seq2seq(Sequence to Sequence)모델은 시퀀스를 입력받아 다른 시퀀스로 출력하는 모델이다. 주로 NLP의 번역에서 사용된다.

Seq2Seq모델은 Encoder, Decoder로 구성된다.
seq2seq 사용시

Encoder
인코더는 입력받은 시퀀스들에 대한 정보(hidden state)가 압축된 하나의 벡터를 만든다(context vector를 만듬)
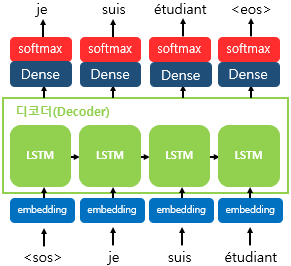
Decoder
-
디코더는 인코더로부터 받은 context vector로 초기의 hidden state를 설정한다. 첫번째 RNN(LSTM)셀은 이 context vector와 sos토큰을 통해 다음 단어 예측을 시작한다. (je)
-
hidden state들은 decoder의 출력 계층으로가 softmax함수를 사용하여 확률 분포를 계산하여 다음 단어를 예측한다.
-
각 time-step에서 현재의 hidden state(이전 시간 단계에서의 hidden state가 업데이트된 상태)와 이전의 단어를 통해 다음의 hidden state를 계산한다.
-
이는 eos토큰이 생성되기 전까지 반복된다.
seq2seq 훈련시
훈련과정에서는 디코더에게 인코더에서 나온 context vector와 실제 정답인 sos je suis étudiant를 알려주면 je suis étudiant eos가 출력되어야 한다고 정답을 알려주며 훈련시킨다.
