
ELMo는 사전학습된 bidirectional language model을 사용하여 구문, 의미적 단어 사용을 고려한 단어 벡터를 생성하는 모델입니다. 후에 다룰 BERT에 많이 참조됩니다.
✔ Introduction
기존의 사전 학습된 word representation은 언어 모델의 핵섬적인 역할을 하였지만 높은 퀄리티의 representation을 표현하기에는 아래 두 가지의 한계가 있었습니다.
-
단어 사용의 복잡한 특성(ex- 구문론, 의미론)
-
문맥 안에서 달라지는 특성들(다의성)
이를 해결하기 위해 본 논문에서는 deep contextualized word representation을 제안하였습니다. ELMo representation이라 불리는 이 벡터는 기존의 LSTM의 top layer 값만 사용하는 것이 아닌, LSTM의 여러 층에서 생성된 벡터들을 선형 결합하여 산출합니다.
상위 레벨 LSTM state들은 문맥에 의존하는 단어의 의미를 잘 파악하였으며, 하위 레벨 state들은 구문에 관련된 작업에 특화되어 있습니다. 때문에 이런 내부 state들을 결합하는 방식은 풍부한 word representation을 만들기에 유리합니다.
여러 실험들을 통해서 ELMo representation의 실제 성능이 좋음을 증명했습니다. 텍스트 함의, 감성 분류, 질의응답 등의 6가지 NLP task에서 기존 모델과 쉽게 결합할 수 있으며, 모든 과제에서 SOTA를 향상시켰습니다. ELMo를 기존 모델인 CoVe와 비교했을 때도 향상된 성능을 보였고, deep representation(여러 층의 벡터들을 선형결합하는 방식)을 사용하는 방법 역시 기존의 LSTM top layer에서만을 사용하는 방법보다 높은 성능을 보였습니다.
✔ ELMo: Embeddings from Language Models
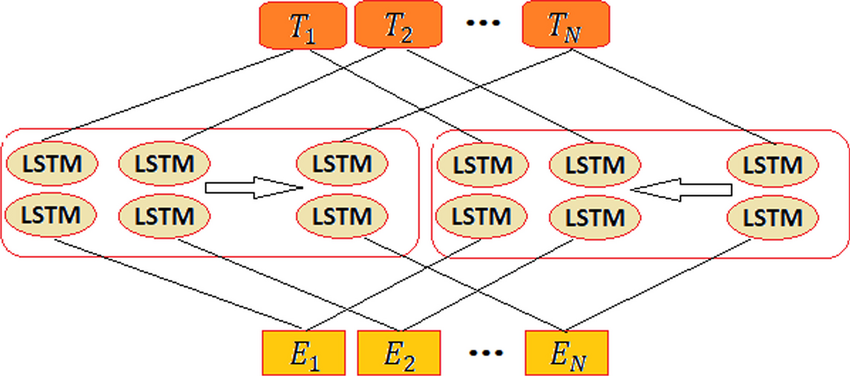
ELMo word representation은 CharCNN(character convolution)과 biLM의 출력 위에서 내부 네트워크 state들의 선형 함수로 계산됩니다. 이러한 구조는 사전학습을 선행한 반지도 학습(semi-supervised learning)을 가능케하며, 기존 NLP 구조에 쉽게 합쳐질 수 있도록 합니다.
✅ Bidirectional langauge models
N 토큰으로 이뤄진 시퀀스 이 있다고 가정했을 때, 전방향 언어 모델(forward language model)은 토큰 에 대해 의 확률을 모델링하여 계산합니다.
기존의 SOTA 신경망 언어 모델들은 문맥 독립적인 representation 를 계산한 다음 전방향 LSTM의 L개 layer를 통과시켰습니다. 각 토큰의 위치 에서 문맥을 반영한 representation 를 얻게 됩니다. top layer에 있는 은 softmax layer에 입력으로 들어가 다음 토큰인 을 예측합니다.
역방향 언어 모델은 전방향 언어 모델과 유사하지만 순서가 뒤에서부터 시작한다는 차이점이 있습니다. 즉, 뒤의 문맥을 보고 전의 토큰을 예측하는 방식이죠.
전방향 언어 모델과 유사하게 representation 이 주어질 때 에 대해 representation 을 구할 수 있습니다.
biLM은 전방향 언어 모델과 역방향 언어 모델 각 로그 우도를 최대화하는 방향으로 병합합니다.
전방향과 역방향에서 토큰 representation 와 softmax 층 는 공유하지만 LSTM 파라미터 자체는 각 방향에서 분리하여 관리합니다.
✅ ELMo
ELMo는 biLM의 layer representation의 결합입니다.
각 토큰 에 대해 L-layer biLM은 2L + 1개의 representation을 계산합니다.
여기서 는 토큰 임베딩 레이어이고 는 biLSTM의 각 레이어들입니다. 다운스트림 모델에 적용하기 위해 ELMo는 의 모든 레이어를 하나의 단일 벡터로 합칩니다.
가장 간단한 버전은 top layer를 선택하는 이겠지만, 일반적으로는 모든 biLM의 층들에 학습된 가중치를 부여하여 task-specific한 representation을 도출합니다.
는 softmax로 정규화된 가중치들이며, 스칼라 파라미터 는 task 모델이 전체 ELMo 벡터를 조정할 수 있도록 합니다. (task별 최적화에 핵심적 역할)
경우에 따라 각 biLM 층들에 layer normalization을 하는 것도 도움이 됩니다.
✅ Using biLMs for supervised NLP tasks
사전 학습된 biLM과 지도학습 방식의 NLP task가 주어졌을때, 다음과 같은 과정으로 biLM을 NLP task 향상에 사용합니다.
biLM을 통해 나온 각 단어에 대한 모든 층의 representation을 만들고, task model에 선형 결합한 결과물을 학습하게 하면 됩니다.
supervised 모델의 가장 아래 레이어는 대부분 같습니다. 때문에 ELMo를 결합해도 다른 레이어를 변형하지 않기 때문에 여러 supervised 모델에 적용할 수 있습니다.
supervised 모델은 토큰 시퀀스 이 주어졌을 때 토큰 위치 에 대해 사전 학습된 단어 임베딩과 문자 기반 representation을 사용하여 문맥과 무관한 토큰 표현 를 만드는 것이 일반적입니다. 그후, 양방향 RNN, CNN 등을 사용하여 문맥에 민감한 representation 를 생성하죠.
ELMo를 supervised model에 추가하기 위해서는 biLM의 가중치를 고정(freeze)하고 ELMo 벡터 를 와 연결(concatenate)한 후, representation 를 task RNN에 연결합니다. 추가적으로 몇몇 task들에 대해서 를 로 대체하는 것도 성능이 향상되는 것도 확인할 수 있습니다.
마지막으로 ELMo 벡터에 적절한 드롭아웃을 추가하는 것이 도움이 될 수 있고, ELMo 가중치 에 정규화 항 를 손실함수에 추가하는 것 역시 도움이 되었습니다.
✅ Pre-trained bidirectional language model architecture
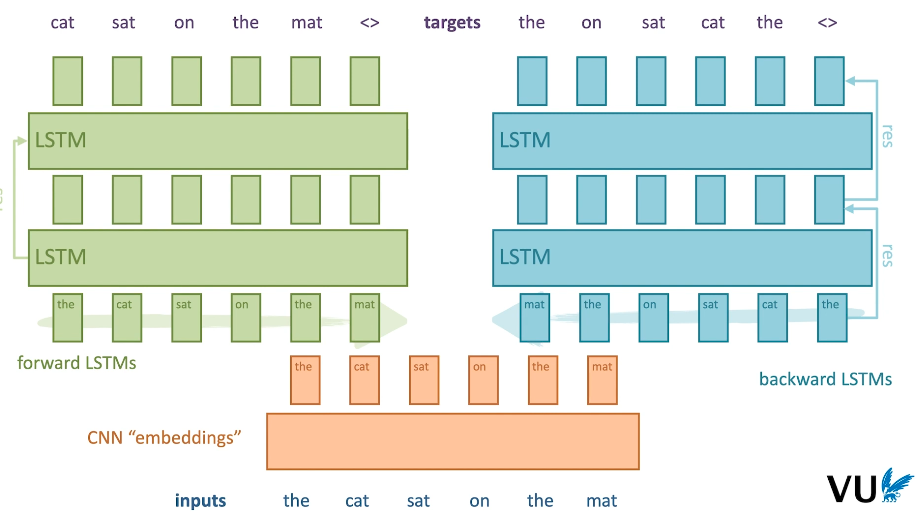
-
입력 임베딩(Char CNN)
입력 토큰은 문자 단위로 처리되어 OOV 문제를 방지하고, CharCNN을 통해 임베딩됩니다.- CharCNN
- 2048개의 n-gram 필터
- 2개의 Highway Layer -> 512 차원으로 linear projection
- CharCNN
-
biLM
- 2개의 biLSTM
- 각 LSTM은 4096개의 hidden unit을 가지고 있음
- 이후 출력을 512차원으로 projection
- 첫번째 레이어와 두번째 레이어 사이 residual connection 사용
=> 토큰 하나 당 CharCNN, biLSTM 두 개 해서 총 세 개의 representation으로 표현됩니다.
이후 ELMo representation 식으로 하나의 representation으로 통합됩니다.
1B Word Benchmark 데이터로 10 에폭으로 학습한 결과 전방향, 역방향 평균 perplexity는 39.7로 전방향 CNN-BIG-LSTM 모델에 비해 다소 높았습니다.
biLm이 사전 학습된 이후에는 대부분의 task에서도 representation을 계산할 수 있었으며, 도메인 특화 데이터로 파인튜닝하는 경우 perplexity가 크게 감소하고 성능이 향상되었습니다. 해당 이유로 논문에서는 downstream task에 파인튜닝된 biLM을 사용하였습니다.
✔ Evaluation
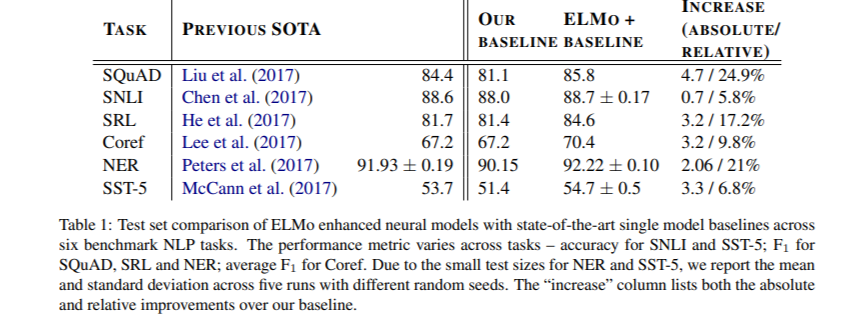
전체적으로 6개의 벤치마크에서 ELMo를 추가하는 것만으로 SOTA(state-of-the-art)를 달성한 것을 볼 수 있습니다.
-
Qustion answering
-
SQuAD(The Stanford Question Answering Dataset) 사용
-
Baseline(Clark and Gardner, 2017)
- Bidirectional Attention Flow model의 향상된 버전
- self-attetion 층을 Bidirectional attention components 이후에 추가.
- 일부 pooling 연산 단순화, LSTM 대신 GRU 사용
-
4.7 향상(85.8), relative error reduction은 24.9%
-
기존 SOTA보다 1.4 높음
-
ELMo를 포함한 11개 모델 앙상블 시 F1 Score가 87.4까지 상승
-
-
Textual entailment
-
전제가 있을 때 가설이 참인지 판단하는 태스크
-
SNLI(The Stanford Natural Language Inference) 사용
-
Baseline(Chen et al., 2017)
- ESIM 시퀀스 모델
- biLSTM을 전제와 가설 인코딩에 사용
- matrix attention layer, local inference layer, 다른 biLSTM 기반 추론 구성 레이어, pooling 연산으로 출력층 거침
-
0.7 향상(88.7), relative error reduction은 5.8%
-
기존 SOTA보다 0.1 높음
-
11개 모델 앙상블 시 overall accuracy 89.3%까지 상승
-
-
Semantic role labeling
-
'who did what to whom'에 답하는 문제
-
SRL(A semantic role labeling) 사용
-
Baseline(Zhou and Xu(2015))
- 전방향과 역방향을 교차시키는(interleaved) 8중 biLSTM 사용
-
3.2 향상(84.6), relative error reduction은 17.2%'
-
기존 SOTA보다 2.9 높음
-
-
Coreference resolution
-
텍스트 내에서 동일한 실제 대상을 지칭하는 여러 언급들을 군집화하는 태스크
-
Baseline(Lee et al. (2017))
- end-toend span-based neural model
- biLSTM과 attention 메커니즘 사용, span representation 계산 후 softmax 기반의 mention ranking 모델 적용함
-
3.2 향상(70.4), relative error reduction은 9.8%
-
기존 SOTA보다 3.2 높음
-
-
Named entity extraction
-
뉴스 기사에서 사람, 장소, 조직, 기타 고유명사를 인식하는 태스크
-
Baseline (Peters et al. (2017))
- pre-trained word embeddings + character-level CNN
- 2-layer biLSTM + CRF (Conditional Random Field) loss 사용
-
2.06 향상(92.22), relative error reduction은 21%
-
기존 SOTA보다 0.29 높음
-
이전 SOTA 모델(Peters et al. 2017)은 biLM의 마지막 층만 사용,
ELMo 모델은 모든 biLM 층의 weighted average 사용 → 성능 향상
-
-
Sentiment Analysis
-
영화 리뷰 문장에서 문장의 감정적 경향을 5단계(매우 부정적~매우 긍정적) 중 하나로 분류하는 태스크
-
Stanford Sentiment Treebank (SST-5) 사용
-
Baseline (Socher et al., 2013)
- 다양한 모델이 존재하지만, ELMo 논문에서는 간단한 biLSTM 기반 문장 분류기에 적용
-
3.3 향상(54.7), relative error reduction은 6.8%
-
기존 SOTA보다 1 높음
-
✔ Analysis
해당 섹션에서는 ablation analysis를 통해 모델의 성능을 검증하고 분석하는 것을 중점적으로 다룹니다. 또한 ELMo가 task 모델의 어느 위치에 들어가면 좋을지, 훈련 데이터 크기 설정이나 task 별 가중치를 학습한 ELMo 시각화 등도 포함되어 있습니다.
✅ Alternate layer weighting schemes
biLM 층들을 결합하는 방식은 해당 식말고도 여러 가지가 있습니다. 기존의 연구들은 top layer만 쓰는 것이 일반적이었습니다. 정규화 파라미터 역시 중요한데, 과 같이 큰 값을 사용하면 가중치 함수가 각 층의 평균처럼 동작하며 처럼 작은 값을 쓰면 각 층 별 가중치를 더 잘 조정할 수 있게 됩니다.
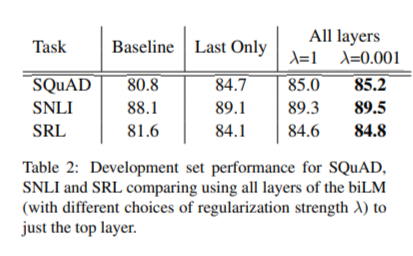
Table 2를 보면, SQuAD, SNLI, SRL 별 top layer만 포함한 경우와 모든 layer를 계산한 경우를 비교하고 있습니다.
결과를 보면 알 수 있듯, top layer만 포함한 경우도 기존 Baseline 모델보다는 점수가 높지만, 모든 layer를 계산할 때가 값과 별개로 높은 점수를 내는 것을 알 수 있습니다.
또한, 정규화 파라미터 가 1인 경우와 0.001를 비교했을 때 대부분의 경우에서 값이 작을 때가 더 좋은 성능을 보였습니다. 다만 NER task의 경우 학습 데이터가 적어 에 민감하지 않았습니다.
이런 경향은 CoVe를 사용할 때도 유사하게 나타났지만 성능 향상 폭은 더 작았습니다. 가 1일 경우와 top layer만 쓰는 경우를 비교했을 때, SNLI에서는 0.5%p, SRL에서는 0.1%p 상승했습니다.
✅ Where to include ELMo?
논문에 사용된 task architecture는 단어 임베딩을 biRNN 가장 아래 층에 입력으로만 사용합니다. 하지만 ELMo를 biRNN의 출력층에 포함시키는 것 역시 일부 task에서 향상을 보이는 것을 발견하였습니다.
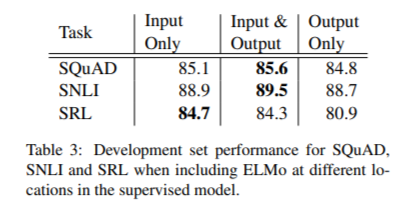
Table 3을 보면, SNLI와 SQuAD에서는 입력층과 출력층 모두에 ELMo를 부착하는 것이 입력층에만 부착하는 것보다 높은 성능을 보였습니다. 하지만 SRL에서는 입력층에만 부착하는 것이 가장 높은 성능을 보였습니다.
이는 SNLI와 SQuAD architecture가 biRNN 후에 attention 층을 사용하기 때문에 ELMo를 해당 레이어에 부착하는 것이 모델로 하여금 biLM의 내부 representation에 더 주의를 기울일 수 있게 하는 것입니다.
✅ What information is captured by the biLM's representations?

ELMo 추가 시 성능이 향상되므로 biLM의 contextual representation에는 기존 단어 벡터보다 더 많은 정보를 담고 있음이 분명합니다.
Table 4에는 'play'란 단어를 기준으로 GloVe에서의 의미와 biLM에서의 의미를 비교하고 있습니다. GloVe에서는 파생표현(-ing나 명사 등등)도 존재하지만 기준 의미가 스포츠의 'play'인 반면, biLM에서는 문장에서의 'play'의 품사와 의미 모두 판별할 수 있음을 보여줍니다.
논문에서는 자세한 평가를 위해 해당 representaion을 WSD(word sense disambiguation) task와 POS tagging task에 활용했습니다.
WSD
biLM representation을 사용하여 문장이 주어졌을 때 1-최근적 이웃(1-nearest neighbor approach)을 사용하여 타겟 단어의 의미를 예측하고자 했습니다.
이를 위해 학습 코퍼스인 SemCor 3.0의 모든 단어들을 biLM을 통해 representation을 계산하고, 각 의미별로 평균 representation을 산출합니다.
테스트 과정에서는 타겟 단어를 biLM으로 representaion으로 변환한 후, 최근적 이웃 기법을 통해 가장 가까운 의미를 고릅니다. 훈련 데이터에 없는 경우에는 WordNet의 기본의미로 fallback됩니다.
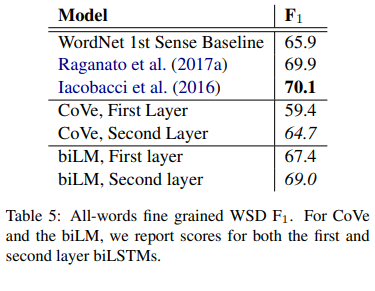
Table 5는 Raganato et al. (2017b)에서 제시한 평가 지표를 적용하여 biLM의 결과를 비교한 표입니다. 테스트 데이터는 논문에 나온 네 개의 데이터셋을 그대로 사용했고 biLM의 top layer의 값은 69.0의 F1-score 값으로 biLM의 첫 번째 레이어보다 뛰어난 성능을 보였습니다.
해당 결과는 hand-crafted features를 기반으로 한 SOTA 모델(Iacobacci et al., 2016)이나 의미 태그, 품사 정보들을 추가로 학습한 biLSTM(Raganato et al., 2017)와 비교해도 견줄만한 결과입니다.
CoVe의 경우에는 biLM과 같이 두 번째 레이어이 첫 번째 레이어보다 결과는 좋았으나, 전반적인 성능 자체는 baseline 모델보다 떨어졌습니다.
POS tagging
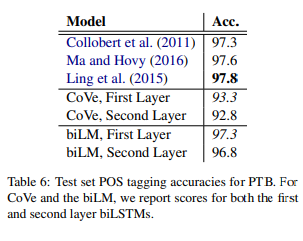
biLM이 기초 구문을 파악하는지 확인하기 위해 context representation을 POS tag 예측을 위한 선형 분류기(linear classifier)에 입력으로 사용하였습니다. 사용된 코퍼스는 Penn Treebank(PTB)입니다.
선형 분류기는 모델 용량에 작은 부분만을 차지하기 때문에 biLM의 representation의 성능을 직접적으로 실험하는 것과 다를 바 없습니다. WSD와 유사하게 biLM representation은 별도로 튜닝된 task specific한 biLSTM과 견줄만한 결과를 산출하였습니다. 하지만 WSD의 결과와는 달리 biLM의 첫 번째 레이어가 top layer보다 높은 정확도를 기록했습니다. 이는 다른 모델들에서도 비슷한 패턴을 보입니다.
CoVe 역시 biLM과 비슷하지만 성능은 biLM이 더 높았습니다.
Implications for supervised tasks
해당 실험들은 biLM의 층별로 다른 종류의 정보를 담고 있는 것을 시사하며, 모든 biLM을 포함하는 것이 높은 성능에 중요한지 설명합니다. 또한 biLM의 representation이 CoVe보다 WSD와 POS tagging task에서 우위를 보임을 통해 ELMo가 CoVe보다 downstream task에서 더 좋은 결과를 보이는지 설명이 가능합니다.
✅ Sample efficiency
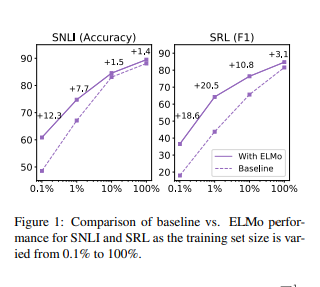
ELMo를 모델에 추가할 시, SOTA 성능에 도달하기까지의 파라미터 업데이트나 전체 학습 데이터 양 측면에서 효율성이 크게 증가합니다. 일례로 SRL 모델의 경우, ELMo 없이 할 때는 486 에폭을 거친 후에야 최대 F1 score에 도달하였지만, ELMo를 사용한 경우에는 10 에폭만에 베이스라인 성능을 뛰어넘었습니다.
또한, ELMo를 부착한 모델은 적은 훈련 데이터셋으로도 효율적으로 사용할 수 있습니다. Figure 1을 살펴보면 ELMo를 사용했을 때 성능 향상이 데이터셋이 적을 때 가장 크게 나타났고, 데이터의 양이 늘어날 수록 그 효과가 점점 적어졌습니다. 예시로 SRL의 경우, ELMo에서 1%의 훈련 데이터로 얻은 F1-score가 baseline 모델에서는 10%의 훈련 데이터를 사용한 결과와 같습니다.
✅ Visualization of learned weights
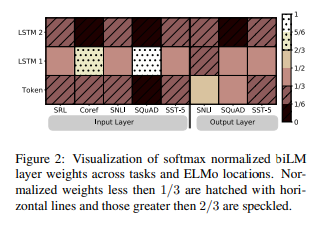
Figure 2는 softmax 정규화로 학습된 층별 레이어의 가중치입니다. 입력 레이어에서는 biLSTM의 첫 번째 층을 선호하는 경향이 나타납니다. Coref와 SQuAD에서는 그런 경향이 많이 나타나지만 다른 task에서는 뚜렷하지는 않습니다.
출력 레이어에서는 균형 잡혀 있으며, 하위 레이어들에 대한 선호가 있습니다.
