머신러닝이란?
머신 러닝은 데이터가 주어지면, 기계가 스스로 데이터로부터 규칙성을 찾게 하는 방식이다.

데이터 셋을 이런식으로 구성을 한다. 이때 validation 데이터셋은 모델의 성능을 평가하기 위한 것이 아니라 모델 성능을 조정하고 과적합을 발견하기 위한 데이터셋이다. 이때 하이퍼파라미터 튜닝을 한다. 추가적으로 검증에 사용된 데이터셋은 테스트에 사용되지 않는다.
분류(Classification)와 회귀(Regression)
머신러닝의 대부분은 분류와 회귀로 나뉜다.
대표적인 분류는 로지스틱 회귀(Logistic Regression)가 있고 대표적인 회귀는 선형회귀(Linear Regression)가 있다.
분류는 이진분류(Binary Classfication), 다중 클래스 분류(Multi Class Classfication)으로 나뉜다. 이 때 회귀는 연속적인 값의 범위 내에서 예측값이 나오는 경우로 주로 시계열 데이터를 이용한다.
Confusion Matrix(혼동행렬)-분류의 평가지표
분류 문제는 주로 confusion matrix를 평가 지표로 사용한다.
| 예측 참 | 예측 거짓 | |
|---|---|---|
| 실제 참 | TP | FN |
| 실제 거짓 | FP | TN |
이때 Accuracy 말고 F1 score라는 값을 종종 사용한다.
그 이유는 스팸메일을 분류하는 경우에 200개 중에 스팸 메일이 5개라고 가정하자
이 때 모델이 200개가 모두 정상 메일이라고 해도 스팸 메일의 갯수가 5개 밖에 안되므로 정확도가 95%가 나온다. 이를 개선하기 위해 사용되는게 F1 score이다.
과적합
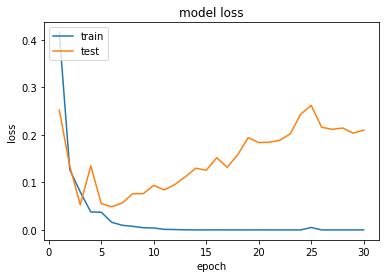
y축은 오차(loss), X축의 에포크(epoch)는 전체 훈련 데이터에 대한 훈련 횟수를 의미한다. epoch을 엄청 늘리면 train의 loss는 엄청 낮아지지만 test의 loss는 높아지는걸 확인할 수 있다. 이 상황이 과적합이 나는것이다.
해당 표를 확인하면 3에서 4를 지나갈때 test의 loss가 높아지는걸 확인할 수 있다. 이때부터 과적합이 발생하는 것이다. 이런 상황을 방지하기 위해서는 테스트 데이터의 오차가 증가하기 전이나, 정확도가 감소하기 전에 훈련을 멈추는 것이 바람직하다.
선형회귀(Linear Regression)
1) 단순 선형회귀분석(Simple Linear Regression Analysis)
종속변수 y에 영향을 주는 독립변수 x가 1개인 경우이다.
와 에 따라 생길 수 있는 직선은 무수히 많다.
2) 다중 선형 회귀 분석(Multiple Linear Regression Analysis)
종속변수 y에 영향을 주는 독립변수 x가 여러개인 경우이다.
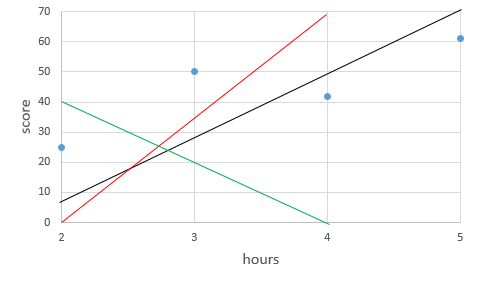
파란색 점이 데이터 포인터라고 해보자. 선형회귀는 결국 파란색 데이터 포인터를 가장 잘 나타내는 직선을 그리는 것이다.
Cost Function(비용함수)- MSE(Mean Squared Error)
회귀문제에는 손실함수로 주로 평균제곱 오차가 사용된다. 간단히 말하자면 포인터와 직선의 오차가 커지면 mse가 커지고 오차가 작아지면 mse값이 줄어드는 것이다.
옵티마이저(Optimizer) : 경사하강법(Gradient Descent)
머신러닝, 딥러닝에서 학습을 위해 손실함수를 최소로 만드는 매개변수 와 를 찾는다. 이때 사용되는 알고리즘이 옵티마이저(Optimizer) 또는 최적화 알고리즘이라고 불린다.
위의 그래프처럼 매개변수 를 기울기라 볼 수 있다.
편의를 위해 편향 가 없다고 가정하고 라고 해보자. 이를 통해 경사하강법을 한다.
비용함수의 값을 라고 할 때 우리는 와 의 관계를 아래와 같이 표현할 수 있다.
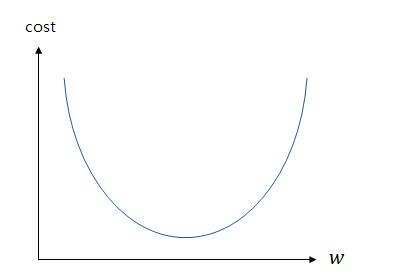
의 값이 무한대로 커지거나 의 값이 무한대로 작아지면 가 무한대로 커짐을 알 수 있다. 이를 최소로 만들기 위해서는 아래 그림처럼 기울기가 0이 되어야한다. 이 지점은 식을 미분함으로써 구할 수 있다.
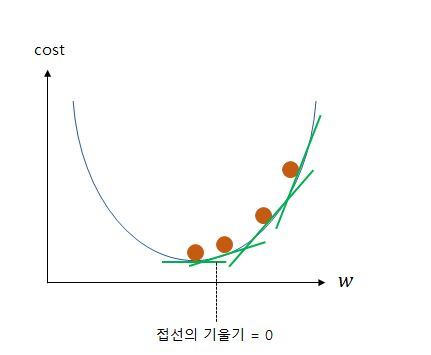
아래 식은 cost를 최소화하는 를 구하기 위해 를 업데이트 하는 식이다.
해당 식을 통해
이제 아래를 keras 코드를 통해 직접 구해보겠다.
keras 코드
keras로 모델 구현하는 법은 다음과 같다
1. 모델 선언
2. 층 추가(층이름, 입력 차원, 출력차원, 활성화함수)
3. 옵타마이저 선언
4.compile 함수로 손실함수, 옵티마이저, 평가지표 정함
modle=Sequential()
model.add(Dense(1,input_dim=1,activation='linear'))
sgd= optimizers.SGD(lr=0.01)
model.compile(optimizer=sgd,loss='mse',metrics=['mse'])
model.fit(x,y,epochs=100)
plt.plot(x, model.predict(x), 'b', x, y, 'k.')잘 된것을 확인할 수 있다.
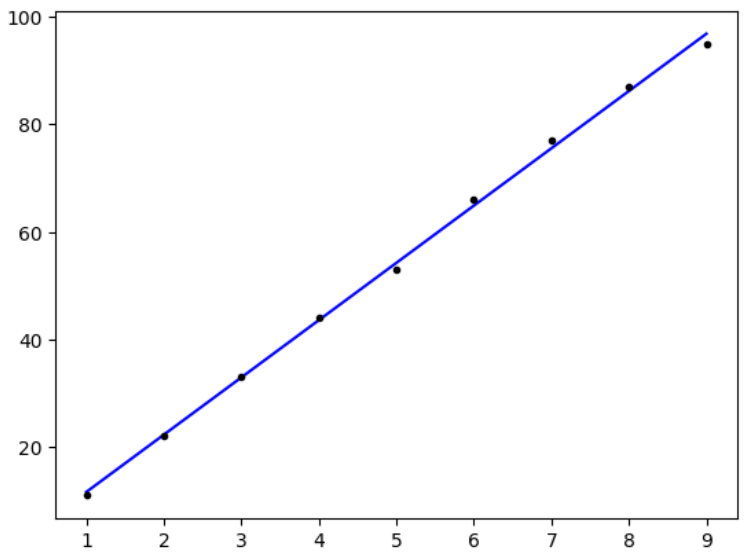
특정 값을 예측하고자 할때 model.predict를 통해 예측해볼 수 있다.
print(model.predict([8.5]))
#output
#[[91.53793]]로지스틱 회귀(Logistic Regression)
로지스틱회귀는 이진분류 문제를 해결하기 위해 사용하는 방법 중 하나이다.
로지스틱 회귀는 시그모이드 함수를 사용한다
이때도 마찬가지로 가중치인 ,를 변경하면서 최적의 값을 찾는다.
Cross entropy 함수
로지스틱 회귀에서는 cost function으로 cross entropy를 사용한다. 이는 소프트맥스의 cost function으로도 쓰인다.
로지스틱 회귀에서는 비용함수로 앞서말한 mse를 사용하지 않는다. mse를 비용함수로 사용하면 로컬 미니멈에 빠질 확률이 높기 때문이다.
로지스틱 회귀에서 가중치 를 최소로 만드는 새로운 cost function이 필요하다. 가중치를 최소화하는 아래의 어떤 함수를 목적 함수라고 한다.
시그모이드 함수는 0과 1의 사이 값을 갖는다. 실제 값이 0일 때 값이 1에 가까워질수록 오차가 커지고 실제 값이 1일때 값이 0에 가까워질수록 오차가 커진다. 이는 로그함수로 표현된다.
이를 그래프로 표현하면 아래와 같다
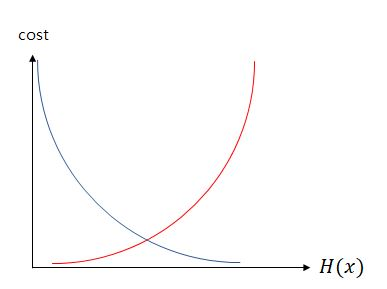
빨간색 그래프는 실제값이 0일 때 이고 파란색 그래프는 실제 값이 1일 때이다. 빨간 그래프를 살펴보면 h(x)가 커질수록 cost function이 증가하는 것을 확인할 수 있고 h(x)
이는 다음과 같이 표현된다.
코드구현
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
x = np.array([-50, -40, -30, -20, -10, -5, 0, 5, 10, 20, 30, 40, 50])
y = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]) # 숫자 10부터 1
model=Sequential()
model.add(Dense(1,input_dim=1,activation='sigmoid'))
sgd=optimizers.SGD(lr=0.01)
model.compile(optimizer=sgd, loss= 'binary_crossentropy',metrics=(['binary_accuracy']))
model.fit(x, y, epochs=200)
plt.plot(x,model.predict(x),'b', x,y,'k.')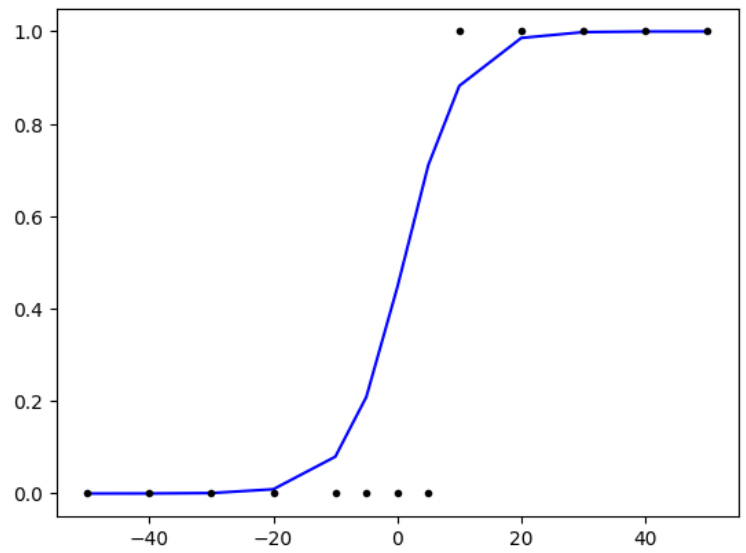
해당 plot을 보면 5~10 사이의 값에서 y값이 0.5가 넘는 것을 확인할 수 있다.
소프트맥스 회귀(Softmax Regression)
소프트맥스 회귀는 주로 다중 클래스 분류에 사용된다. 만약 이진 분류에 사용하는 시그모이드 함수를 다중 클래스 분류에 사용하는 예를 들면 setosa가 정답일 확률은 0.8, versicolor가 정답일 확률은 0.2, virginica가 정답일 확률은 0.4 처럼 합계가 1이 넘을 수 있다. 이를 전체 선택지에 걸친 확률로 바꿀 필요가 있다. 이 때 사용하는게 소프트맥스 함수이다.
수식이해
k차원의 벡터에서 i번째 원소를 , i번째 클래스가 정답일 확률을 로 나타낸다고 할 때 다음과 같이 정의한다.
만약 3차원 벡터 의 입력을 받으면 소프트맥스 함수는 아래와 같다.
이때 정답 label을 원핫 벡터로 인코딩한다. 그 이후 예측값과 실제값의 오차를 구해서 가중치와 편향을 업데이트한다.
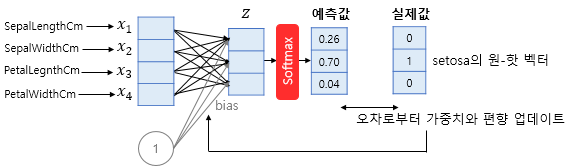
소프트맥스도 cost function으로 비용함수를 사용한다.
알게된 점
-
하이퍼파라미터는 모델 성능에 영향을 주는 사람이 직접 조정하는 변수 이고 파라미터는 가중치와 편향으로 모델이 작동하면서 계속 변하는 수이다.
-
Validation은 train 데이터셋을 나눈 것으로 학습한 모델이 과적합 여부와 하이퍼파라미터 튜닝을 위해 사용된다. Validation으로 최적의 파라미터를 찾은 후 이는 train과 합쳐져서 모델학습에 사용된다.
3.정답 갯수가 97개 오답 갯수가 3개 일때 전체가 정답이라고 예측을 해도 Accuracy는 97%가 나온다. 이같은 상황을 막기 위해 사용되는게 confusion matrix(혼동행렬)이고 거기서 파생된게 F1 score이다.
4.과적합 plot의 x축은 epoch, y축은 loss로 둔다. train loss와 test loss가 역전할 때 과적합이 일어난다고 볼 수 있다. -
옵티마이저는 loss를 최소로 만드는 매개변수 최적의 ,를 찾는 알고리즘이다.
6.pairplot은 각 변수간의 관계를 쌍으로 나타내는 그래프의 집합을 만든다. 데이터초기탐색에 유용하고 데이터 간의 관계, 패턴, 이상치 파악에 용이하다. 이때 hue='특징'을 설정하면 '특징'을 기준으로 색을 다르게 해서 '특징'별 분포 파악이 가능하다.
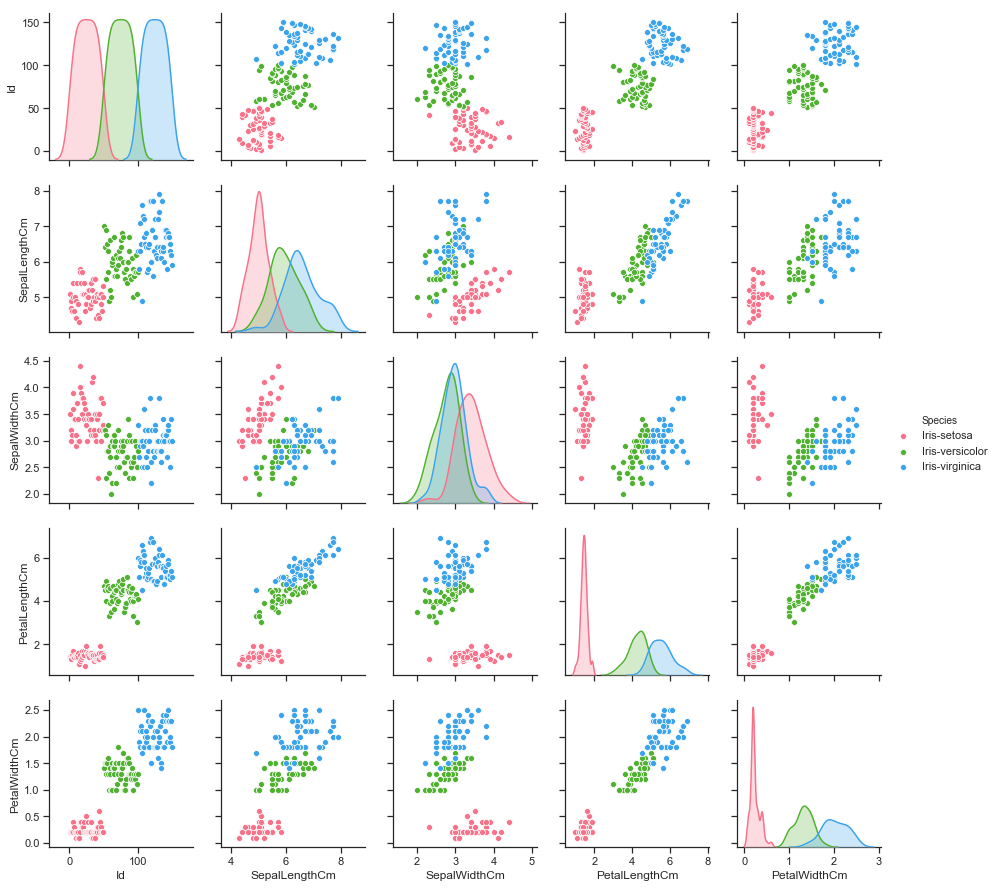
-
시그모이드함수는 이진분류 문제에 주로 사용된다. 시그모이드 함수는 0과 1 사이의 값을 갖는다. 중간의 겹치는 값을 기준으로 분류가 이루어진다.
-
softmax함수는 다중 클래스 분류에 사용된다. 만약 여러개의 class를 가진 경우 이를 시그모이드로 적용하면 전체의 합이 1이 나오지 않는다. softmax는 이런 상황에서 여러개의 class 중에 그 class가 나올 확률을 찾아준다. 이때 정답 class을 원핫인코딩 하고 비용함수로 cross-entropy함수를 사용한다.
-
다중 클래스 분류는 각 인스턴스가 정확히 하나의 클래스로 분류되는 것이다. 예를들어 과일 이미지를 바나나,사과, 오렌지 중 하나로 분류를 하는 것이다.
다중 레이블 분류는 각 인스턴스가 여러개의 레이블을 가질 수 있다. 예를들어 한 영화가 액션, 코미디, 로맨스의 장르를 가질 수 있는 경우이다.
즉 다중 클래스 분류는 하나만 옳다 이고 다중 레이블 분류는 여러 레이블이 동시에 옳을 수 있다이다. 전자의 활성화함수는 소프트맥스 함수가 사용되고 후자의 활성화 함수는 소프트맥스 함수가 사용된다.
시그모이드함수 왜쓰는지
10.history.history 객체는 keras를 사용할 때 loss와 metrics를 기록한 값을 딕셔너리로 저장한다.
- softmax를 사용하기 위해 원핫 인코딩을 할 때 to_categorical()을 사용하자
y_train = to_categorical(y_train)- Dense 층의 output은 y_train의 열의 shape과 같아야한다. 만약 바꿔주지 않으면 shape문제로 인한 error가 발생한다
print("y_train.shape",y_train.shape)
output
y_train.shape (120, 3)
model.add(Dense(3, input_dim = 4, activation = 'softmax'))