학습 범위
컴퓨터 구조를 알아야 하는 이유 및 컴퓨터 구조에 대한 큰 그림,
그리고 컴퓨터를 어떻게 작동시키는지 알아가는 시간이다.
컴퓨터 구조 시작하기
컴퓨터 구조를 알아야 하는 이유
- 프로그램을 개발하다 문제가 발생했을 때 문제 상황을 빠르게 진단할 수 있고, 문제 해결의 실마리를 다양하게 찾을 수 있다.
- 컴퓨터 구조를 이해하고 있다면 컴퓨터는 '미지의 대상'이 아닌 '분석의 대상'이 된다.
- 코드만 작성할 줄 아는 개발자를 넘어 다양한 문제를 스스로 해결할 줄 아는 개발자로 만들어 준다.
- 서버 컴퓨터 구매 혹은 클라우드 서비스 이용 시 성능, 용량, 비용을 비교 분석하여 최선의 선택을 할 수 있다.
더 알아보기
컴퓨터 구조의 큰 그림
우리가 알아야 할 컴퓨터 구조 지식은 두 가지로 나뉜다.
여기서는 다 기억하려고 하기 보다는 큼직하게 느낌만 알고 넘어가도록 하자.
- 컴퓨터가 이해하는 정보 | 컴퓨터는 0과 1로 표현된 정보만을 이해한다.
- 데이터 data
컴퓨터가 이해하는 숫자, 문자, 이미지, 동영상 등의 정적인 정보.
컴퓨터와 주고 받거나 컴퓨터에 저장된 정보를 통칭할 때도 사용되는 표현. - 명령어 instruction
데이터를 움직이고 컴퓨터를 작동시키는 정보.
컴퓨터를 실질적으로 작동시키는 데 필요한 정보.
- 데이터 data
- 컴퓨터의 네 가지 핵심 부품
- 중앙처리장치(CPU) Central Processing Unit
메모리에 저장된 명령어를 읽어들이고, 읽어들인 명령어를 해석하고, 실행하는 부품.
산술논리연산장치(ALU), 레지스터, 제어장치로 구성.- 산술논리연산장치(ALU) Arithmetic Logic Unit
계산만을 위해 존재하는 부품, 쉽게 말해 계산기.
컴퓨터 내부에서 수행되는 대부분의 계산 수행. - 레지스터 register
프로그램을 실행하는 데 필요한 값들에 대한 임시 저장 장치.
각기 다른 이름과 역할을 가진 여러 개의 레지스터 존재. - 제어장치(CU) Control Unit
제어 신호를 내보내고 명령어를 해석하는 장치.
메모리 읽기/쓰기 등의 제어 신호를 보낸다.
- 산술논리연산장치(ALU) Arithmetic Logic Unit
- 주기억장치(메모리) main memory
현재 실행되는 프로그램의 명령어와 데이터를 저장하는 부품.
프로그램이 실행되려면 반드시 메모리에 저장되어 있어야 한다.
메모리에 저장된 값에 빠르고 효율적으로 접근하기 위해 "주소 address"라는 개념 사용.
가격에 비해 저장 용량이 적고 전원이 꺼지면 저장된 내용을 잃는다는 특징. - 보조기억장치 secondary storage
전원이 꺼져도 저장된 내용을 잃지 않음으로써 주기억장치를 보조하는 저장 장치.
현재 실행되는 프로그램의 원본을 포함하여 보관할 프로그램을 저장하는 공간. - 입출력장치 input/output device
컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환하는 장치.
보조기억장치와 함께 "주변장치"로 통칭되기도 한다.
- 중앙처리장치(CPU) Central Processing Unit
컴퓨터의 네 가지 핵심 부품을 간단히 도식화하면 다음과 같다.
각 부품의 세부사항들은 앞으로 자세히 학습하는 과정에서 알게 될 것이다.
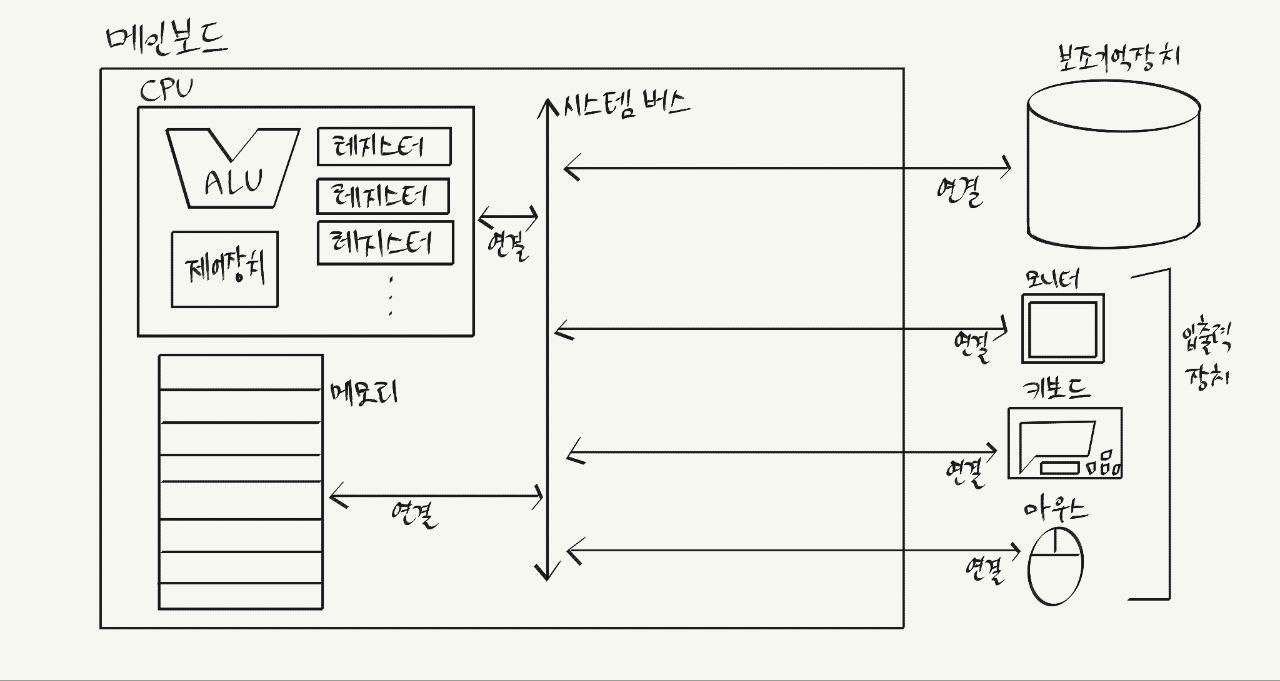
네 가지 핵심 부품 외에도 "메인보드"와 "시스템 버스"가 추가적으로 언급된다.
- 메인보드 main board (a.k.a. 마더보드 mother board)
컴퓨터의 핵심 부품들이 연결된 판.
여러 컴퓨터 부품을 부착할 수 있는 슬롯과 연결 단자 존재. - 시스템 버스 system bus
메인보드에 연결된 부품들이 서로 정보를 주고받는 "버스"라는 이름의 통로 중 하나.
컴퓨터의 핵심 부품들을 연결하는 가장 중요한 연결 통로.
주소 버스, 데이터 버스, 제어 버스로 구성.- 주소 버스 address bus
주소를 주고 받는 통로. - 데이터 버스 data bus
명령어와 데이터를 주고 받는 통로. - 제어 버스 control bus
제어 신호를 주고 받는 통로.
- 주소 버스 address bus
데이터를 읽고자 할 땐 주소 버스와 제어 버스를 이용하여
주소 버스로 전달된 주소의 메모리 내용이 CPU에 전달되며,
데이터를 쓰고자 할 땐 주소 버스와 데이터 버스와 제어 버스를 이용하여
CPU에서 데이터 버스를 통해 전달된 내용이 주소 버스로 전달된 주소의 메모리에 저장된다.
더 알아보기
【↗[컴퓨터 공학 기초 강의] 2강. 컴퓨터 구조의 큰 그림】
【↗[컴퓨터 공학 기초 강의] 3강. 컴퓨터의 4가지 핵심 부품 직접 보기】
데이터
0과 1로 숫자를 표현하는 방법
- 비트 bit | 컴퓨터가 이해하는 가장 작은 정보 단위로, 0 또는 1의 두 가지 정보 표현.
개의 비트는 가지 상태 표현 가능. - 바이트 byte | 여덟 개의 비트를 묶은 단위로, 256가지 상태 표현 가능.
| 이름 | 크기 |
|---|---|
| 1바이트 (1byte) | 8비트 (8bit) |
| 1킬로바이트 (1kB) | 1000바이트 (1000byte) |
| 1메가바이트 (1MB) | 1000킬로바이트 (1000kB) |
| 1기가바이트 (1GB) | 1000메가바이트 (1000MB) |
| 1테라바이트 (1TB) | 1000기가바이트 (1000GB) |
| ⋮ | ⋮ |
1000개가 아닌 =1024개 단위로 표현한 것은 KiB, MiB, GiB, TiB, ...라고 한다.
과거엔 혼용했지만 이제는 단위가 커지며 오차가 커져 명확히 구분하는 편.
이러한 비트를 이용하여 0과 1만으로 숫자를 표기하는 방식은 이진법 binary.
0~9를 이용하여 9를 넘어가면 자리 올림을 하는 십진법처럼
0~1을 이용하여 1을 넘어가면 자리 올림을 하는 방식.
이진법으로 표기한 숫자 즉, 이진수는 십진수와 구분하기 위해 다음과 같이 표기한다.
- 수학에서는 주로, 1000
- 코드에서는 주로, 0b1000
이진법으로 음수를 표현할 땐 보통 2의 보수 two's complement 를 이용한다.
"2의 보수"의 사전적 의미는 "어떤 수를 그보다 큰 에서 뺀 값"을 나타낸다.
그 값을 간단히 구하기 위해서는 모든 0과 1을 서로 뒤집고 거기에 1을 더하면 된다.
어떤 이진수가 있을 때 그것만으로는 이 값이 양수인지 2의 보수로 나타낸 음수인지 알 수 없기에
컴퓨터 내부에서 숫자를 다룰 때는 이 수가 양수인지 음수인지 나타내는 플래그를 사용하곤 한다.
이 플래그가 양수를 나타낼 때 0101는 5로 해석되며
이 플래그가 음수를 나타낼 때 0101는 -11로 해석된다.
이진수는 두 가지 값으로만 숫자를 표현하므로 작은 숫자를 나타낼 때도 자릿수가 많아진다.
이런 문제를 해결하기 위해 이진수 네 자리씩 묶어서 한 문자로 나타내는 십육진법을 사용할 수 있다.
십육진법은 말 그대로 0~15를 이용하여 16을 넘어가면 자리 올림을 하는 방식으로,
10~15의 값은 A~D로 표기한다.
그리고 십진수와 구분하기 위해 다음과 같이 표기한다.
- 수학에서는 주로, dd48
- 코드에서는 주로, 0xdd48
16이 2를 n제곱해서 구할 수 있는 수이기 때문에 이진수와 십육진수 사이의 변환은 간편하다.
이진수를 십육진수로 변환할 땐 네 자리씩 끊어서 변환하면 되고,
십육진수를 이진수로 변환할 땐 각각의 값을 네 자리 이진수로 변환하여 이어붙이면 된다.
더 알아보기
0과 1로 문자를 표현하는 방법
- 문자 집합 character set
컴퓨터가 인식하고 표현할 수 있는 문자의 모음.
이것에 속해 있는 문자만 이해할 수 있고 그 외에는 이해할 수 없다. - 인코딩 encoding
문자 집합에 속한 문자를 0과 1로 이루어진 문자 코드로 변환하는 과정.
같은 문자 집합에 대해서도 다양한 인코딩 방법이 있을 수 있다. - 디코딩 decoding
0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정.
인코딩의 반대 과정이라고 할 수 있다.
대표적인 문자 집합과 인코딩 방식을 알아보자.
- 아스키 코드 ASCII; American Standard Code for Information Interchange
영어 알파벳과 아라비아 숫자, 일부 특수 문자를 포함하는 초창기 문자 집합 중 하나.
7비트로 표현되는 128개의 값이 문자와 일대일 대응.
아스키 문자 집합에 속한 문자를 "아스키 문자", 그것에 대응하는 숫자를 "아스키 코드"라고 한다.
1비트 추가하여 1바이트의 확장 아스키가 등장하였으나, 다양한 문자를 담기엔 역부족. - EUC-KR
한글을 인코딩할 수 있는 방식.
초성, 중성, 종성의 조합으로 완성된 글자에 고유한 코드를 부여하는 완성형 인코딩 방식.
(반대로 각각의 초성, 중성, 종성에 고유한 코드를 부여하여 조합하는 건 조합형 인코딩 방식.)
2바이트씩 사용하여 자주 사용하는 2350개 정도의 한글 단어 표현 가능.
확장 버전인 마이크로소프트의 CP949 또한 한글 전체를 표현하기엔 부족. - 유니코드 unicode
모든 나라 언어의 문자 집합과 인코딩 방식을 통일하여 인코딩의 수고로움을 덜기 위한 방식.
대부분 나라의 문자, 특수문자, 이모티콘 등을 포함하여 현대 문자 표현에 가장 많이 사용.
한글 표현에는 EUC-KR과 마찬가지로 완성형 인코딩 방식 사용. - UTF-8
유니코드 인코딩 방식은 UTF-로 표기되는데, 그 중 가장 대중적인 것.
유니코드 문자에 부여된 값의 범위에 따라 1바이트~4바이트로 인코딩.
한글의 경우 3바이트로 표현.첫 코드 포인트 마지막 코드 포인트 1바이트 2바이트 3바이트 4바이트 0000 007F 0××××××× - - - 0080 07FF 1 1 0 ××××× 1 0 ×××××× - - 0800 FFFF 1 1 1 0 ×××× 1 0 ×××××× 1 0 ×××××× - 10000 10FFFF 1 1 1 1 0 ××× 1 0 ×××××× 1 0 ×××××× 1 0 ××××××
ex. "한" → D55C → 1101 0101 0101 1100 → 11101101 10010101 10011100
더 알아보기
명령어
소스 코드와 명령어
프로그래밍 언어로 작성한 모든 소스 코드는 컴퓨터 내부에서 명령어로 변환된다.
컴퓨터는 프로그래밍 언어 그 자체를 이해하지는 못한다.
- 저급 언어 low-level programming language
컴퓨터가 직접 이해하고 실행할 수 있는 언어.- 기계어 machine code
0과 1의 명령어 비트로 이루어진 언어.
이진수 혹은 십육진수로 표기할 수 있다. - 어셈블리어 assembly language
기계어를 읽기 편한 형태로 일대일 대응하여 번역한 언어.
기계어에 비해 읽기 수월하지만 복잡한 프로그램 만들기는 난해.
임베디드 개발자, 게임 개발자, 정보 분야 등의 개발자는 사용하게 될 수 있다.
- 기계어 machine code
- 고급 언어 high-level programming language
사람을 위한 언어로, 대부분의 프로그래밍 언어를 포함.
저급 언어로 변환하여 명령어 형태가 되어야 실행 가능.- 컴파일 언어
컴파일 방식으로 작동하는 프로그래밍 언어.
컴파일러에 의해 소스 코드 전체가 저급 언어로 변환되어 실행.- 컴파일러 compiler
개발자가 작성한 소스 코드 전체를 쭉 훑어보며 문법적인 오류, 실행 가능 여부, 불필요한 코드 존재 여부 등 확인하며 저급 언어로 변환.
소스 코드 내에서 오류를 하나라도 발견하면 컴파일 실패.
이 때, 만들어지는 저급 언어 코드를 목적 코드 object code 라고 한다.
이 목적 코드에 외부 기능을 연결 짓는 링킹 과정을 거치면 실행 파일이 된다.
- 컴파일러 compiler
- 인터프리터 언어
인터프리트 방식으로 작동하는 프로그래밍 언어.
인터프리터에 의해 소스 코드가 한 줄씩 실행.- 인터프리터 interpreter
소스 코드를 한 줄씩 저급 언어로 변환하여 실행하는 도구.
소스 코드 전체를 저급 언어로 변환하는 시간을 기다릴 필요 없다.
오류가 발생하기 직전 줄까지는 수행 가능.
- 인터프리터 interpreter
- 컴파일 언어
요즘은 컴파일 방식과 인터프리 방식이 혼용되어 있는 경우도 있다.
더 알아보기
명령어의 구조
명령어는 "무엇을 대상으로, 어떤 작동을 수행하라"는 구조로 되어 있다.
- 오퍼랜드 operand
연산에 사용할 데이터 또는 그것이 저장된 위치.
오퍼랜드 필드에 담겨 전달된다.
데이터 그 자체보다는 그것이 저장된 위치를 저장할 때가 많아 주소 필드라고도 한다.
없을 수도 있고 여러 개일 수도 있다.
오퍼랜드가 없는 명령어를 0-주소 명령어, 개 있는 명령어를 -주소 명령어라고 한다.
연산의 대상이 되는 데이터가 저장된 위치를 유효 주소 effective address 라고 한다. - 연산 코드 operation code
명령어가 수행할 연산.
연산 코드 필드에 담겨 전달된다.
기본적인 연산 코드 유형은 크게 네 가지로 나눌 수 있다.- 데이터 전송
- 산술/논리 연산
- 제어 흐름 변경
- 입출력 제어
명령어 길이는 특정 비트로 정해져 있고, 연산 코드 필드 길이 또한 특정 비트로 정해져 있다.
오퍼랜드는 비트의 길이를 나누어 사용하여, 오퍼랜드 수가 많을수록 하나의 크기가 작다.
이러한 길이 제한 때문에 데이터 그 자체보다는 메모리나 레지스터의 주소를 사용하는 경향.
유효 주소를 찾는 방법 즉, 주소 지정 방식 addressing mode 에는 여러 가지가 있다.
그 중 대표적인 방식 몇 가지를 알아보도록 하자.
- 즉시 주소 지정 방식 immediate addressing mode
오퍼랜드 필드에 연산에 사용할 데이터를 직접 명시하는 방식.
데이터를 찾아오지 않아도 되어 빠르지만, 데이터의 크기가 제한적. - 직접 주소 지정 방식 direct addressing mode
데이터가 메모리에 있을 때, 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식.
표현할 수 있는 유효 주소에 제한이 생길 수 있다. - 간접 주소 지정 방식 indirect addressing mode
데이터가 메모리에 있을 때, 오퍼랜드 필드에 유효 주소가 저장된 메모리의 주소를 명시하는 방식.
데이터와 유효 주소 모두 메모리에 존재.
직접 주소 지정 방식보다 표현할 수 있는 유효 주소 범위가 넓어진다.
두 번의 메모리 접근이 필요하여 상대적으로 느리다. - 레지스터 주소 지정 방식 register addressing mode
데이터가 레지스터에 있을 때, 오퍼랜드 필드에 데이터를 저장한 레지스터를 직접적으로 명시하는 방식.
메모리에 저장되어 있는 것보다 빠르게 접근 가능.
한정된 레지스터 크기로 인해 데이터의 크기가 제한적.
(이 부분에서 의문이 들어 질문을 남김.) - 레지스터 간접 주소 지정 방식 register indirect addressing mode
데이터가 메모리에 있을 때, 오퍼랜드 필드에 유효 주소가 저장된 레지스터의 주소를 명시하는 방식.
데이터는 메모리에, 유효 주소는 레지스터에 존재.
간접 주소 지정 방식과 비슷하지만 메모리보다 레지스터가 접근 속도 빨라 상대적으로 빠르다.
더 알아보기
【↗[컴퓨터 공학 기초 강의] 7강. 명령어의 구조와 주소 지정 방식】
【↗[컴퓨터 공학 기초 강의] 8강. C언어의 컴파일 과정(추가 강의)】
미션 수행하기
이번 주 미션
- 기본 미션 | p. 51의 확인 문제 3번, p. 65의 확인 문제 3번 풀고 인증하기
- 선택 미션 | p. 100의 스택과 큐의 개념을 정리하기
기본 미션
미션은 P.51 & P.65의 3번 문제뿐이지만, 이왕 학습하고 확인 문제를 푸는 거 다 풀어보자.
P.35 [01-1 | 컴퓨터 구조를 알아야 하는 이유] 확인 문제
- 컴퓨터 구조를 알아야 하는 이유로 적절하지 않은 것을 고르세요.
① 문제 해결을 위한 다양한 실마리를 찾을 수 있습니다.
② 프로그램을 빠르게 구현할 수 있습니다. → 구현 속도하고는 무관하다.
③ 개발한 프로그램의 성능과 용량을 고려할 수 있습니다.
④ 개발한 프로그램의 비용을 고려할 수 있습니다.
- 다음 설명의 빈칸에 들어갈 알맞은 내용을 보기에서 골라 써 보세요.
[보기| 미지의 대상, 분석의 대상]
"컴퓨터 구조를 이해하면 우리는 컴퓨터를 [① 미지의 대상 ]에서 [② 분석의 대상 ]으로 인식하게 됩니다."
P.50~51 [01-2 | 컴퓨터 구조의 큰 그림] 확인 문제
- 다음 설명의 빈칸에 들어갈 알맞은 내용을 보기에서 골라 써 보세요.
[보기| 명령어, 데이터, CPU, 메모리, 보조기억장치]
"컴퓨터가 이해하는 정보에는 [① 명령어 ]와 [② 데이터 ]가 있습니다."
- 컴퓨터의 네 가지 핵심 부품 중 명령어를 해석하고 실행하는 장치를 고르세요.
① 보조기억장치
② 입출력장치
③ CPU
④ 주기억장치
- 다음 설명의 빈칸에 들어갈 알맞은 내용을 써 보세요.
"프로그램이 실행되려면 반드시 [ 메모리 ]에 저장되어 있어야 합니다."(요것이 이번주 기본 미션!!)
- 컴퓨터의 부품과 역할을 올바르게 짝지으세요.
① 보조기억장치 ― ㉡ 보관할 프로그램 저장
② 메모리 ― ㉠ 실행되는 프로그램 저장
- 시스템 버스와 관련하여 옳지 않은 내용을 고르세요.
① 시스템 버스는 컴퓨터의 핵심 부푼을 분리시키는 버스입니다. → 분리가 아니라 연결!
② 시스템 버스는 주소 버스, 데이터 버스, 제어 버스로 구성되어 있습니다.
③ 메인보드 내부에는 시스템 버스를 비롯한 다양한 버스가 있습니다.
④ CPU가 메모리에 값을 저장할 때 주소 버스, 데이터 버스, 제어 버스를 모두 사용할 수 있습니다.
P.64~65 [02-1 | 0과 1로 숫자를 표현하는 방법] 확인 문제
- 2000MB는 몇 GB인가요?
"2000MB = [ 2 ]GB"
- 다음 중 옳지 않은 것을 골라 보세요.
① 1000GB는 1TB와 같습니다.
② 1000kB는 1MB와 같습니다.
③ 1000MB는 1GB와 같습니다.
④ 1024bit는 1byte와 같습니다. → 1byte는 8bit!
- 1101의 음수를 2의 보수 표현법으로 구해 보세요.
[1 1 0 1]
↓ 모든 0과 1 뒤집기
[ 0 0 1 0 ]
↓ 1 더하기
[ 0 0 1 1 ]
1101을 음수로 표현한 값은 [ 0011 ] 입니다.(요것이 이번주 기본 미션!!)
- DA를 이진수로 표현하면 무엇인가요?
[D A]
↙ ↘
[ 1 1 0 1 ] | [ 1 0 1 0 ]
↘ ↙
DA = [ 11011010 ]
- 이진수와 더불어 십육진수가 많이 사용되는 대표적인 이유는 무엇인가요?
① 이진수와 십육진수 간의 변환이 쉽기 때문입니다.
② 십육진수에 비해 이진수로 표현되는 글자 수가 일반적으로 적기 때문입니다.
③ 십육진수가 십진수보다 일상적으로 더 많이 사용되기 때문입니다.
④ 컴퓨터는 이진수를 이해하지 못하기 때문입니다.
P.75 [02-2 | 0과 1로 문자를 표현하는 방법] 확인 문제
- 68쪽 아스키 코드표를 참고하여 아래의 아스키 코드를 디코딩한 내용을 써 보세요.
"104 111 110 103 111 110 103 → [ hongong ]"
- 다음 중 EUC-KR 인코딩에 대한 설명 중 옳지 않은 것을 고르세요.
① 한국어를 표현할 수 있는 인코딩 방식입니다.
② 조합형 인코딩 방식입니다. → 완성형 인코딩 방식!
③ 하나의 완성된 한글 글자에 코드를 부여합니다.
④ 모든 한글을 표현할 수 없습니다.
- 유니코드 문자 집합에서 '안'에 부여된 값은 C548, '녕'에 부여된 값은 B155입니다. '안녕'을 UTF-8로 인코딩한 값을 구해 보세요.
(C548은 이진수로 1100 0101 0100 1000이고, B155는 이진수로 1011 0001 0101 0101입니다.)
11101100 10010101 10001000 11101011 10000101 10010101
P.89 [03-1 | 소스 코드와 명령어] 확인 문제
- 다음 중 고급 언어가 아닌 것을 모두 고르세요.
① 컴파일 언어
② 인터프리터 언어
③ 기계어 → 저급 언어!
④ 어셈블리 언어 → 저급 언어!
- 다음 중 옳지 않은 것을 고르세요..
① 컴파일 언어는 한 줄이라도 소스 코드 상에 오류가 있다면 실행될 수 없습니다.
② 일반적으로 컴파일 언어보다 인터프리터 언어가 더 빠릅니다. → 컴파일 언어는 한 번 컴파일 해두면 다시 변환하지 않아도 되지만, 인터프리터 언어는 실행할 때마다 한 줄씩 변환해주야 해서 더 느리다. (수정되지 않았음을 확신하면 캐싱 해둔 것을 사용할 수 있겠지만?)
③ 인터프리터는 인터프리터 언어로 작성된 소스 코드를 한 줄씩 저급 언어로 변환하여 실행합니다.
④ 컴파일러는 컴파일 언어로 작성된 소스 코드 전체를 목적 코드로 변환합니다.
P.101 [03-2 | 명령어의 구조] 확인 문제
- 명령어에 대한 설명 중 옳지 않은 것을 고르세요.
① 명령어는 연산 코드와 오퍼랜드로 구성됩니다.
② 연산 코드 필드에는 메모리 주소만 담을 수 있습니다. → 연산 코드 필드에 담는 건 명령어가 수행할 연산.
③ 오퍼랜드 필드는 여러 개 있을 수 있습니다.
④ 명령어에 연산에 사용할 데이터를 직접 명시할 경우 표현할 수 있는 데이터의 크기는 연산 코드의 크기만큼 작아집니다.
- 아래 그림 속 CPU에는 R1, R2라는 레지스터가 있고, 메모리 5번지에 100, 6번지에 200, 7번지 300이 저장되어 있습니다. 아래 명령어를 레지스터 간접 주소 지정 방식으로 수행한다면 결과는 어떻게 나올까요? 아래에 빈칸을 채워 보세요.
"메모리 [① 6 ]번지 속 [② 200 ]이라는 값을 CPU로 가지고 온다."
선택 미션
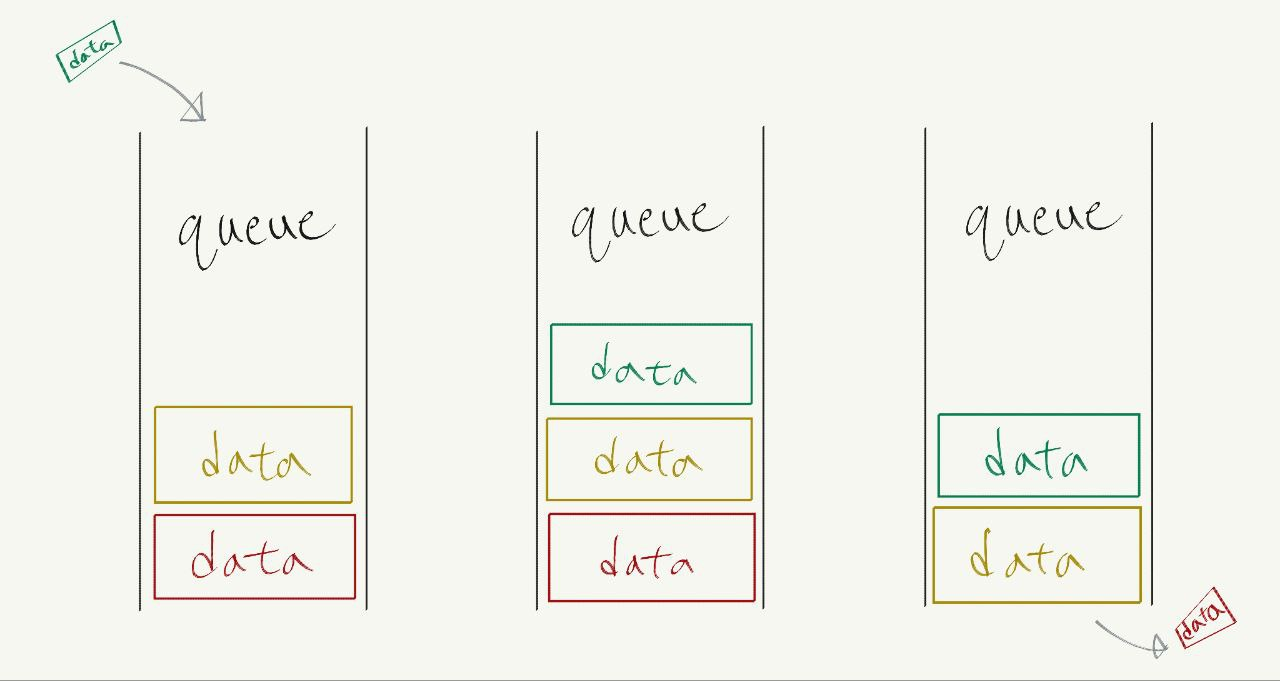
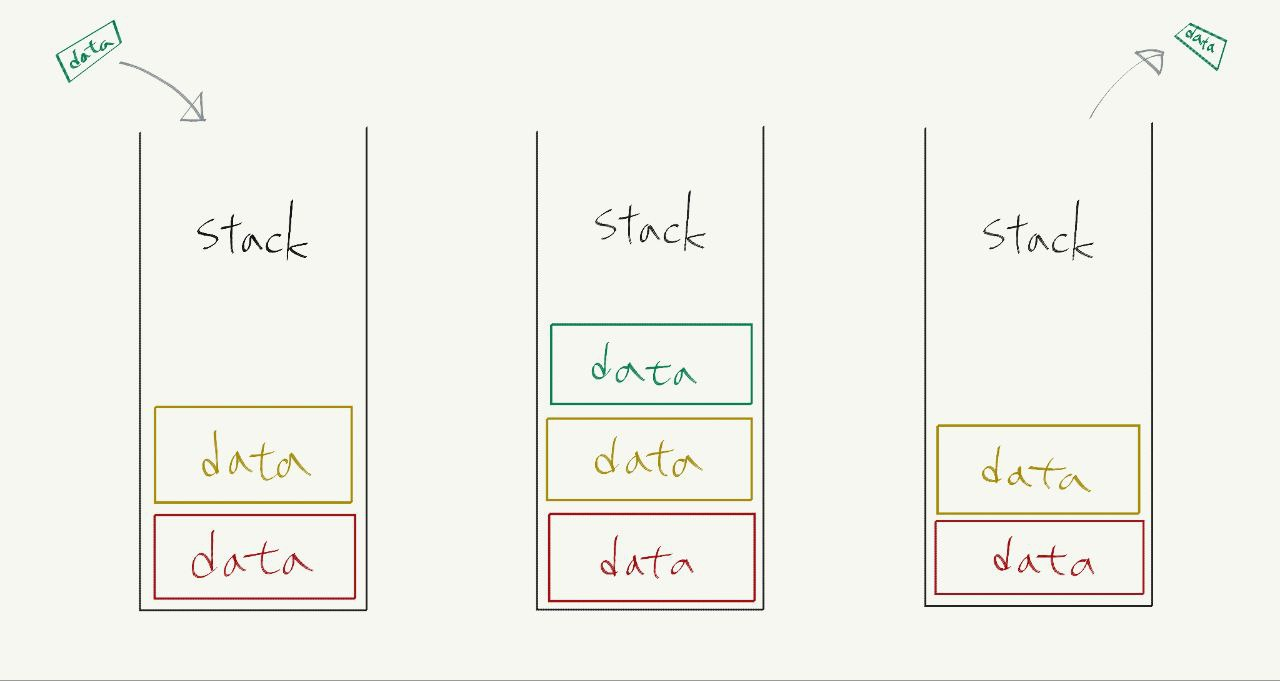
| 스택 stack | 큐 queue |
|---|---|
| 나중에 저장한 데이터를 먼저 빼내는 데이터 관리 방식 | 먼저 저장한 데이터를 먼저 빼내는 데이터 저장 방식 |
| 후입선출(後入先出); LIFO(Last-In First-Out) | 선입선출(先入先出); FIFO(First-In First-Out) |
| PUSH 명령어로 데이터를 맨 뒤에 넣기 | ENQUEUE 명령어로 데이터를 맨 뒤에 넣기 |
| POP 명령어로 데이터를 맨 뒤에서 꺼내기 | DEQUEUE 명령어로 데이터를 맨 앞에서 꺼내기 |
| 입구가 하나인 통에 비유 | 양쪽이 뚤려 있는 파이프에 비유 |
스택에 데이터를 넣고 빼는 것을 간단히 그려 보면 다음과 같다.
큐에 데이터를 넣고 빼는 것을 간단히 그려 보면 다음과 같다.