
UseParallel=false);
doTraining = false;
if doTraining
% Disable UE and point cloud visualization
setVisualizationOptions(UEViz="off",PCViz="off");
% If a GPU device is available, enable it for agent training
agent = setDeviceForAgentTraining(agent);
% Start training agent
trainingResult = train(agent,env,trainOpts);
else
load("ParkingValetAgentTrained.mat","agent");
end6. Simulate Parking Task
🟢자율주차를 테스트 해보자.(빈공간을 이 부분에서는 6으로 바꿔서 다른 환경에서도 잘 주차가 되는지 실험해보았다.)
SetVisualization 함수는 웹페이지 밑에 존재한다. 함수파일 만들어서 넣어주면된다.
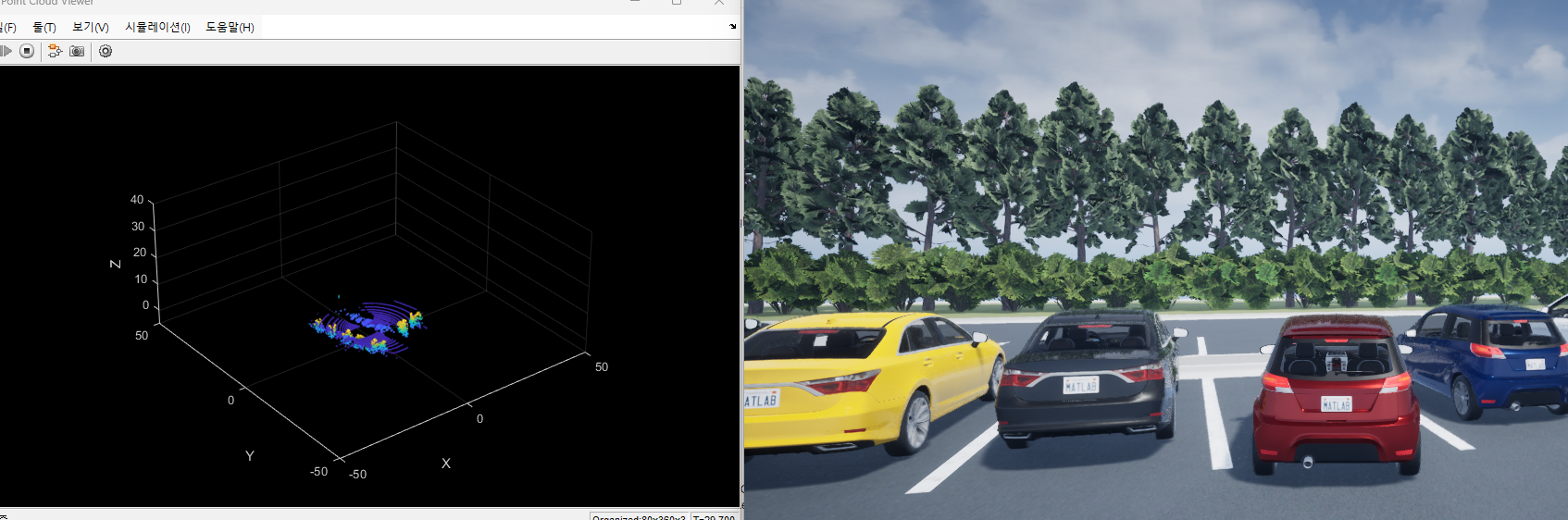
*기존에 설정했던 18번 자리를 빈자리로해서 자율주차 시뮬레이션
setVisualizationOptions(UEViz="on",PCViz="on");
sim(mdl);*6번을 빈자리로 해서 자율주차 시뮬레이션
freeSpotIndex = 6;
setupActorVehicles(mdl,freeSpotIndex);
sim(mdl);*차량의 이동을 그래프로 나타내줌
open_system(mdl + "/Vehicle Dynamics and Sensing/" + ...
"Ego Vehicle Model/Ego Vehicle Pose")💡마무리
자율주차같은 복잡한 환경 및 실시간으로 변화하는 환경에서는 강화학습이 유리함을 알게되었다.
강화학습은 실시간으로 주차상황을 평가하고 최적의 행동을 결정할 수 있다.
MPC는 자율주행에 직접적으로 활용된것이 아니라, 특정 목표나 Reference 경로가 있을때, 해당 경로로 이동하며 생기는 오차등을 보정해서 옳은 길로 가게하는 제어방식이다.
실제 연구실 자율주차 프젝에서도 유사한 방법을 적용하여, 시험 검증 할 수 있겠다.
