본글은 위키독스 딥러닝을 이용한 자연어처리 입문을 참고하여 복습목적으로 작성함
딥러닝(Deep Learning)
딥 러닝(Deep Learning)은 머신 러닝(Machine Learning)의 특정한 한 분야로서 인공 신경망(Artificial Neural Network)의 층을 연속적으로 깊게 쌓아올려 데이터를 학습하는 방식
기본용어
1.FFNN(Feed-Foward-Neural Network)
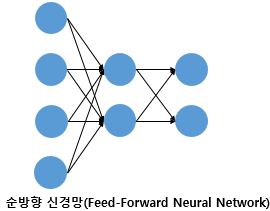
MLP(Multi Layer Perceptron)과 같이 입력에서 출력층 방향으로 연산이 전개되는 신경망
2. 전결합층(Fully-connected layer,FC, Dense layer)
어떤 층의 모든 뉴런이 이전층의 모든 뉴런과 연결되어 있는 층을 전결합층(Fully-connected layer)라고한다. 동일한 의미로 Dense층이라고도 한다.
3.활성화 함수(Activation Function)
퍼셉트론에서 계단함수로 출력 값이 0이될지 1이될지를 결정했다. 이처럼 은닉층과 출력층의 뉴런에서 출력값을 결정하는 함수를 활성화 함수라고 한다.
다양한 활성화 함수들
3-1) Sigmoid Function
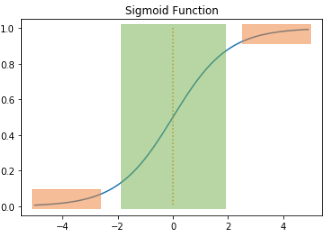
[vanishing gradient문제]
sigmoid를 역전파할때 vanishing gradient 문제가 생긴다. 초록색 부분의 미분값은 최대 0.25이고 주황색의 미분값은 0과 매우가깝다. 시그모이드함수를 사용하는 은닉층 수가 많으면 앞단에 기울기가 잘 전해지지 않는다. 따라서 매개변수 가 업데이트 되지 않아 학습이 되지 않는다.
3-2) Hyperbolic tangent function
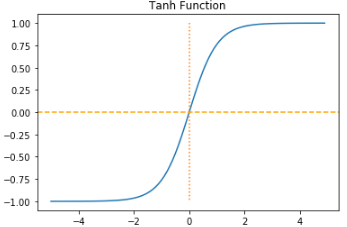
하이퍼볼릭 탄젠트 함수를 미분했을 때 최댓값은 1이므로 sigmoid function보다 기울기 소실 문제가 덜하다. 따라서 은닉층에서 시그모이드함수보다 자주 쓰인다.
3-3) Relu 함수
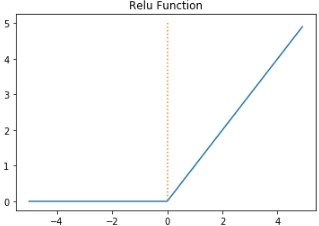
Relu는 은닉층에서 가장 인기있는 함수이다. Relu는 음수를 입력받으면 0을 출력하고 양수를 입력받으면 그 값을 그대로 출력한다. 깊은 신경망에서는 sigmoid보다 훨씬 좋다. 다만 0이된 뉴런을 다시 회생시키기 어렵다는 문제가 있다. 이 문제를 dying relu라고 한다.
3-4) Leaky Relu
Leaky Relu는 dying relu문제를 해결하기 위해 만들어졌다. 입력값이 음수인 경우 0이 아니라 0.001같은 매우 작은 수를 반환한다. 아래 사진을 보면 Relu가 죽지 않는것을 볼 수 있다.
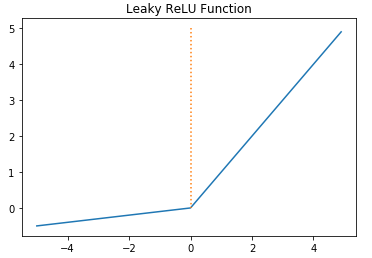
3-5) Softmax Function
은닉층에서는 주로 Relu를 사용한다. 소프트맥스함수와 시그모이드함수는 주로 출력층에 사용된다. 시그모이드함수는 이진분류에 사용되고 소프트맥스함수는 다중 클래스 분류 문제에 사용된다.
순전파(Foward Porpagtion)
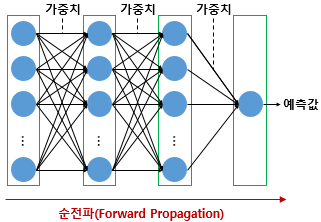
주어진 입력이 가중치와 함께 연산되며 은닉층을 지나 출력층에서 예측값을 얻는 과정
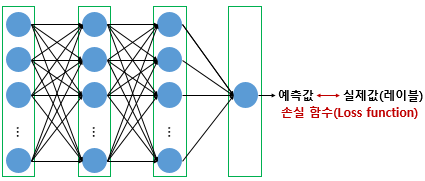
이때 구해진 예측값은 손실함수를 통해 실제값과 예측값의 차이를 구할 때 쓰인다. 손실함수는 이 차이를 수치화 해준다. MSE, Binary Cross entropy, categorical cross entropy 등등 다양한 손실함수가 존재한다.
배치 크기에 따른 경사하강법 (경사하강법 종류들)
배치는 가중치 등의 매개변수를 조정하기 위해 사용하는 데이터량을 말한다. 배치사이즈를 조정해서 전체데이터를 가지고 매개변수값을 조정할 수 있고 일부 데이터만 사용해서 매개변수 값을 조정할 수 있다.
Batch Gradient Descent(배치 경사하강법)
배치 경사하강법은 한번의 epoch에 모든 매개변수를 업데이트한다. 따라서 한번할 때 드는 리소스가 많다.
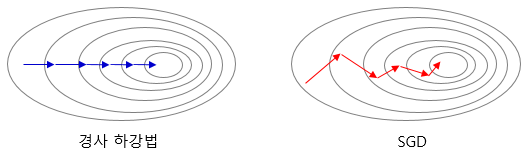
Stochastic Gradient Descent(SGD)
기존 방식은 리소스가 너무 많이 들기 때문에 랜덤으로 선택한 한개의 데이터로 GD를 계산하는 것이다. 매개변수 변경이 불안정하고 정확도가 낮을 수 있지만 메모리사용이 적다.
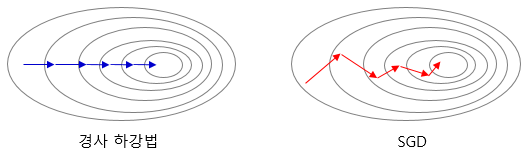
Mini-Batched Gradient Descent(미니배치 경사하강법)
이는 배치경사하강법과 SGD를 섞어서 적당한 배치사이즈를 택하는 방식이다. 아래코드와 같이 직접 지정하면 된다.
이해를 위한글: 미니 배치라는 말이 아래 배치관련 용어설명에 나오는것과 헷갈렸는데 미니배치로 경사하강법 하기로 이해하면 좋은것 같다.
model.fit(X_train,y_train,batch_size=128)배치관련 용어 설명
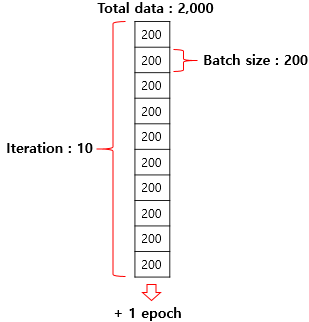
epoch: epoch은 학습과 훈련이 모두 다 진행되었을 때의 횟수를 얘기한다. 즉 예시에서 2000개의 데이터에 처음부터 끝까지 한번 학습을 진행하면 1epoch 학습했다고 한다.
Batch size: 배치사이즈는 몇개 단위의 데이터로 모델을 학습시킬건지를 말한다. 위의 예시처럼 배치사이즈가 200이면 200개의 샘플 단위로 가중치를 업데이트한다.
Iteration , Step: 두 단어는 같은 의미로 쓰인다. 이터레이션은 한번의 에폭을 끝내기 위해 필요한 배치 수 이다. Total data/Batch size로 구할 수 있고 위에 예시처럼 iteration이 10인 경우 미니배치가 10개 있다고 표현하기도 한다. 또 iteration 수 만큼 매개변수 갱신이 일어난다.
total data: 1000
minibatch=Iteration=Step:10
인경우 batch_size=100 이고 SGD를 10번 진행하고 이에따른 매개변수 갱신이 10번 되는 것이다.
이때 epoch이 20이면 총 20*10 = 200번 매개변수 갱신이 일어난다.
과적합을 막는 법들
모델이 과적합되면 훈련데이터에 한해서는 잘 작동할 수 있어도 검증데이터나 테스트 데이터에는 잘 작동하지 않는다. 과적합이 일어난 상태는 모델이 데이터의 노이즈까지 암기한 상태라고 이해하면 좋다. 따라서 과적합을 막을 방법들이 필요하다.
1. 데이터의 양을 늘리기
데이터 양이 적을 때 데이터의 양을 늘리면 과적합 방지에 좋다. 이를 데이터 증강(Data Augmentation)이라고 한다. 텍스트 데이터는 데이터 증강 방법으로 번역 후 재번역을 하여 새로운 데이터를 만들어내는 역번역(Back Translation)이 있다.
2. 모델의 복잡도 줄이기
인공신경망의 복잡도는 hidden layer 수나 매개변수 수에 의해 결정된다. hidden layer 수나 매개변수 수를 줄여서 복잡도를 줄이면 과적합을 줄일 수 있다.
3. 가중치 규제(Regulation) 적용하기
복잡한 모델을 간단하게 만드는 과정으로 가중치규제가 있다.
L1 규제 : 가중치 w들의 절대값 합계를 비용 함수에 추가합니다. L1 노름이라고도 합니다.
기존 비용함수에 모든 가중치에 대해서 를 더한 값을 비용함수로 한다.
L2 규제 : 모든 가중치 w들의 제곱합을 비용 함수에 추가합니다. L2 노름이라고도 합니다. 기존 비용함수에
모든 가중치에 대해서 를 더한 값을 비용함수로 한다.
가 크다면 모델이 훈련데이터에 대해서 적합한 매개 변수를 찾는 것보다 규제를 위해 추가된 항들을 작게 유지하는 것을 우선한다
규제의 성능적 차이점
L1은 가중치 W의 값이 0에 가까워져 어떤 특성들은 모델을 만들 때 아에 사용되지 않는다.
L2규제는 L1규제와 달리 W 값이 완전히 0이 되는것보다 0에 가까워지는 경향을 띈다.
L1규제는 어떤 특성이 모델에 영향을 주고 있는지 정확히 판단할 때 유용하다.
위의 케이스가 아니라면 경험적으로 L2규제가 더 효과적이다.
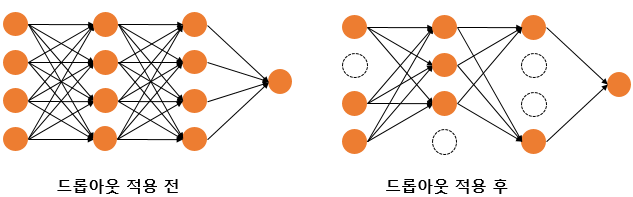
Dropout
dropout은 신경망의 일부를 사용하지 않는 것이다.
만약 dropout을 0.5로 설정하면 랜덤으로 전체 신경망의 뉴런 중 반만 사용하게 된다. 이렇게 되면 모델의 복잡도를 줄여서 과적합을 방지할 수 있다.
드롭아웃은 신경망 학습 시에만 사용하고, 예측 시에는 사용하지 않는 것이 일반적입니다
Gradient Vanishing & Exploding
deep nueral network를 사용할 때 기울기 소실과 폭주의 문제가 생길 수 있다.
가중치를 역전파 시킬 때 0에 가까운 기울기들이 계속 곱해진다. 따라서 입력층에서 가까운 층들의 가중치가 제대로 업데이트가 되지 않는다. 이런 상황을 Gradient Vanishing이라고 한다.
반대로 기울기가 점차 커져서 가중치가 발산하는 경우도 있다. 이를 Gradient Exploding이라고 한다.
이를 위해 아래와 같은 방법들이 제시되어 있다.
1.Relu와 Relu의 변형들
시그모이드함수를 사용하면 입력의 절대값이 클수록 출력값이 0또는 1에 수렴하면서 기울기가 0에 가까워진다. 이를 완화하는 방법은 활성화함수로 시그모이드나 하이퍼볼릭탄젠트 대신에 relu나 leaky relu등 relu의 변형을 사용하면된다. 즉 은닉층에서는 시그모이드 함수 사용을 자제하자.
2. Gradient Clipping
gradient clipping은 기울기 폭주를 막기 위해 임계값이 넘지 않도록 기울기 값을 자르는 것이다. 즉, 임계치만큼 크기를 감소시키는 것이다. 이는 RNN에 많이 사용된다.
from tensorflow.keras import optimizers
Adam = optimizers.Adam(lr=0.0001, clipnorm=1.)3. 가중치 초기화
가중치 초기화는 Xavier Initialization과 He Initialization으로 나뉜다.
Xavier Initialization는 시그모이드 함수나 하이퍼볼릭 탄젠트 함수와 같은 S자 형태인 활성화 함수와 함께 사용할 경우에는 좋은 성능을 보인다.
He Initialization은 Relu계열의 함수에 더 효과적이다.
주로 Relu + He 초기화 방법이 더 보편적이다.
4. 배치정규화(Batch Normalization)
사전개념:내부공변량 변화(Interneal Covariate Shift)
학습과정에서 층별로 입력데이터 분포가 달라지는 현상
배치정규화
배치 정규화(Batch Normalization)는 표현 그대로 한 번에 들어오는 배치 단위로 정규화하는 것을 말합니다. 배치 정규화는 각 층에서 활성화 함수를 통과하기 전에 수행된다. 이를 통해 다음 레이어에 일정한 범위의 값들만 전달한다. 하지만 이는 미니배치크기가 너무 작으면 동작하지 않고 RNN에 적용하기 어렵다는 특징이 있다. 따라서 Layer Normalization(층 정규화)를 사용한다.
층 정규화는 transformer에 매우 유용하게 사용된다.
알게된 점
-
딕셔너리로 dataframe만들기
pd.DataFrame({key:value, key:value})를 통해 딕셔너리 형식으로 데이터프레임을 만들 수 있다. -
배치사이즈,미니배치,에폭,이터레이션에 대한 개념
batch_size는 데이터를 어떤 사이즈로 나눌지를 결정하는 것이다.
mini_batch는 전체 데이터를 배치사이즈로 나눈 작은 배치를 말한다.
iteration(step)은 배치사이즈가 몇번 반복이 되어야 전체데이터가 되는지이다. 미니배치의 값과 같다.
epoch은 전체 데이터가 학습과 파라미터 조정이 다 이루어진 횟수를 의미한다.
ex) Total data =1000, batch_size=100 mini_batch= 10 , iteration= 10
이 전체과정을 3번 반복하면 epoch=3
-
활성화 함수는 하나의 직선으로 표현할 수 없는 비선형 함수로 이루어져있다. projection layer(linear layer)는 비선형 함수에 속한다. 따라서 이는 활성화 함수가 아니다. 대신에 이는 학습가능한 가중치가 새로생긴다는 점에서 하나의 layer로 사용하는 경우가 있다. - (embedding layer도 일종의 선형 층이다)
-
역전파과정
순전파를 통해 예측값과 실제값의 차이인 오차가 구해진다. 이 오차를 통해 출력층에서 입력층 방향으로 계산하며 가중치를 갱신한다
해당 식 처럼 갱신이 된다.
이를 통해 다시 순전파를 계산하면 오차가 줄어든다. -
Dropout 사용시 주의사항
학습시에만 dropout을 사용하고 예측에는 사용하지 않는다. 이는 훈련은 일반적 데이터 잘 적용할 수 있게 만드는 것이고 예측은 가장 정확한 예측을 하는 것이기 때문에 최대한 많은 뉴런을 활성화 시켜 모델의 성능을 최대로 발휘하는게 중요하기 때문이다. -
그래디언트 클리핑(Gradient Clipping)
Gradient Clipping은 gradient exploding 문제를 해결하기 위해 임계값이 넘지 않도록 기울기를 감소시키는 방법이다. -
Gradient Initialization
이는 기울기 소실을 해결하기 위해 사용한다. Xavier Initialization과 He Initailization이 있다. 이중 Xavier는 Softmax나 tanh에 효율이 좋고 He는 Relu와 효율이 좋다. 일반적으로 Relu+He를 많이 사용한다고 한다. -
배치정규화
배치정규화는 배치단위로 정규화하는 것이다. 이는 각층에서 활성화함수를 적용시키기 전에 사용되며 입력데이터의 분포가 달라지는 현상을 막기위해 사용한다. 이미지 데이터에서는 배치정규화의 효과가 좋지만 텍스트 데이터에서는 주로 Layer Normalization을 사용한다.
