NLP 스터디
1.NLP / Cleaning, Normalization, Stemming, Lemmatization

corpus에서 토큰화를 진행하기 전 후에 cleaning과 normalization을 해야한다. cleaning의 경우 대부분 토큰화 전에 우선 진행한다. 토큰화를 한 후에도 용도에 맞게 토큰화가 제대로 진행되지 않았다면 cleaning을 한번 더 진행하여 용도에 맞
2.워드 카운트/ 패딩
본 글은 위키독스 딥러닝을 이용한 자연어처리 입문을 참고했다.말 그대로 해당 단어가 몇개인지 세는 작업이다. 이는 추후에 응용이 좋으므로 필수적이다. 직접 코드를 짜서 할 수도 있고 Counter,NLTK의 FreqDist, keras 등으로 시도할 수 있다. 코드를
3.언어 모델(Language Model)
이 글은 위키독스 딥러닝을 이용한 자연어 처리 입문 를 보고 스스로 공부하는 차원에서 적는 글입니다. 최대한 내 말로 적으려고 노력하고 있습니다. 언어 모델(Language Model)이란? 언어 모델은 단어(문장) 시퀀스에 확률을 할당(assign)하는 모델이다.
4.카운트 기반 단어 표현(BoW,DTM,TF-IDF)
단어의 표현방법 분류 단어의 표현방법은 크게 국소 표현(Local Representation)과 분산 표현(Distributed Representation)으로 나뉜다. 국소표현은 해당 단어만 보고 매핑하는 것이고 분산표현은 그 주위단어들도 보는 것이다. 예를들어
5.벡터 유사도(Vector Similarity)
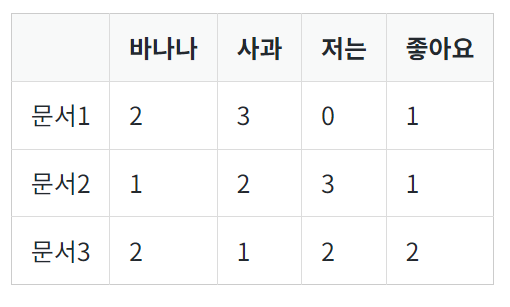
벡터 유사도는 문장이나 문서의 유사도를 구하는데 주로 사용된다. 문장이나 문서는 기계가 인식할 수 있게 벡터화 되는데 코사인 유사도, 유클리드 거리, 자카드 유사도 등을 사용해서 유사도를 구한다. 코사인 유사도 코사인 유사도는 두 벡터간의 코사인 각도를 이용하여 구할
6.머신러닝(Machine Learning) 기초
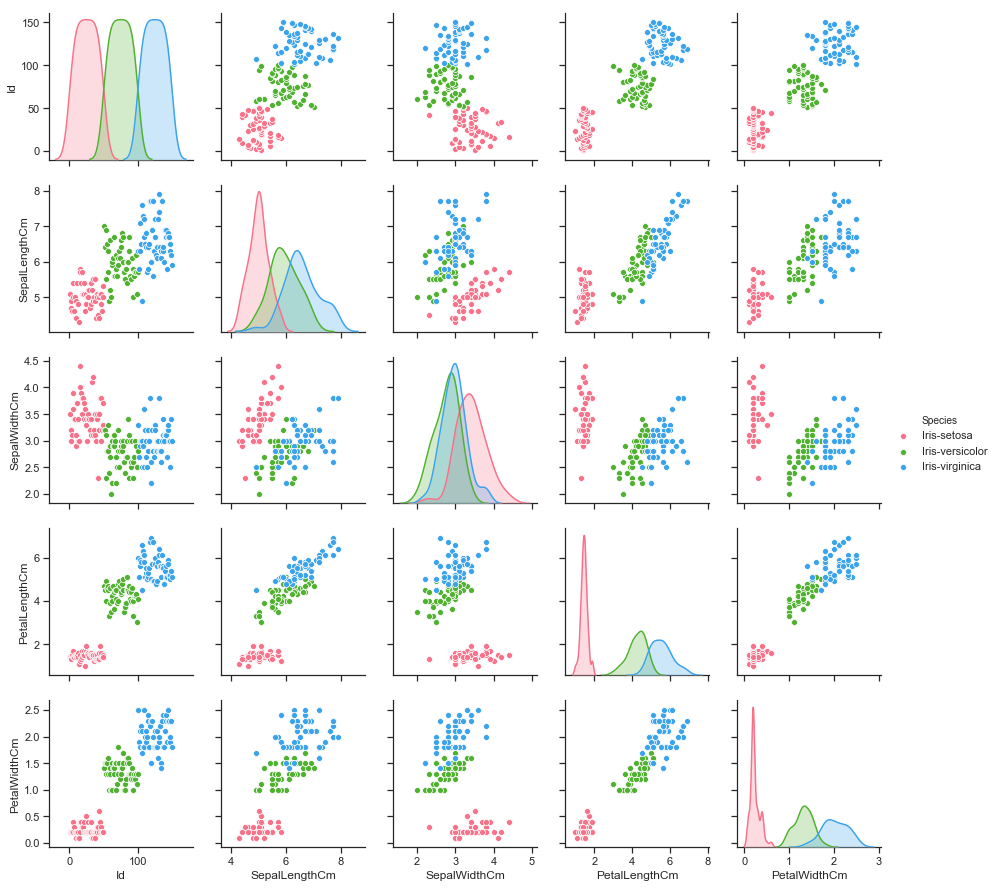
머신러닝이란? 머신 러닝은 데이터가 주어지면, 기계가 스스로 데이터로부터 규칙성을 찾게 하는 방식이다. 데이터 셋을 이런식으로 구성을 한다. 이때 validation 데이터셋은 모델의 성능을 평가하기 위한 것이 아니라 모델 성능을 조정하고 과적합을 발견하기 위한 데
7.딥러닝 기초
본글은 위키독스 딥러닝을 이용한 자연어처리 입문을 참고하여 복습목적으로 작성함 딥러닝(Deep Learning) 딥 러닝(Deep Learning)은 머신 러닝(Machine Learning)의 특정한 한 분야로서 인공 신경망(Artificial Neural Netw
8.딥러닝 기초 with Keras
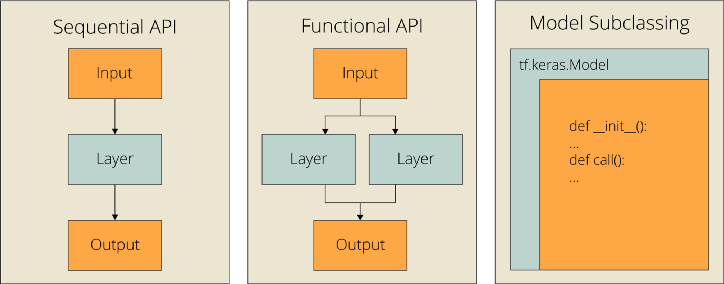
본글은 위키독스 딥러닝을 이용한 자연어 처리를 보고 복습용을 작성한 글이다.Sequential()은 keras에서 모델을 구축하는 가장 기본적인 방법이다. 여기에 층을 쌓아서 모델을 구축할 수 있다. 층은 .add()로 쌓을 수 있다. output은 (number of
9.FFNN(Feed Forward Neural Network)
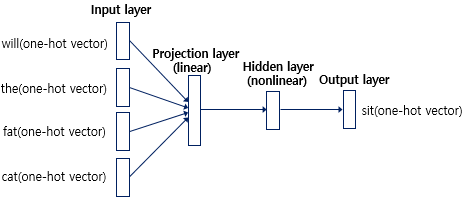
이글은 위키독스 딥러닝을 이용한 자연어 처리입문을 참고하여 복습용으로 작성하였음MLP(다층 퍼셉트론)은 단층 퍼셉트론 형태에서 은닉층이 1개 이상 추가된 신경망이다.MLP는 피드 포워드 신경망(Feed Forward Neural Network, FFNN)의 기본적인 형
10.Seq2Seq
seq2seq(Sequence to Sequence)모델은 시퀀스를 입력받아 다른 시퀀스로 출력하는 모델이다. 주로 NLP의 번역에서 사용된다. Seq2Seq모델은 Encoder, Decoder로 구성된다. seq2seq 사용시 Encoder 인코더는 입력받은