
머신러닝은 크게 지도학습(데이터와 정답을 비교해나가며 학습)과 비지도학습(정답없이 데이터만으로 판단)으로 나눌 수 있다. 이번주차는 지도학습의 큰 방향이라고 할 수 있는 분류와 회귀에 대해 알아보고, 이들의 차이, 그리고 어떻게 만들어낼 수 있는 지 알아본다.
1-1 종류 파악 (회귀와 분류의 차이점)
지도학습이란?
독립변수와 종속변수가 존재, 과거에 만든 데이터를 통해 배움
-
회귀(regression)
예측하고 싶은 종속변수가 숫자(양적 데이터)일 때 ex)온도에 따른 음료 판매량, 공부시간에 따른 시험점수, 나이에 따른 키... -
분류(classification)
종속변수가 '이름'(범주형 데이터)일 때 ex)공부시간에 따른 합격여부, 와인의 등급, 악성종양여부...
1-2 분류 실습
간단하게 복습도 해볼겸, 지난시간 해봤던 유방암 분류를 한번 다시 따라가봅시다.
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
cancer_X, cancer_y = load_breast_cancer(return_X_y=True, as_frame=True)
dataset = pd.concat([cancer_X, cancer_y], axis=1)
target1 = dataset[dataset['target'] == 1]
resampled = dataset[dataset['target'] == 0].sample(20)
imbalanced_dataset = pd.concat([target1, resampled], axis=0)
print(f"불균형 이전 target 분포 :\n {dataset['target'].value_counts()}")
print(f"불균형 이후 target 분포 :\n {imbalanced_dataset['target'].value_counts()}")
#데이터 분리
X_train, X_val, y_train, y_val = train_test_split(imbalanced_dataset.drop(['target'], axis=1), imbalanced_dataset['target'], test_size=0.2, random_state=42)
#데이터 단위 통일 (Scaling)
scaler = StandardScaler()
scaled_X_train = scaler.fit_transform(X_train) #학습데이터는 fit_transform
scaled_X_val = scaler.transform(X_val) #검증데이터는 transform
#데이터 학습&예측
classifier = RandomForestClassifier()
classifier.fit(X_train, y_train)
preds = classifier.predict(X_val)
print("👀 Breast Cancer 분류 결과...")
print(classification_report(y_val, preds))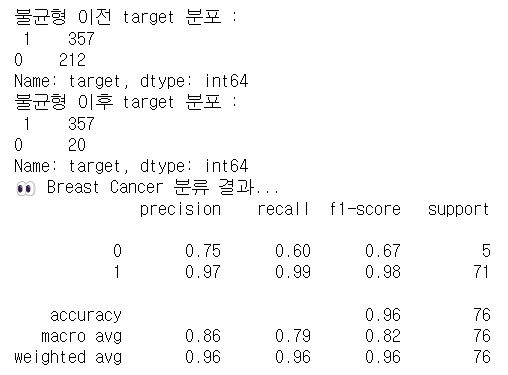
1-3 Classification Metrics
정확도를 의미하는 accuracy만으로는 모델의 성능을 충분히 판단할 수 없다. 데이터가 불균형한 경우, 대충 많은 target으로 찍으면 정확도는 높게 나올 수 있기 때문이다. 따라서 accuracy외에 precision, recall, f1-score와 같은 더 세밀한 지표가 필요하다.
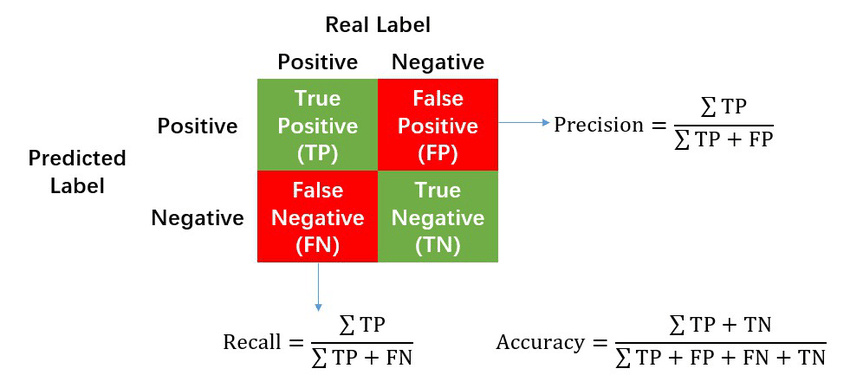
accuracy(정확도): 정확하게 분류 된 data의 개수(TP+TN)를 총 data의 개수(TP+FN+FP+TN)로 나눈 것
precision(정밀도): Positive class로 예측한 샘플(TP+FP) 중 실제 positive class인 샘플(TP)의 비율을 보여주는 평가지표이다.
recall(재현율): 실제로 positive class를 가진 샘플(TP+FN) 중 positive로 예측된 샘플(TP)의 비율
f1-score : precision과 recall의 조화평균(class분포가 분균일할 때 사용)

AOC-AUC : y축을 TPR = Recall(Sensitivity) x축을 FPR(1 - Specificity)로 하는 그래프
1-4 불균형이 적은 경우
1-2처럼 불균형을 강제로 준 데이터가 아닌, 본래의 데이터로 학습을 시켰을 때 차이를 확인해보면 다음과 같습니다.
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
cancer_X, cancer_y = load_breast_cancer(return_X_y=True, as_frame=True)
dataset = pd.concat([cancer_X, cancer_y], axis=1)
X_train, X_val, y_train, y_val = train_test_split(dataset.drop(['target'], axis=1), dataset['target'], test_size=0.2, random_state=42)
scaler = StandardScaler()
scaled_X_train = scaler.fit_transform(X_train)
scaled_X_val = scaler.transform(X_val)
classifier = RandomForestClassifier()
classifier.fit(X_train, y_train)
preds = classifier.predict(X_val)
print("👀 Breast Cancer 분류 결과...")
print(classification_report(y_val, preds))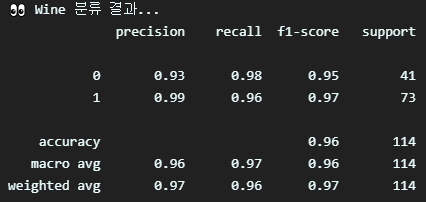
1-2와는 다르게 accuracy 외의 다른 지표도 높은 수준으로 나왔다.
그렇다면 실전에서 불균형을 해소시키는 방법은? 2가지가 있다.
- Over Sampling
: 부족한 데이터를 늘려 균형을 맞추는 것 - Under Sampling
: 충분한 데이터를 줄여 균형을 맞추는 것
<간단한 실습 코드>
!pip install imbalanced-learn #해당 라이브러리 설치import pandas as pd
from sklearn.datasets import load_breast_cancer
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
cancer_X, cancer_y = load_breast_cancer(return_X_y=True, as_frame=True)
original_dataset = pd.concat([cancer_X, cancer_y], axis=1)
print("✅ Class Distribusion before Sampling")
print(dataset['target'].value_counts())
#오버샘플링
print()
print("👀 Over Sampling")
X_over, y_over = RandomOverSampler(random_state=42).fit_resample(cancer_X, cancer_y) #fit_resample
over_dataset = pd.concat([X_over, y_over], axis=1)
print(over_dataset['target'].value_counts())
#언더샘플링
print()
print("👀 Under Sampling")
X_under, y_under = RandomUnderSampler(random_state=42).fit_resample(cancer_X, cancer_y) #fit_resample
under_dataset = pd.concat([X_under, y_under], axis=1)
print(under_dataset['target'].value_counts())
2-1 회귀?
데이터들을 표현할 수 있는 선을 잘 그려내는 것
2-2 회귀의 Metrics 알아보기
회귀 모델의 성능 평가 => 결국 예측값과 실제값의 차이를 기준으로 평가
예측값과 정답값의 차이를 Loss라고 하는데 Loss가 가장 적은 모델을 만드는 것이 목표
<회귀 모델의 성능 평가 지표>
MAE(Mean Absolute Error) : 모델의 예측값과 실제값의 차이의 절대값의 평균
MSE(Mean Squared Error) : 모델의 예측값과 실제값 차이의 면적(제곱)의 합
RMSE(Root Mean Squared Error) : MSE에 루트를 씌워 사용
R^2(R-squared, 결정계수) : 현재 사용하고 있는 x변수가 y변수의 분산을 얼마나 줄였는가 이다. 즉 값이 1에 가까우면 데이터를 잘 설명하는 모델이다.
참고
2-3 회귀 수행해보기
가장 간단한 모델인 Linear Regression으로 회귀를 시켜보고, 모델의 결과를 확인해본다.
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression #LinearRegression모델 사용
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
import numpy as np
import pandas as pd
from tabulate import tabulate
import matplotlib.pyplot as plt
def regression_report(preds, true):
r2 = r2_score(true, preds)
mae = mean_absolute_error(true, preds)
mse = mean_squared_error(true, preds)
rmse = np.sqrt(mse)
tmp_df = pd.DataFrame({
'R-squared': [r2],
'MAE': [mae],
'MSE': [mse],
'RMSE': [rmse]
})
print('\033[92m' + '\033[1m' + '📃Regression Report📃' + '\033[0m')
print(tabulate(tmp_df, headers='keys', tablefmt='psql'))
X, y = load_diabetes(return_X_y=True, as_frame=True)
dataset = pd.concat([X, y], axis=1)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
reg = LinearRegression() #LinearRegression모델 사용
reg.fit(X_train, y_train)
preds = reg.predict(X_val)
plt.plot(range(len(y_val)), preds, label="preds")
plt.plot(range(len(y_val)), y_val, label="True")
plt.legend()
plt.show()
regression_report(preds, y_val)