본 글은 딥러닝을 이용한 자연어 처리 입문를 참조하여 작성한 복습을 위한 글이다
벡터 유사도는 문장이나 문서의 유사도를 구하는데 주로 사용된다. 문장이나 문서는 기계가 인식할 수 있게 벡터화 되는데 코사인 유사도, 유클리드 거리, 자카드 유사도 등을 사용해서 유사도를 구한다.
코사인 유사도
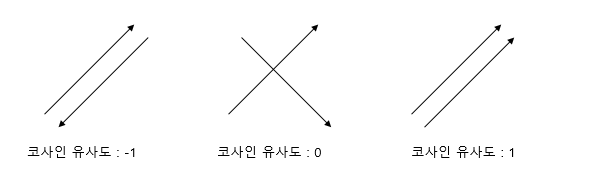
코사인 유사도는 두 벡터간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도이다. 두 벡터의 방향이 같으면 1, 90도의 각을 이루면 0, 180도(정반대)의 각을 이루면 -1이다. 즉, -1과 1 사이의 값을 가지며 1에 가까울 수록 유사한 것이다. 두 벡터가 얼마나 같은 방향을 가르키냐에 따른 값이다.
코사인유사도 식이다
유클리드 거리
유클리드 거리는 문서 간 유사도를 구할 때 주로 쓰이지는 않는다.
해당 공식은 피타고라스의 정리를 통해 두점 사이의 거리를 구하는 공식과 같다.
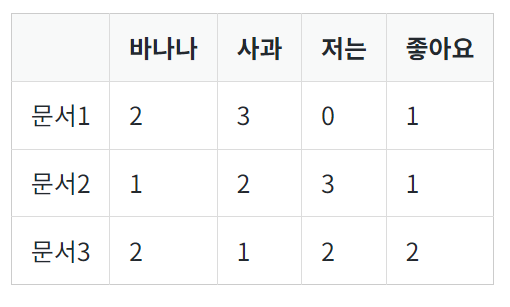
아래와 같은 DTM이 있다고 가정하자.
| 바나나 | 사과 | 저는 | 좋아요 | |
|---|---|---|---|---|
| 문서1 | 2 | 3 | 0 | 1 |
| 문서2 | 1 | 2 | 3 | 1 |
| 문서3 | 2 | 1 | 2 | 2 |
위의 DTM과 아래 문서 Q의 유사도를 구한다고 해보자
| 바나나 | 사과 | 저는 | 좋아요 | |
|---|---|---|---|---|
| 문서Q | 1 | 1 | 0 | 1 |
import numpy as np
def dist(x,y):
return np.sqrt(np.sum((x-y)**2))
doc1 = np.array((2,3,0,1))
doc2 = np.array((1,2,3,1))
doc3 = np.array((2,1,2,2))
docQ = np.array((1,1,0,1))
print('문서1과 문서Q의 거리 :',dist(doc1,docQ))
print('문서2과 문서Q의 거리 :',dist(doc2,docQ))
print('문서3과 문서Q의 거리 :',dist(doc3,docQ))output
문서1과 문서Q의 거리 : 2.23606797749979
문서2과 문서Q의 거리 : 3.1622776601683795
문서3과 문서Q의 거리 : 2.449489742783178자카드 유사도(Jaccard similarity)
자카드 유사도는 두 집합의 합집합에서 교집합의 비율을 구한 것이다. 자카드 유사도는 0에서 1사이의 값을 가지며 두 집합이 같을 때 1, 공통 원소가 없으면 0의 값을 갖는다. 식은 아래와 같다.
두 집합이 아니라 문서가 기준이 되면 아래와 같아진다.
doc1 = "apple banana everyone like likey watch card holder"
doc2 = "apple banana coupon passport love you"
tokenized_doc1 = doc1.split()
tokenized_doc2 = doc2.split()
union = set(tokenized_doc1).union(set(tokenized_doc2))
intersection = set(tokenized_doc1).intersection(set(tokenized_doc2))
print('자카드 유사도: ',len(intersection)/len(union))자카드 유사도 : 0.16666666666666666실습코드는 생략하겠다.
알게된 점
-
딕셔너리를 만들때 dict(zip(key,value)로 만들 수 있다.
-
enumerate사용법
enumerate로 특정 리스트의 인덱스와 값을 얻고 이용을 위해 리스트로 묶는다.
sorted함수를 이용하는데 이 때 enumerate로 얻은 값을 기준으로 정렬한다.
얻은 값의 인덱스를 추출해서 원본 데이터에 iloc으로 넣는다
3.union과 intersection은 집합에 사용되는 함수이므로 set 자료형으로 바꿔줘야 사용할 수 있다.
