 Image Source
Image Source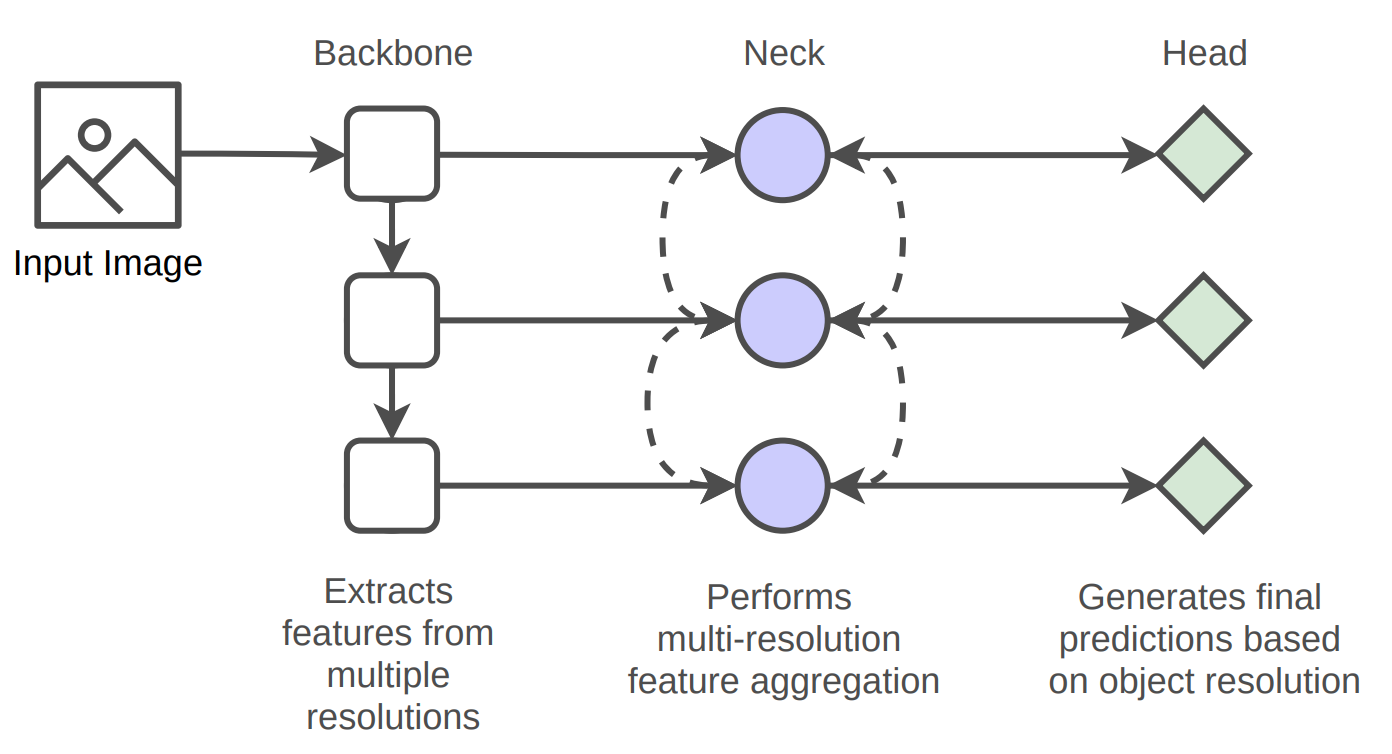 Image Source
Image Source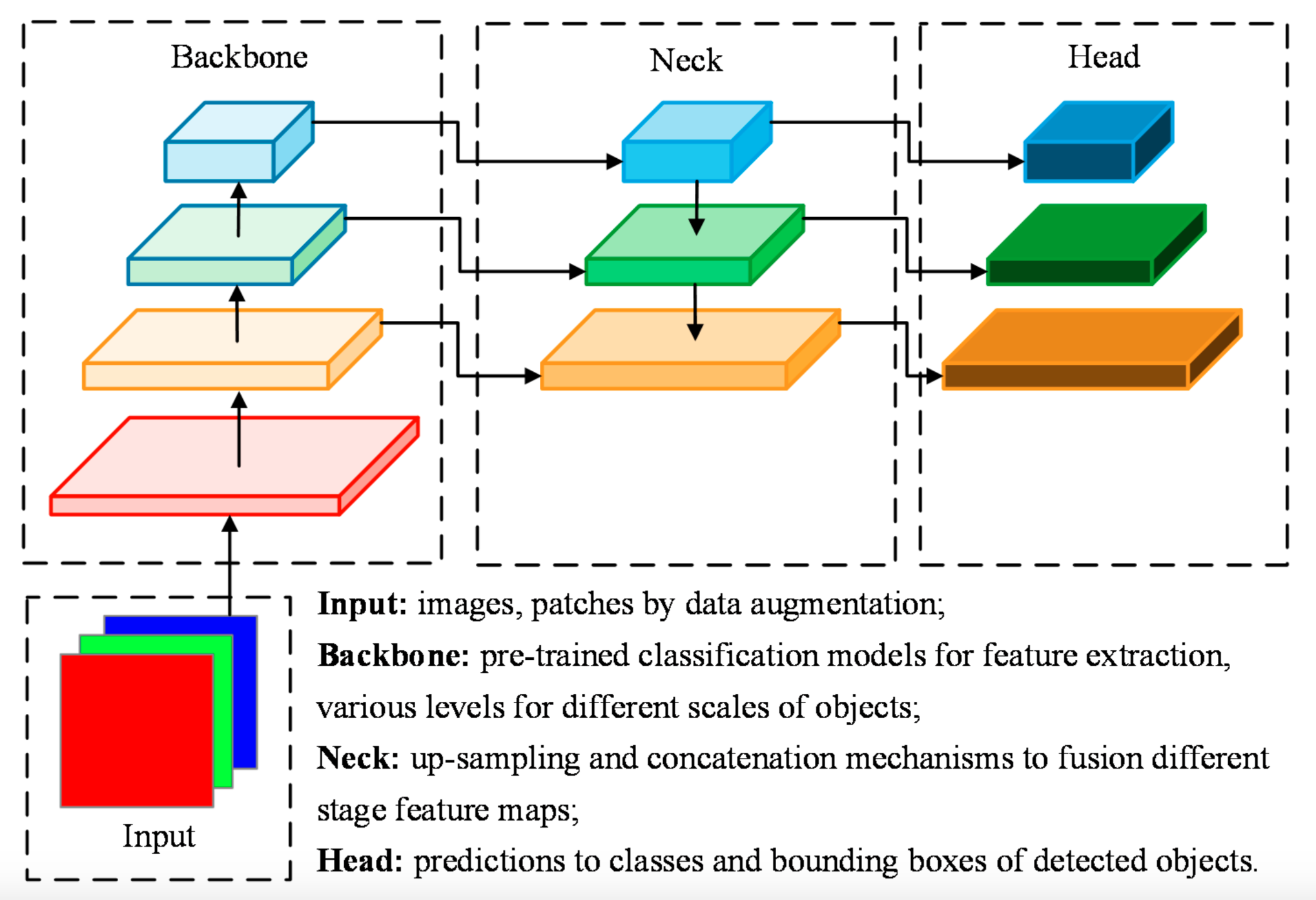
 Image Source(마지막은 YOLO v5의 architecture)
Image Source(마지막은 YOLO v5의 architecture)
- Backbone
- Input을 feature map으로 변환해주는 부분
- ImageNet dataset으로 pre-train시킨 VGG, ResNet50 등이 대표적인 예
- 단순히 말해, input을 여러 conv layer에 통과시켜 feature map을 내놓는 것(각 layer를 통과할 때마다 feature map이 나옴. 보통 layer를 통과할수록 edge - part - ... 이런 식으로 feature가 extract됨)
- Neck
- Backbone에서 extract된 feature들을 적절하게 조화시킴(feature map을 좀 더 정교하게 조정하는 과정이라고도 볼 수 있음)
- FPN, PANet, BiFPN 등이 대표적인 예
- 이전 map을 upsampling하여 크기 키우고, backbone에서의 feature map을 concat 등의 방식으로 같이 반영시킴
- Top-down 방식, bottom-up 방식 모두 존재
- Head
- Localization 및 classification 수행
- Neck에서 여러 map을 두었기 때문에, 각 map에 대해 위 두 작업을 수행하고 결과적으로 하나의 image에서 여러 object를 효과적으로 detect할 수 있음(이 부분에 대해 궁금한 점이 있어 아래 Question에 적어둠)
Question
- Backbone과 neck 구조가 있어야만 하나의 image에서 여러 object를 detect할 수 있는 건가? YOLO v4 paper에서 가져온 첫 번째 사진을 보면 neck의 map 하나에도 여러 bounding box가 그려져 있는데, 그러면 backbone과 neck은 여러 object를 검출하는 데에 필수적이라기보다는 "다양한 scale의" 여러 object를 검출하는 데에 효과적인 구조라고 해석해야 하는 건가?
