영상 주석 생성

- 영상 속 물체를 검출하고 인식
- 물체의 속성과 행위, 물체 간의 상호 작용을 알아내는 일
- 의미를 요약하는 문장을 생성함
- 예전에는 물체 분할, 인식, 단어 생성과 조립 단계를 따로 구현한 후 연결하는 접근방법
- 현재는 딥러닝 기술을 사용하여 통째로 학습
심층학습 접근방법
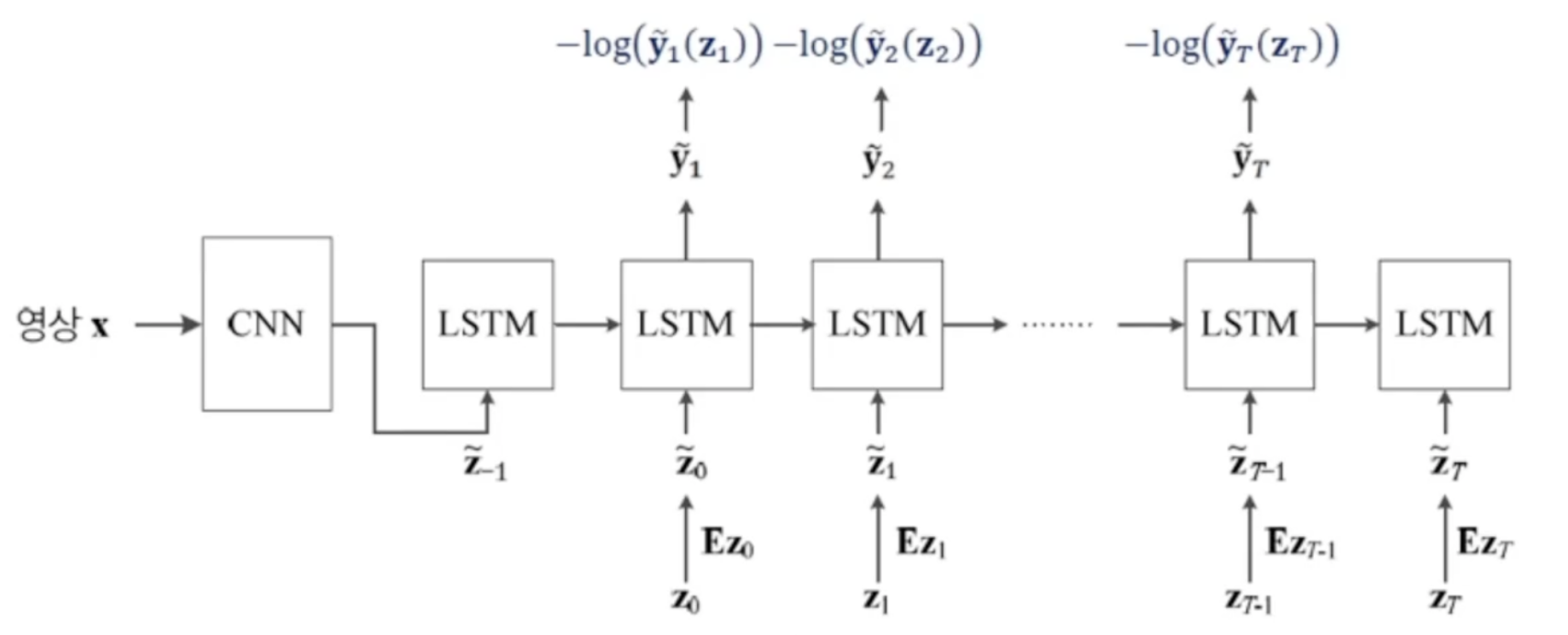
- CNN은 영상을 분석하고 인식
- LSTM은 문장을 생성
훈련집합
- x는 영상, y는 영상을 기술하는 문장
CNN
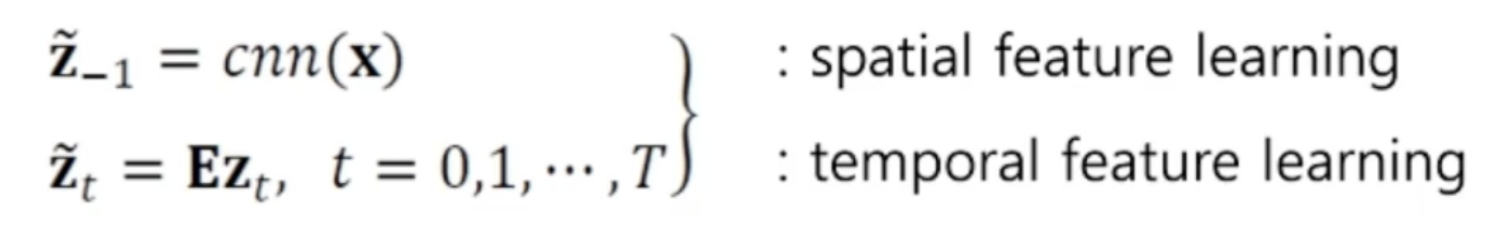
- 입력 영상 x를 단어 임베딩 공간의 특징벡터 z_-1로 변환
- 기계번역에서 인코딩에 대한 결과를 만들듯이 영상으로 인코딩의 결과를 만드는 개념과 비슷함
- 훈련 샘플 y의 단어 z_t는 단어 임베딩 공간의 특징 벡터 z_t근사치로 변환됨
- 위 식의 두 번째 줄에서 행렬E를 이용해 변환
- E는 통째 학습 과정에서 CNN, LSTM과 동시에 최적화됨
학습 과정의 입력
- 영상 x를 CNN에 입력
- y 문장들을 임베딩 공간의 점 행렬E 를 연산한 점으로 변환해 LSTM에 입력
목적함수
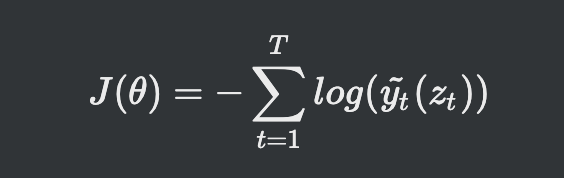
- CNN에서 출력한 값이 LSTM 은닉층으로 전달되서 y의 문장에 E연산된 값을 다음 LSTM 은닉층이 연산한 값에 영향을 끼침
- 이렇게 나온 예측y값과 원래 y값이 일치할수록 예측을 잘한다고 평가
- 로그우도로 일치 정도를 평가
학습이 최적화해야 할 매개변수 집합
- CNN매개변수, LSTM매개변수, 단어 임베딩 매개변수 가 필요
- 전이 학습을 사용하므로 CNN 매개변수는 완전연결층의 가중치
- 단어 임베딩 매개변수는 행렬E
- 매개변수는 통째 학습으로 한꺼번에 최적화 됨
영상 주석 적용 사례
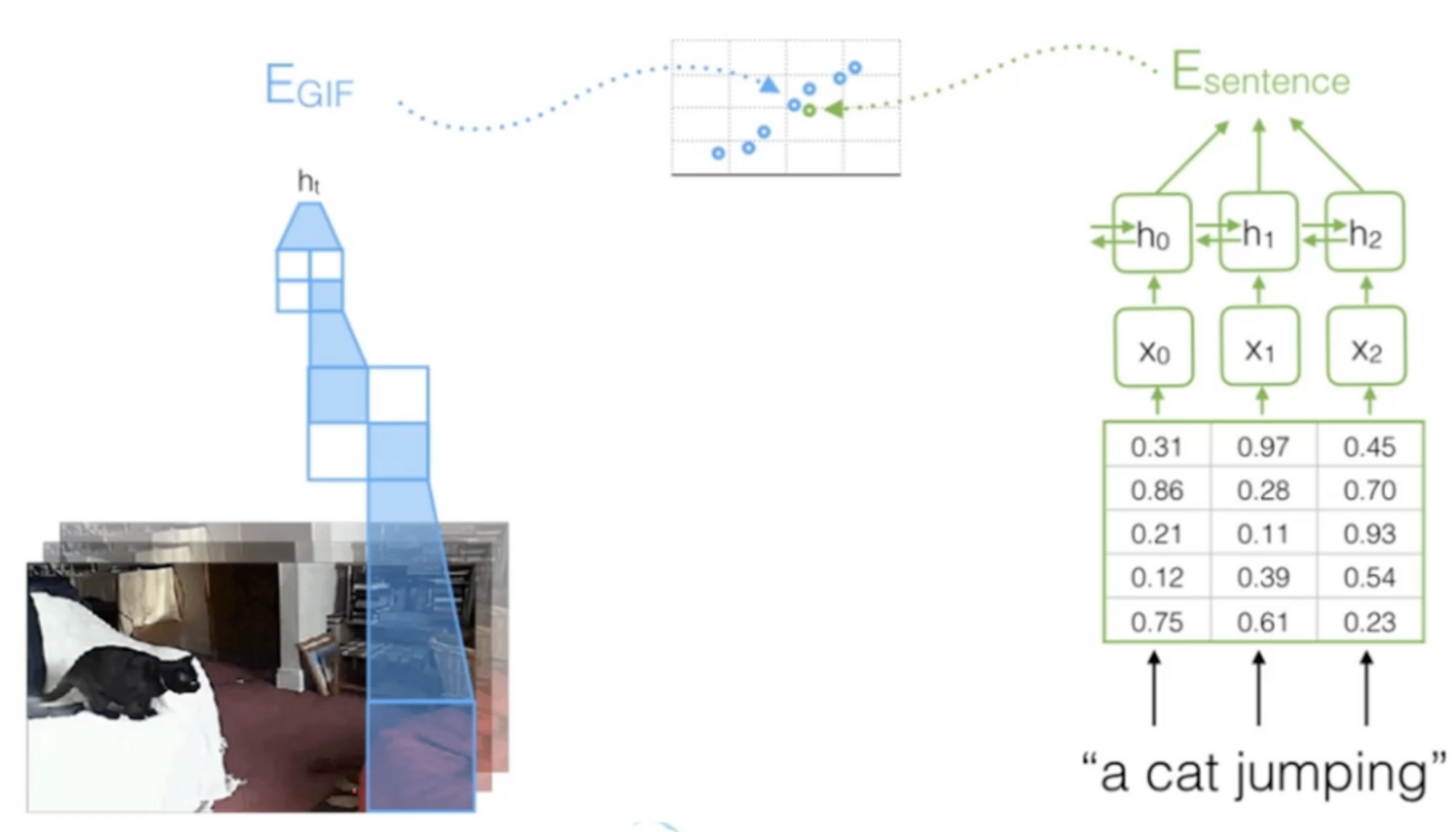

- 영상을 보고 한개의 벡터를 출력한뒤 LSTM에 넘겨주면 결과를 출력함
영상 주석에서의 집중(attention) 적용 사례
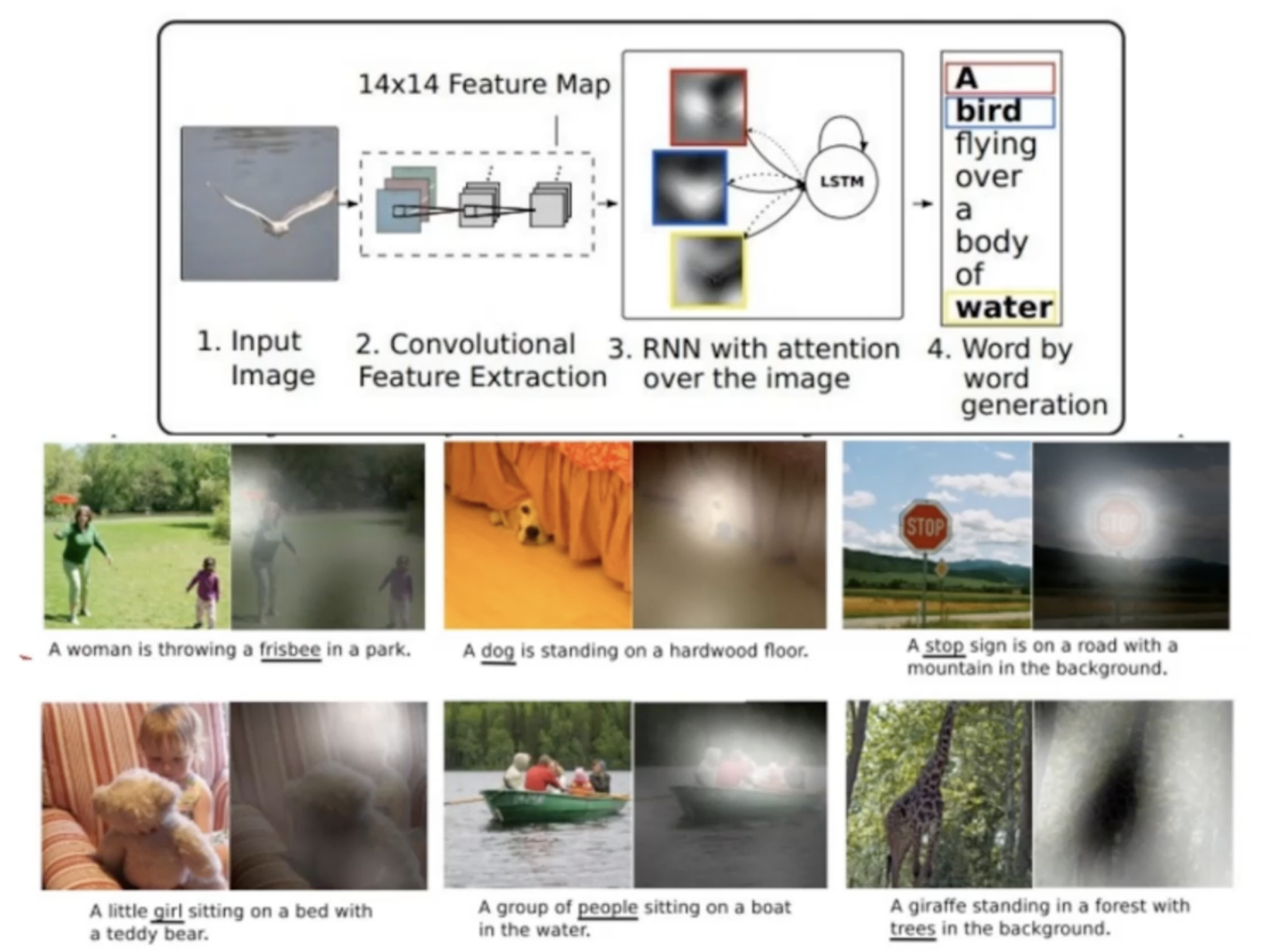
- 이미지중에 중요한 부분을 캐치해서 문장에서의 주어라던지 중요 위치에 그 부분을 배치시킴
영상 질의 응답 적용 사례

- 상황, 물체구분, 출력해야 하는 예측값을 구분함
- 질문을 분석하고 그에 대한 답변을 제시함

컴퓨터가 좋아