Hidden Technical Debt in Machine Learning Systems Abstract (2015, Google)
- 빠른 성과는 손쉽게, 공짜로 얻는 것이 위험하다
- 기술 부채 Framework 사용, 실제 ML 시스템의 유지보수 비용이 막대하게 발생
- ML에서의 특별한 위험 요소 탐색 (경계 침식, 얽힘, 숨은 피드백 루프 등 다양한 패턴)
1. 서론

- 기술 부채 (Technical Debt) : 소프트웨어 공학에서 신속한 움직임에서 발생하는 장기 비용을 이해하는 데 도움을 주기 위한 비유
기술 부채는 미래의 개선을 가능하게 하고 오류를 줄이며 유지 보수성을 개선하지 않으면 발생하는 손해에 대한 부채를 의미한다.
- 기술 부채를 줄이는 법
- Refactoring Code
- 단위 테스트의 개선
- Dead code delete (사용하지 않는 dummy code 삭제)
- 의존성 줄이기
- API 조정
- 문서 개선
- "기술 부채"는 시스템 내부에서 존재하기 때문에 탐지하기 어렵고 ML 시스템에 장기적으로 문제를 야기한다.
모니터링의 어려움
- 전통적 소프트웨어는 캡슐화와 모듈화를 통한 코드의 분리가 가능
- 그러나 현대 ML 시스템은 외부 데이터에 의존하기 때문에 경계의 모호성이 발생
예를 들자면, 한 모델의 출력이 다른 모델의 입력으로 사용되며 다른 시스템의 영향을 줄 수 있다는 것임
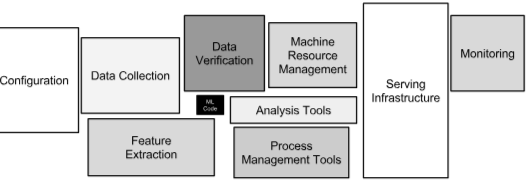
- ML 패키지를 "블랙박스" 처럼 사용하기 때문에 서로 이어붙이는
glue code를 사용, 이는 시스템을 경직되게 만듦모델을 가져와서 사용하는 경우 내부 작동 방식을 이해하기 어렵기 때문에 디버깅이 많이 어려운 문제 발생
- ML 시스템은 외부 환경에 매우 민감하기 때문에 모델의 성능이 급격히 저하될 수 있음 (새로운 데이터나 데이터의 분포 변경)
- 여러 요소들로 보면 코드의 모니터링 및 문제 발견, 수정이 쉽지 않음
2. 캡슐화 및 추상 경계의 부재
- ML 시스템은 데이터가 없이 소프트웨어 논리만으로 표현할 수 없는 세계
- 이로 인해 정돈된 캡슐화가 불가능하며, 이러한 경계의 침식이 발생함에 따라 기술 부채는 끝도 없이 증가하게 된다.
2-1) 얽힘 (Entanglement)
- 기계 학습 시스템은 신호를 혼합하여 얽힘을 만들고, 이 얽힘이 발생함으로써 개선의 분리가 불가능해지는 결과를 초래한다.
- 얽힘 : 모델들 간의 연결성이 강한 경우 한 모델의 개선이 다른 모델에 큰 영향을 주는 것을 의미
Example
1) x₁, ... , xₙ 을 사용하는 모델이 있는 경우 → 입력 분포 값의 변경이 일어나면 모든 특징의 중요성, 가중치의 변경이 일어나게 된다
2) xₙ₊₁을 추가하더라도 유사한 변화, Feature xⱼ 를 삭제하는 것도 유사한 변화를 일으킬 수 있음
이 처럼 입력은 언제든 변하며, 그 입력에 따라 뒤에 값들은 영향을 받는다 - CACE (Changing Anything Changes Everything)
- Input(입력 값) 뿐만 아니라 hyper-parameters, 학습 설정, 수렴 임계값, 샘플링 기법 등 모든 조정에 적용이 된다.
- 이를 완화하기 위한 방법 中 하나, 앙상블 (Ensemble)
- 각 모델들의 구성을 독립적으로 가져가서 여러 특성을 가진 모델로 앙상블을 하는 것이 최적의 기법
예를 들면 CV Task에서 객체의 다른 특징들을 각각의 모델이 맡아 담당하게 하는 것
- 각 모델들의 구성을 독립적으로 가져가서 여러 특성을 가진 모델로 앙상블을 하는 것이 최적의 기법
2-2) 수정 연쇄 (Correction Cascades)
- 수정 연쇄: 기존에 다른 문제를 해결하던 모델을 약간 수정해서 새로운 문제를 해결하려고 할 때 발생하는 문제
- 기존에 있던 모델 살짝 만져서 수정하면 더 빠르게 Task를 수행할 수 있지 않을까? 의 위험성을 보여준다
mₐ 모델을 활용하여 A의 문제를 해결하다가 A'의 문제를 해결하고 싶을 때 mₐ', A''의 문제를 해결하고 싶을때 mₐ'' 등 서로 모델들 간의 의존성이 발생
- 사용 중 mₐ 모델을 개선해야 되서 수정하게 된다면, 연관성이 있는 모든 모델에 영향을 끼치게 되고, 이를 개선 정체 (improvement deadlock)라고 한다.
- 이를 해결하기 위해서는
1) mₐ 모델을 사용할 때 모든 case들을 구별할 수 있는 특징을 추가하여 같은 모델 내에서 수정 가능하도록 하기
2) 그냥 별도의 모델을 만드는데에 대한 비용을 수용하고 새로 만들기
2-3) 승인 받지 않은 소비자 (Undeclared Consumers)
- ML 모델이 예측 결과를 로그나 파일로 저장해두는데, 이를 다른 시스템이 가져다가 사용할 수 있음.
- 접근 제어가 없는 경우 누가 이 결과를 사용하는지 추적이 안되며 이를 미선언 소비자라고 한다.
Example
A라는 뉴스 추천 모델
이 모델의 결과를 광고 회사 B가 추적해서 광고 타겟팅에 무단 사용
A는 추천을 B의 광고 타겟팅 뉴스만 나오는 편향성이 발생
A를 수정 및 개선 하니 B는 광고 타겟팅 뉴스가 안나오는 현상 발생 - 이 처럼 어디서 사용하는지 추적이 안되기 때문에 기존 모델 수정 및 개선은 다른 시스템에 영향을 끼칠 수 있으며, 변경을 하기에도 쉽지 않고 많은 비용과 손해가 발생
- 다른 시스템에서 사용할 수 없도록 접근 제한 (Access restriction)을 사용하거나, 엄격한 서비스 수준 계약 (SLAs)을 두어야 한다.
3. 데이터 종속성
- 기존 부채는 코드 복잡성과 기술적 부채의 주요 요인으로 지적되어왔다.
- 최근 코드 복잡성과 코드의 종속성은 compiler와 링커의 정적 분석 (디버깅)을 통해 쉽게 식별할 수 있다.
- 하지만 데이터 종속성은 그러한 도구가 없으며, 최근에는 그나마 EDA나 시각화를 통해 데이터간의 관계를 파악
3-1) 불안정한 데이터 의존성 (Unstable Data Dependencies)
- 다른 시스템의 출력을 입력 데이터로 사용할 때 발생할 수 있는 문제로, 추후 모델의 출력이 변경됨에 따라 데이터가 시간이 지나면서 예고 없이 변할 수 있다.
Example
A라는 상품 추천 모델, B의 사용자 관심사 분류 모델의 출력을 데이터로 사용
B 모델의 출력이 변경되면 A의 입력 데이터도 자연스럽게 같이 변함
그럼 A는 상품을 잘 추천하다가 갑자기 B의 데이터 변경으로 인해 출력의 오류 발생 - 이를 해결하기 위해서는 기존에 사용하던 데이터를 복사본으로 만들어 버저닝을 하는 것이다.
- 입력으로 사용하는 데이터를 버저닝을 통해 고정하게 되며, 고정을 통해 최신 버전의 데이터의 무결성이 검증되기 전까지 변경하지 않는 것.
- 하지만 데이터 버저닝 또한 많은 용량의 데이터를 계속 보존해야 하기 때문에 유지 비용이 많이 발생한다.
3-2) 활용도가 낮은 데이터 의존성 (Underutilized Data Dependencies)
- 코드적인 측면에서 활용도가 낮은 의존성은 필요 없는 패키지.
- 활용도가 낮은 데이터는 점차 시간이 지나면서 잊혀지고, 프로그램에 자연스럽게 묻혀있을 수도 있다.
Example
논문에서의 예시는 회사가 새로운 제품 번호 체계로 전환 시
이전 제품은 구번호와 신번호 모두를 가지고, 1년 후 구번호를 삭제 시킬 시
모델은 신번호 뿐만 아니라 구번호에도 의존하기 때문에 문제 발생 - 활용도가 낮은 데이터 종속성은 여러 모델에 스며들 수 있다
1) Legacy Features : 특정 기능을 모델 개발 초기에 넣었는데, 시간이 지나며 새로운 기능이 그 역할을 대체하게 되는 경우
2) Bundled Features : 여러 기능을 그룹화 시켜 사용하는 경우 비슷한 효과를 내거나 같은 효과인데 기능명만 다른 것들을 넣는, 가치가 없는 기능이 포함
3) ε-Features : 성능은 진짜 조금 향상되는데, 복잡성이 너무 높아 오버헤드가 발생하는 경우
4) Correlated Features : 두 개 이상의 특성이 서로 강한 선형 관계를 가지는 경우 한 특성의 값이 변할 때 다른 특성의 값도 함께 변하는 것으로, 상관관계가 너무 높은 경우 다중공선성 문제를 일으키거나 특성 간의 상호작용을 감지하는 데 어려울 수 있음. 이런 경우 한개만 포함하는 것이 모델에 좋은 영향을 끼침
3-3) 데이터 의존성에 대한 정적 분석 (Static Analysis of Data Dependencies)
- 코드 의존성에 대한 정적 분석으로는 컴파일러와 빌드 시스템이 의존성에 대한 분석을 수행해주었다.
- 데이터 종속성에 대한 정적 분석 도구는 훨씬 덜 일반적이고 이에 대한 도구나 경험이 부족한 상황이다.
- 최근에는 데이터 사전을 구축해 주기적으로 관리하는 방법을 채택하거나 자동화된 Feature 관리 시스템을 내부적으로 사용하는 방법이 제시되고 있다.
4. 피드백 루프 (Feedback Loop)
- 실시간 ML 시스템은 시간이 지남에 따라 시스템이 자신의 행동들이 모델의 결과에 영향을 미친다는 것을 의미하며, 이를 분석 부채 (Analysis debt)라고 한다.
- 릴리즈를 하기 전까지는 정적인 실험만 진행하고, 같은 시나리오 대로 수행되지만 릴리즈 후에는 사용자에 따라서 다양한 상황이 벌어질 수 있음
- 심지어 업데이트가 느린 릴리즈 제품의 경우 이 분석 부채의 발생을 알아차리기 매우 어렵다.
4-1) 직접 피드백 루프 (Direct Feedback Loops)
- 모델의 예측이 다음 학습에 사용될 데이터에 영향을 주는 구조 (직접적으로 미래 학습 데이터 선택에 영향을 미침)
Example
넷플릭스 사용자 추천 시스템
넷플릭스가 사용자 A를 추천하고, 영화를 보고 좋아요를 누른 경우 데이터를 다시 모델 학습에 사용
모델은 비슷한 영화를 더 자주 추천 - 일반적으로는 표준 지도학습 알고리즘을 사용하는 것이 일반적이지만, bandit 알고리즘을 사용하는 것이 중요하다.
밴딧 알고리즘?
새로운 선택지를 가끔 시도해보면서, 좋은 결과를 주는 선택을 주로 사용하여 피드백 루프로 인한 편향을 줄이는 것
4-2) 숨겨진 피드백 루프 (Hidden Feeedback Loops)
- 두 개의 시스템이 서로 간접적으로 영향을 미치는 루프
- 일반적으로 직접 피드백 루프보다 발견하기 더 힘들며, 수정하기 어려운 특징이 있음
Example
웹페이지에서 제품 선택 시스템과 리뷰 선택 시스템의 상호작용
주식 시장 예측 모델 간의 상호 작용
한 회사의 예측 모델 개선이 다른 회사의 매매에 영향을 주거나, 한 시스템의 변경이 사용자 행동을 변화시켜 다른 시스템에 영향을 미치는 경우
5. ML 안티 패턴
- ML 시스템에서 실제로 학습 또는 예측에 할당된 코드의 비율은 지극히 낮음
- 다른 모듈을 받아와서 사용하거나 하는 부분이기 때문에 이러한 기계 학습에 대한 리팩토링 진행 시 피해야 할 요소들을 살펴보기
5-1) 글루 코드 (Glue Code)
- ML 연구자들은 일반적 목적의 솔루션을 자가 포함 패키지로 개발하는 경향
- 이러한 패키지들은 mloss.org와 같은 오픈 소스 패키지 사이트나 사내 코드, 패키지, 클라우드 기반 플랫폼에서 제공
- 이러한 라이브러리를 사용하는 경우 접착제 코드 (Glue code) 시스템 디자인 패턴으로 귀결되기 마련이다.
- 당장은 문제가 없지만, 장기적으로 봤을 때는 비용이 많이 든다고 볼 수 있다.
- 만약 라이브러리가 전체적으로 변하게 된다면, 우리가 사용하는 일부분에 큰 피해를 끼치게 되고 그에 따른 수정이 매번 필요함
- 이를 해결하기 위해, 일반 패키지를 재사용하기 보단 C++, Java, C로 재구현 하는 것이 권장된다. 이렇게 변경하여 일반 API로 사용하게 된다면 자원 인프라를 더 사용하며 패키지 변경 비용을 줄일 수 있다!
5-2) 파이프라인 정글 (Pipeline Jungle)
- 글루 코드의 특수한 경우로써 데이터 준비시에 자주 나타나는 현상
- 데이터 준비 시 긁어오는 과정, 병합, 샘플링 등 다양한 과정을 거치게 되는데 이런 파이프라인을 따라서 할 시 난잡하기 때문에 수정이 어렵고 문제를 발견하기 어렵다.
- 이 파이프라인을 전체적인 방향에서 생각해보고, 이 과정을 천천히 나눠서 정확하게 설계한다면 파이프라인 정글을 피할 수 있다. 하나씩 완성해나가게 된다면 전체 파이프라인 구축 후 수정하는 비용보다 훨씬 저렴할 수 있다.
- 글루 코드와 파이프라인 정글은 연구와 엔지니어링 역할의 분리로 인해 생겨나기 때문에, 엔지니어와 연구자가 같이 하이브리드적으로 접근하여 두 문제를 손쉽게 해결할 수 있다!
5-3) 죽은 실험 코드 경로 (Dead Experimental Codepaths)
- 글루 코드와 파이프라인 정글을 해결하기 위해 실험 코드 경로를 여러 조건부 분기로 구현하는데, 적은 실험과 적은 사람이 분기를 만들어 사용하는 경우 비용은 상대적으로 낮다.
- 하지만 여러 사람들이 분기를 새로 만들면서 여러 분기가 발생하게 되고, 이렇게 누적된 코드 분기점들은 복잡해지고 코드 경로간 모든 기능을 테스트하기가 매우 어려워진다.
논문에서 나왔듯이 Knight Capital의 시스템은 여러 분기를 통해 실험을 하고 개선을 진행하고 있었는데, 너무 많은 분기가 생기다 보니 45분 만에 $456, 한화로 약 66만 5천원이 발생
- 이처럼 실험 브랜치가 많이 생기면 복잡해지고 비용이 많이 발생하기 때문에 완료가 되었거나 실험 가치를 잃은 브랜치는 주기적으로 검토하면서 삭제해나갈 필요가 있다.
5-4) 추상화 부채 (Abstraction Debt)
- 위에서 말했던 문제들은 ML 시스템을 지원하기 위한 강력한 추상화의 부족을 강조하고 있다.
- ML은 RDBMS(관계형 DB)만큼 성공적인 기본 추상화가 없다는 점을 지적
- 즉, 시스템 간의 경계가 모호해지고 유지보수가 어려워지는 것을 의미하고 있다.
- MapReduce는 초기에 분산 처리를 위한 대표적 방법이였으나, 반복적인 ML에는 적합하지 않은 것을 발견했다. 왜냐하면 데이터를 매번 새로 읽고 처리해야 하는 문제점 때문이다.
- 파라미터 서버는 더 견고해 보이는 장점이 있지만, 여러 다른 구현 방식이 경쟁하면서 표준화가 어려워졌다.
- 이 처럼 추상화 부채는 데이터, 모델, 예측에 대한 표준화가 없기도 하고 ML 시스템마다 전부 다른 구조를 가지고 있기 때문에 호환성이 떨어진다는 문제를 제시한다.
5-5) 일반적 상황 (Common Smell)
- 소프트웨어 공학에서는 컴포넌트나 시스템의 근본적 문제를 디자인 하였는데, ML에서도 몇 가지 일반적 상황을 제시할 수 있다. (하지만 지극히 주관적)
- 오래된 데이터 (Plain-Old-Data Type Smell)
- ML 시스템에서 사용하고 생성되는 정보는 float, int와 같은 단순 데이터 타입으로 인코딩
- 모델 매개변수는 이게 log 값인지, 결정 임계값인지를 알 수 있어야 하고 이를 예측한 생성 모델에 대한 정보를 알고 있어야 한다.
- 다국어 (Multiple-Language Smell)
- 특정 시스템을 일부 주어진 언어로 작성하는 것은 일관성 있고 쉽다는 유혹을 발생시킨다 (Python으로만 개발!)
- 하지만 한 개의 언어만 사용하는 경우 테스트 비용이 증가할 수 있으며, 소유권을 쉽게 줄 수 있기 때문에 다양한 언어를 사용하며 개발하는 것이 좋다.
- 프로토타입 (Prototype Smell)
- 프로토타입으로 만들어 새로운 아이디어를 테스트하는 것은 편리하다.
- 하지만 여러 프로토 타입을 만들면서 자체 비용이 늘어나게 되며 급한 경우에는 프로토 타입을 최종 결과물로 사용할 수 있기 때문에 실제 환경에서 사용하면 매우 위험하다.
6. 구성 부채 (Configuration Debt)
- 부채가 발생할 수 있는 여러 영역이 있지만, 예상치 못하게 ML 시스템의 구성에서도 부채가 발생할 수 있다.
- 어떤 특징, 어떤 데이터 선택 방식, 알고리즘별 학습 설정 등 다양한 옵션을 고려해야 할 일이 많아진다.
- 이렇게 다양한 옵션을 고려해보다 보면 서로의 의존성에 대해서 비효율적이 될 수 있으며, 비용이 많이 들 수 있고 시간 손실과 컴퓨팅 자원의 낭비 또는 생산 문제로 이어질 수 있다.
Example : 쇼핑몰 추천 시스템
특징 A (구매 이력) : 9월 14 ~ 17일 동안 로그 시스템의 오류 발생, 사용 X
특징 B (검색 기록) : 10월 7일 이전에는 이 기능 없었음, 새로운 데이터만 사용
특징 C (상품 조회수) : 11월 1일부터 로그 형식 변경, 이전/이후 데이터 처리 방식 달라야 함
특징 D (실시간 재고) : 실제 서비스에서는 직접 사용 불가, 예상 재고나 일일 재고 사용 - 이런 문제를 해결하기 위해 다음과 같은 규칙을 명확하게 해야 한다.
1) 이전 환경 설정에서 작은 변경은 쉽게 변경할 수 있어야 한다.
2) 수동 오류, 누락 또는 간과에 대한 실수가 발생하기 어렵게 만들어야 한다.
3) 두 모델 간의 구성 차이를 시각적으로 쉽게 파악할 수 있어야 한다.
4) 구성에 대한 기본 사실을 쉽게 주장하고 검증할 수 있는 것이 중요하다.
5) 사용되지 않거나 중복된 설정은 쉽게 파악하고 수정할 수 있어야 한다.
6) 구성은 전체 코드 PR을 거쳐야 하며 PR 후 저장소에 체크인이 되어야 한다.
7. 외부 세계의 변화 다루기 (Dealing with Changes in the External World)
- ML은 외부 세계와 직접적으로 상호작용하는데, 외부 세계는 거의 안정적이지 않다는 것이 경험적으로 밝혀짐. 이러한 불안정성은 유지 관리 비용을 발생시킬 수 있다.
7-1) 동적 시스템에서의 고정 임계값 (Fixed Thresholds in Dynamic Systems)
- 모델이 어떠한 행동을 수행하기 위한 의사 결정 임계값을 선택해야 할 필요가 있다.
- 고전적입 접근 방법 중 하나는 특정 메트릭을 활용 (정밀도와 재현율)하여 가능한 임계값 집합에서 임계값을 선택해야 한다.
- 임계값은 수동으로 설정하기 때문에, 많은 임계값을 수동으로 업데이트하는 것은 시간이 많이 걸리고 취약한 문제가 있기 때문에 자동화된 방식을 검토해야 한다.
7-2) 모니터링 및 테스트 (Monitoring and Testing)
- 개별 구성 요소의 단위 테스트와 종단 간 테스트는 유용하지만, 실제 세계에서 적용하기에는 이런 테스트만으로는 다양한 사항을 감지할 수 없다.
- 실시간 모니터링을 통해 자동화된 응답을 결합하는 것이 장기적으로 시스템 신뢰성을 유지하는데에 매우 중요하다. 이를 위해 모니터링 시작점을 만들어야 한다.
- 모니터링 시작점의 구성
1) 예측 편향 (Prediction Bias) : 예측 레이블의 분포와 관측된 레이블의 분포가 같은 경우와 같이 레이블 발생의 평균 값을 예측하는 null 모델에 의해 충족될 수 있으며 이는 프로그램이 의도한 대로 편향을 가지고 작동하는 지를 의미한다.
2) 행동 제한 (Action Limits) : 실제 세계에서 행동을 취하는, 액션을 취하는 시스템은 행동 제한을 설정하고 이를 시행해야 한다. 제한은 정확하게 두면서 동시에 넓은 범위를 포괄해야 하며 이에 대한 한계가 초과되면 자동알림 기능을 사용한다.
3) 상류 생산자 (Up-Stream Producers) : 데이터는 다양한 상류 생산자로부터 전달되는 경우가 많으며, 상류 생산자들은 철저하게 모니터링되고 테스트되어야 한다. 또한 모든 하류의 ML 시스템을 포괄할 수 있어야 하고 뒤의 작업이 잘 진행되는지를 체크해야 한다.Airflow, MLflow와 같은 도구를 사용한다면 프로세스 추적이 가능하다.
8. ML 관련 기술 부채의 다른 영역 (Other Areas of ML-related Debt)
- 기술 부채가 축적될 수 있는 몇 가지 추가 영역을 간략하게 강조
- 데이터 테스트 부채 (Data Testing Debt)
- ML 시스템에서 데이터가 코드 대신 사용 된다면, input 데이터가 올바르게 들어가는 지 확인한다.
- input 데이터의 분포에 따라 모니터링의 난이도가 변화되며 단순성 검사에도 사용될 수 있다.
- 재현 가능성 부채 (Reproducibility Debt)
- 엄격한 재현 가능성을 두고 유사한 결과를 계속 얻는 것은 무작위 알고리즘, 병렬 학습의 비결정론, 초기 조건에 대한 의존, 외부 세계와의 상호작용으로 인한 어려움 발생
- 프로세스 관리 부채 (Process Management Debt)
- 본 논문은 단일 모델을 유지하는 비용에 대해 논의
- 현실 여러 시스템은 수십 또는 수백 개의 모델이 동시에 실행되면서 모델에 대한 많은 구성을 안전하게 자동으로 업데이트, 모델 간의 리소스를 관리하고 할당, 프로덕션 파이프라인에서 데이터 흐름의 병목 현상을 시각화하고 감지하는 방법 등과 같은 중요한 문제가 있다.
- 사고가 났을 때 회복을 지원하는 도구 개발도 중요하며, 많은 수동 단계가 포함된 공통 프로세스는 정말 조심해야 한다.
- 문화적 부채 (Cultural Debt)
- ML 연구와 엔지니어링 사이의 경직된, 애매모호한 경계는 장기적인 시스템 건강에 역효과
- 기능 삭제, 복잡성 감소, 재현 가능성 등을 동일한 정도로 얘기하고 보상하고 수정하는 팀 문화를 만드는 것이 가장 중요하다.
- 두 팀의 이질적인 요소가 많으면 이러한 문화적 부채가 많이 발생
9. Conclusions : Measuring Debt and Paying it Off
결론 : 부채를 잘 측정하고 잘 방지하고, 생긴다면 잘 해결해나가야 한다!!
- 시스템에서 기출 부채를 측정할 방법이나 전체 비용을 평가할 수 있는 엄격한 메트릭을 제공하지 않는다.
- 팀이 빠르게 움직인다는 것이 꼭 낮은 부채나 좋은 관행의 증거가 될 수는 없다.
- 부채 측정에 대한 고려 사항
1) 완전히 새로운 알고리즘 접근 방식은 전체 에서 얼마나 쉽게 테스트 가능한가?
2) 모든 데이터 종속성의 전이는 가능한가?
3) 시스템에 대한 새로운 변경으로 인한 영향을 얼마나 정확하게 측정 가능한가?
4) 하나의 모델 또는 신호 (특징)을 개선한다면 다른 것들이 악화 되는가?
5) 팀의 새로운 멤버가 들어온다면 얼마나 빨리 적응 시킬 수 있는가? - 이 논문을 통해 더 나은 추상화 방법론, 테스트 방법론, 설계 패턴 등 ML 분야에서 유지 가능한 추가 개발 촉진 가능성을 확인
가장 중요한 통찰 : 부채는! 엔지니어와 연구자가 모두 인식해야 한다.
- ML 팀 문화와 변화만으로도 충분히 ML 관련 다양한 부채들을 빠르게 인식하고 갚아나갈 수 있으며, 장기적인 건강에 매우 중요하다!!!!
