Static camera 영상에 대해 object detection을 효과적으로 수행할 수 있는 방법을 찾던 중, Geometry-Aware Spatio-Temporal Network(GAST-Net)를 접하게 되었다. 해당 논문의 내용을 간략하게 정리해보았다.
개념 정리
본격적으로 논문 내용을 다루기에 앞서 이전에 제대로 알지 못했던 용어들의 뜻을 간단히 정리해보았다.
- Depth: 이미지에서의 물체의 깊이. 즉 멀리 있는 물체는 깊이 있다고 표현.
- Occlusion: 두 물체가 image 상에서 너무 가까이 있어서 하나의 object로 보이게 되는 현상. 동일한 object가 움직이는 것임에도 불구하고 다른 object와 겹쳐진 상황에서는 다른 object로 인식해버림.
- Interpolation: 20살일 때의 키와 40살일 때의 키를 보고 30살일 때의 키를 예측하는 것으로 이해할 수 있음. 반대로 extrapolation의 경우 1살 때부터의 지금까지의 키를 보고 10년 후의 키를 예측하는 것으로 이해할 수 있음. 주가 예측과 비슷한 느낌(Interpolation과 extrapolation의 구체적인 설명은 https://darkpgmr.tistory.com/117 참고)
모델 설명
논문은 two-stage anchor-based(ex. Faster R-CNN 등의 R-CNN 계열) 모델이 localization과 classification을 순차적으로 진행하고, regional proposal 과정이 동반되어서 연산량이 많다고 설명한다(다만 정확도가 높다는 장점은 있다). GAST-Net은 CornerNet과 같이 single-stage anchor-free 모델이기 때문에 연산량이 그리 많지 않다고 한다.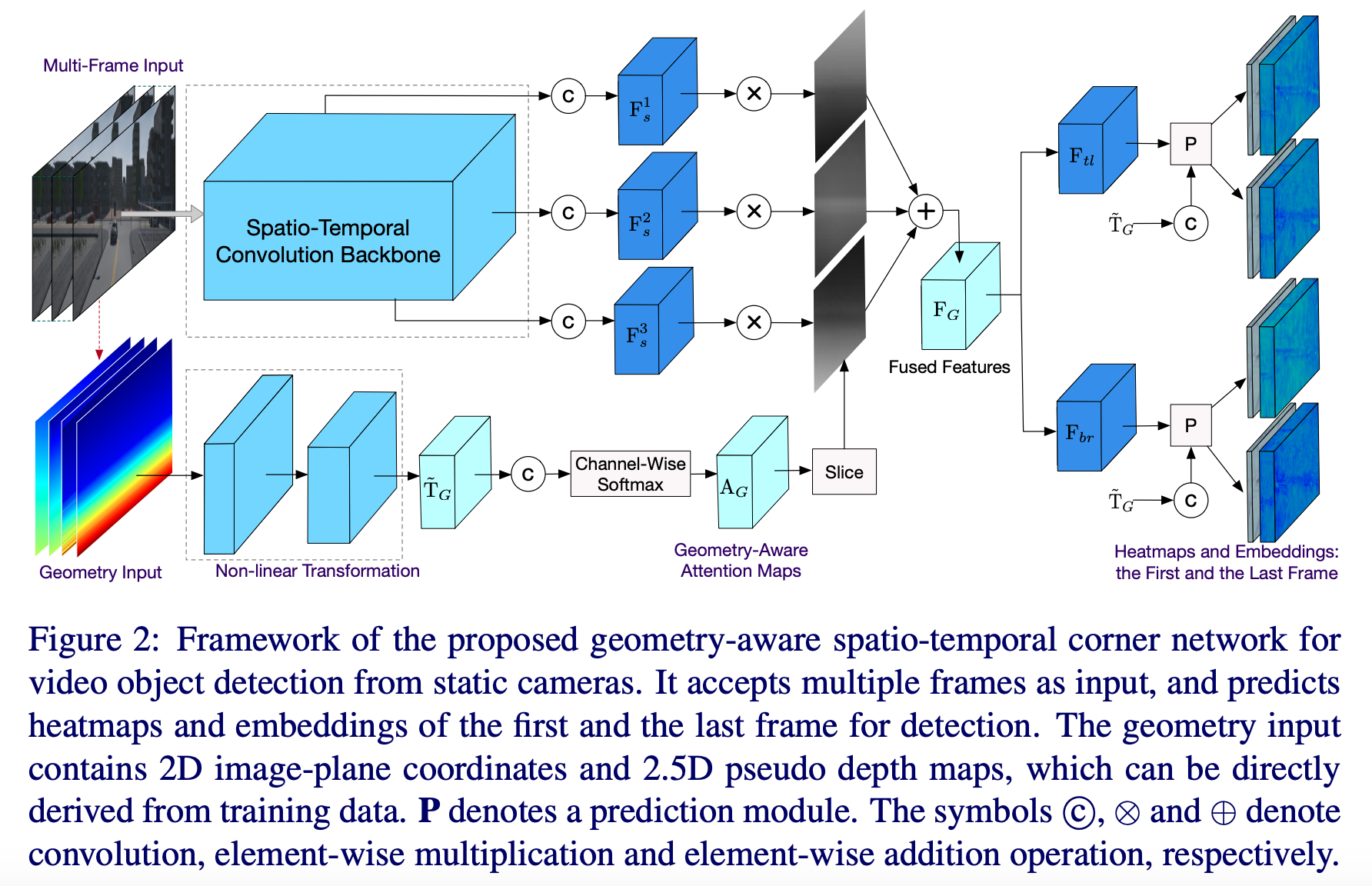
- Input
- Short clip
- Image가 아닌 clip으로 넣는 이유는 앞뒤 temporal 정보를 반영하기 위해
- Geometry information
- Image geometry: {} 의 형태. 각각은 H*W차원(image geometry는 아직 완벽하게 이해되지 않았다. 추후 구현을 해보면서 감을 잡아나가야 할 것 같다).
- Scene geometry(2.5D pseudo depth map): 각 class, 각 camera viewpoint마다 구하며 크기는 이미지와 동일하게 H*W. 각 row마다 해당 row에 존재하는 bounding box의 height의 min과 max 두 값의 평균을 계산. 예를 들어, row 30에 존재하는 person class에 해당하는 bounding box가 4개 있고 min height가 10, max height가 18이면 해당 row의 값은 14. Bounding box가 존재하지 않는 row의 경우 bounding box가 존재하는 row들에 대해 bilinear interpolation 실시하여 값 지정. 위 사진에서 그라데이션 input에 해당함(이라고 표현).
- Short clip
- Encoding
- Short clip
- 3D convolution-based backbone: Variants of VGG, ResNet50(이 결과물이 )
- 이러한 를 물체의 scale 수만큼 생성()
- Geometry information
- Non-linear Transformation: 위 을 모두 concat한 뒤 해당 값에 대해 Conv-BN-ReLU 처리(이 결과물이 )
- Channel-wise로 실시한 결과가 (Geometry-Aware Attention Map)(H*W가 1층으로만 존재하게 됨)
- 이러한 를 물체의 scale 수만큼 생성(, ... , )(pseudo depth map과 같은 geometry info는 scale에 민감하다고 가정)
- 와 를 element-wise multiplication한 뒤 에 대하여 sum하면 그 결과물이 최종 encoding 결과물인
- Short clip
- Decoding
- 가 과 로 project됨 (각각 short clip의 첫 번째 프레임과 마지막 프레임에 대해 bounding box 예측하기 위한 용도)
- 위에서 구한 에 대해 1*1 convolution 실시하고(channel 수는 , 의 1/4로 설정), 과 각각에 concat
- Concat이 이뤄진 과 각각을 input으로 삼아, bounding box의 top-left, bottom-right coordinate의 heatmap(이 지점이 top-left 또는 bottom-right일 확률이 높다) 및 embedding(classification)을 output으로 내놓도록 prediction layer 통과시킴
- 각 프레임이 first와 last의 역할을 둘 다 수행하므로, 각 프레임마다 bounding box prediction이 2가지로 나옴. 이에 대해 NMS(Non-Maximum Suppression)로 최종 bounding box prediction을 내놓음
Loss 설명
- Heatmap(localization = regression): Focal loss
- Cross Entropy는 확률이 낮은 케이스에 페널티를 크게 주고 확률이 높은 케이스에는 페널티를 딱히 안 줌(ex. binary 케이스에서 정답에 대해서는 CE가 0, 오답에 대해서는 CE가 infinity)
- Focal loss의 경우 확률이 높은 케이스에 대해 loss를 크게 낮춤(보다 구체적인 설명은 https://gaussian37.github.io/dl-concept-focal_loss/ 참고)
- Embedding(classification): Push-pull loss
- Pull loss: 동일한 object의 경우 top-left와 bottom-right의 embedding의 거리를 최소화
- Push loss: 다른 object의 경우 top-left와 bottom-right의 embedding의 거리를 최대화
Question
- 앞과 뒤의 temporal info를 모두 반영하기 위해서는 short clip의 첫 번째와 마지막 frame 말고 중간 frame에 대해 bounding box를 예측하는 게 낫지 않나?
- 해결: First와 last에 대해 NMS를 수행하므로 이 문제는 해결됨. 또한 영상 전체의 가장 first frame과 last frame에 대해서는 중간 frame으로 예측을 수행할 수가 없으므로 오히려 first와 last로 구하는 게 적합한 측면 존재.
