
머신러닝의 간단한 흐름과 대표적인 도구인 sklearn을 학습함.
머신러닝은 데이터가 가지는 특징(Feature)과 Target 사이의 패턴을 파악하는 일
1. 간단한 분류 프로젝트
문제1 데이터 불러오기(유방암 데이터)
from sklearn.datasets import load_breast_cancer
import pandas as pd
X, y = load_breast_cancer(return_X_y=True, as_frame=True)
dataset = pd.concat([X, y], axis=1)
dataset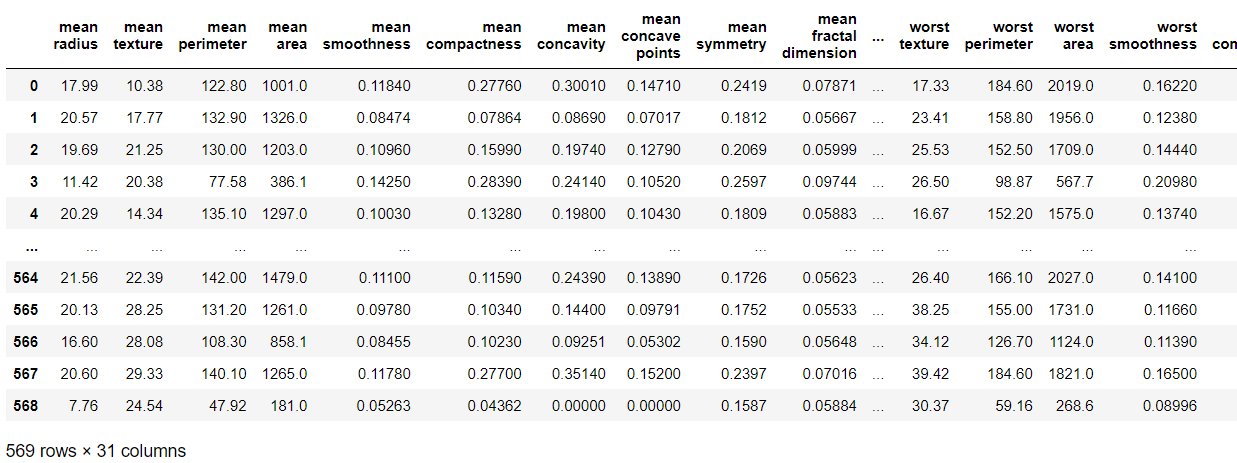
문제2 train_test_split(데이터 분리)
머신러닝을 위해서는 학습데이터, 검증데이터, 테스트데이터가 필요하다.
ex) 3~8월 모의고사 = 학습데이터, 9월모고 = 검증데이터, 수능 = 테스트데이터
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42) #test_size:테스트 데이터셋의 비율, random_state:데이터 분할시 셔플이 이루어지는데 이를 위한 시드값
print(f"Shape of X_train: {X_train.shape}") #train: 학습데이터, val: 검증데이터
print(f"Shape of y_train: {y_train.shape}")
print(f"Shape of X_val: {X_val.shape}")
print(f"Shape of y_val: {y_val.shape}")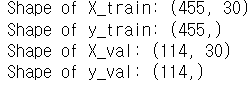
2. Preprocessing 전처리
문제1 null값 삭제
결측치를 다루는 방법 1. 삭제하기 2. 다른값으로 대체하기
실습코드는 삭제하기 방법을 사용함
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(100, 5), columns=["A","B","C","D","E"])
for _ in range(10):
row_idx = np.random.choice(df.index)
col_idx = np.random.choice(df.columns)
df.loc[row_idx, col_idx] = np.nan
print(f"🔎 # of NaN Values :\n {df.isnull().sum()}")
print(f"Shape of Data Frame : {df.shape}")
df= df.dropna(axis=0) #구현해야했던 코드, axis=0이면 결측값이 있던 행이 제거되고, axis=1이면 결측값이 있던 열이 제거된다
print(f"🚀 결측치 처리 후 :\n {df.isnull().sum()}")
print(f"Shape of Data Frame : {df.shape}")
문제2 Scaling 하기
모델의 안정적 학습을 위해서는 데이터의 단위를 통일시켜주는 것이 좋음
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
scaler = StandardScaler() #평균0, 분산 1로 조정
scaled_X_train = scaler.fit_transform(X_train) #학습데이터에는 fit_transform 사용
scaled_X_val = scaler.transform(X_val) #검증데이터에는 transform 사용,fit_transform을 test data에도 적용하게 된다면 test data로부터 새로운 mean값과 variance값을 얻게 되는 것이므로 사용 x
scaled_X_train_check = scaled_X_train.reshape(30, -1)
print(f"Scaling전 데이터의 최대, 최소, 평균, std: {X_train['mean texture'].max(), X_train['mean texture'].min(), X_train['mean texture'].mean(), X_train['mean texture'].std()}")
print(f"Scaling후 데이터의 최대, 최소, 평균, std: {scaled_X_train_check[0].max(), scaled_X_train_check[0].min(), scaled_X_train_check[0].mean(), scaled_X_train_check[0].std()}")
문제3 학습시키기
Tree모델 중에서 가장 기본인 DecisionTree와 Random Foreset를 사용해서 성능 비교
- DecisionTree 모델
from sklearn.tree import DecisionTreeClassifier
#모델학습
classifier = DecisionTreeClassifier(random_state=42)
classifier.fit(scaled_X_train, y_train)
print("🤖Training is Done!")
문제4 예측하기
3에서 학습시킨 모델로 scaled_X_val 예측하기, 모델의 정확도(Accuracy) 계산
from sklearn.metrics import accuracy_score
predictions = classifier.predict(scaled_X_val) #scaled_X_val 예측하기
accuracy = accuracy_score(y_val, predictions) #정확도 계산
print(f"Model Accuracy: {accuracy}")답을 모르겠어서 답지를 참고하였다. x,y,train,val이 자꾸 헷갈린다.
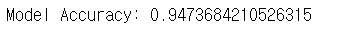
이해하는데 참고한 사이트
문제5 다른 모델도 써보기
랜덤포레스트로 학습과 예측, 정확도 계산까지의 코드를 완성해주세요!
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(random_state=42)
rf_clf.fit(scaled_X_train, y_train) #여기부터는 DecisionTree와 동일
rf_prediction = rf_clf.predict(scaled_X_val)
rf_acc = accuracy_score(y_val, rf_prediction)
print(f"Random Forest Model Accuracy: {rf_acc}")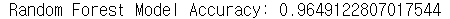
머신러닝 모델들의 학습시키고 테스트하는 양식이 비슷해서 어렵진 않았지만, train data랑 test(val) data 구분이 아직 잘 안 된다 ㅠㅠ 힝구리퐁퐁

도여줄게 완전히 도라진 나