[NLP Paper Review] Effective Approaches to Attention-based neural Machine Translation
NLP Paper Review

해당 논문은 기존에 NMT(neural machine translation)에 사용되던 attention mechanism을 효율적으로 사용하기 위한 방법을 제시합니다.
- global approach
: 소스 내 모든 단어를 참조한 attention 방식 - local approach
: 소스 내 특정 하위집합만을 참조하는 방식
위와 같은 방식으로 attention을 사용하지 않는 경우보다 BLEU 포인트가 5.0 더 높게 나왔고, 여러 attention mechanism을 섞은 앙상블 모델 역시 WMT'15 English to German 데이터에서 SOTA를 달성하였습니다.
✔ NMT & Attention mechanism
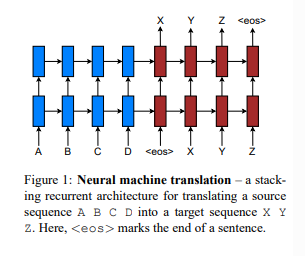
NMT는 end-to-end로 구성된 거대한 신경망입니다. 입력 문장 을 타겟 문장 로 번역하는 과정에서 조건부 확률 을 계산하는 방식으로 이뤄집니다.
NMT 구조는 encoder와 decoder 두 가지로 이뤄져 있는데, encoder는 각 입력 문장 별로 representation 를 계산하고, decoder는 해당 representation을 기반으로 타겟 단어를 하나씩 생성합니다. 이를 위해 decoder는 전체 문장의 조건부 확률를 다음과 같이 분해(decomposition)합니다.
해당 식은 주로 RNN 구조에서 사용되며 대부분의 NMT 연구들이 decoder로 RNN 구조를 사용하고 있습니다.
또한, 각 단어 를 디코딩할 확률은 다음과 같이 파라미터화됩니다.
는 vocabulary 크기만큼의 벡터를 출력하는 변환 함수이고, 는 RNN의 hidden unit입니다. 는 다음과 같이 계산됩니다.
는 이전 time step의 hidden state를 기반으로 현재 시점의 hidden state를 계산하는 역할을 합니다. 기본 RNN, GRU, LSTM 등이 이에 해당됩니다.
는 source representation으로, 이전의 연구에서는 를 decoder의 hidden state를 초기화할 때 한 번만 사용했습니다. 하지만, 본 연구에서 는 소스 문장의 모든 hidden state의 집합을 의미하며 번역 과정 전반에서 지속적으로 참조됩니다.
이런 방식을 attention mechanism이라 합니다.
연구에서는 NMT 시스템으로 Figure 1과 같이 stacking LSTM 구조를 채택하였습니다. 손실 함수는 다음과 같습니다.
는 학습 코퍼스입니다.
✔ Attention-based Models
attention model은 크게 global과 local 두 가지로 나뉩니다. 이 둘의 차이는 attention을 전체 소스에 배치할 지 아니면 몇몇 개의 소스에만 배치할 지에 따라 달라집니다.
global과 local의 공통점은 디코딩 단계의 time step 마다, stacking LSTM의 top layer hidden state 를 입력으로 사용한다는 것입니다. 이를 통해 현재 타겟 단어 를 예측하는데 도움이 될 context vector 를 얻는 것을 목표로 합니다. 모델에 따라 를 얻는 방식은 다르지만, 이후 처리하는 방식은 동일합니다.
타깃 hidden state 와 context vector 가 주어졌을 때, 이 둘을 연결(concat)하여 attentional hidden state를 다음과 같이 생성합니다.
이후, attentional hidden state 는 softmax 층을 거쳐 예측 분포(predictive distribution)을 생성하는데 사용됩니다. 예측 분포 수식은 다음과 같습니다.
정리하면 다음과 같습니다.
-
t 시점의 hidden state 을 입력으로 context vector 를 얻음
- 는 타겟 단어 를 예측하기 위한 소스 정보
- 를 얻는 방식은 모델 종류마다 다름
-
와 를 concatenation 층에 통과하여 도출
-
를 softmax 층에 통과하여 예측 분포 획득
이제 모델 별로 어떻게 를 얻는 지 살펴보겠습니다.
✅ Global Attention
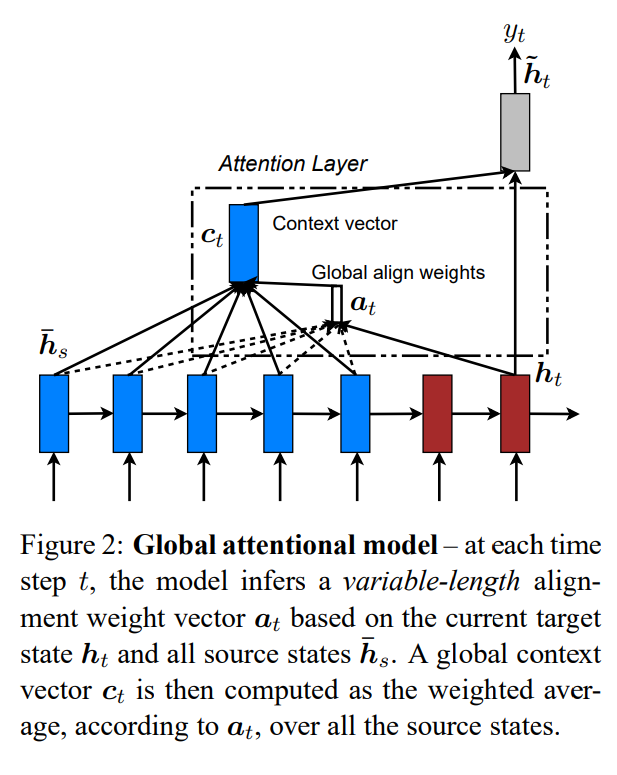
global attention은 context vector 를 얻기 위해 encoder의 모든 hidden state를 반영하는 방식의 모델입니다. 소스 문장의 time step 수와 같은 길이의 가변 길이 정렬 벡터 를 생성하며, 현재 타겟 hidden state 와 각 소스의 hidden state 을 비교하여 도출됩니다.
와 를 비교하여 score를 매기고 softmax를 통해 어텐션 가중치 를 계산합니다.
- time step 별로 소스 문장의 길이가 달라지기 때문에 가변 길이 벡터 사용
- 각 는 softmax를 통해 확률 분포로 정규화
score 함수의 경우 content-based 함수라고도 불리며 논문에서는 세 가지 정도를 제시합니다.
-
Dot(내적)
:
-
General(내적 후 가중치곱)
:
-
Concat
:
-
Location(초창기 사용)
정렬 벡터 를 가중치로 사용하여 context vector 는 모든 소스 hidden state들의 가중 평균(weighted average)로 계산됩니다.
Bahdanau Attention과 유사해보이지만, 몇 가지 차이점이 존재합니다.
-
LSTM top layer의 hidden state만 사용
- Bahdanau
- 양방향 encoder의 소스 hidden state의 결합(concatenation)
- 단방향 decoder의 타겟 hidden state
- Bahdanau
-
계산이 더 간단함.
-
global attention
-
Bahdanau
- deep-output 층과 maxout 층을 거쳐야함.
-
-
alignment function이 다양함
- Bahdanau는 concat밖에 없음
✅ Local Attention
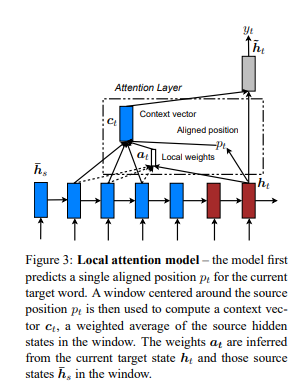
global attetnion은 소스 전체의 hidden state를 고려하기 때문에 비용이 크고, 크기가 큰 문서들을 번역할 때는 적합하지 않습니다. 이를 해결하기 위해 타겟 단어 당 소스의 일부(subset)만 참조하는 local attention이 등장하게 되었습니다.
local attention은 t 시점의 타겟 단어 별로 aligned position(타겟 단어가 주로 참조하는 소스 단어의 위치)인 를 생성합니다. context vector인 는 사이의 소스 hidden state의 가중 평균으로 계산됩니다. 는 정해진 상수입니다. 때문에 global attention과 다르게 alignment vector 는 고정된 차원을 가지고 있습니다.
를 정하는 방법은 두 가지가 있습니다.
-
Monotonic alignment(local-m)
: 소스 시퀀스와 타겟 시퀀스가 순차적으로 정렬되어 있다고 상정=> 로 설정
=>
-
Predictive alignment(local-p)
: 다음 식에 따라 aligned position 를 예측합니다. (동적으로 계산)와 는 position을 예측하는 과정에서 학습하는 모델 파라미터들이고, 는 소스 문장의 길이입니다. sigmoid 함수 결과 이 됩니다.
근처 aligned position에 가중치를 주기 위해 를 중심으로 하는 가우시안 분포(Gaussian distribution)을 설정하였습니다.
align function은 위와 같습니다. 표준편차 는 로 하였으며, 는 실수인 반면, 는 를 중심으로 한 윈도우 내 정수입니다.
- 정렬 가중치 align function을 절단된(truncated) 가우시안 분포로 수정. 또한 와 에 대해 역전파 수행 가능, 거의 모든 부분에서 미분 가능
✅ Input-feeding Approach
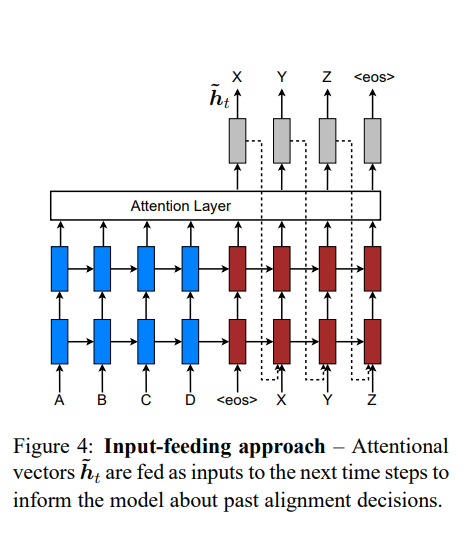
global과 local을 쓰는 것은 각 time step마다 attentional decision이 독립적으로 이뤄집니다. 이는 일관성이 떨어지는 최적이 아닌 방식이죠.
기존의 MT에서는 coverage set을 만들어서 어떤 소스 단어가 번역되었는지 추적하였습니다. 이와 마찬가지로 attention 기반 NMT에서도 과거의 alignment information을 다음 입력에 반영할 필요가 있습니다.
때문에 논문에서는 input-feeding approach를 제시하였습니다. 이는 Figure 4에 나온 것처럼 attentional vector 를 다음 step의 입력값과 결합(concat)하는 방식으로 이뤄집니다. 즉, 이전 attentional vector를 다음 입력에 함께 넣어줘 이전 번역을 참조하게 하는 것입니다. 이를 통해 얻을 수 있는 효과는 크게 두 가지입니다.
- 이전 alignment choice에 대해 온전히 알 수 있다.
- 수평, 수직적으로 깊은 네트워크 구조를 가진다.
✔ Experiments
논문은 WMT translation(English -> German)을 통해 모델 성능을 평가하였습니다.
-
newstest2013 -> 하이퍼파라미터 조정용
-
newstest2014, newstest2015 -> 번역 성능 평가
-
평가 기준: 대소문자 구분 BLEU 점수(case-sensitive BLEU)
- Tokenized BLEU: 토크나이징한 후 점수 계산, 기존 NMT 연구와 비교를 위해 사용
- NIST BLEU: WMT 결과 비교를 위해 사용.
✅ Training Details
-
WMT'14 training data 사용. (116M English words, 110M German words)
-
vocab을 각 언어 당 빈도수 상위 50k로 제한, vocab에 없는 단어는
<unk>처리 -
NMT 학습 시 50 단어 이상의 문장은 필터링함
-
모델 정보
- 4 layer의 stacking LSTM
- 각각 1000개의 cell, 1000 차원 임베딩
-
SGD 사용 10 에폭 학습
-
learning rate
- 1에서 시작하여 5 에폭이 지나면 매 에폭마다 반감함
-
mini-batch 크기는 128
-
normalized gradient는 norm이 5를 초과 시 재조정
-
LSTM dropout 비율은 0.2
-
dropout model => 12 에폭 학습, learning rate는 8 에폭 이후부터 반감
-
local attention 시 는 10으로 설정
✅ English-German Results
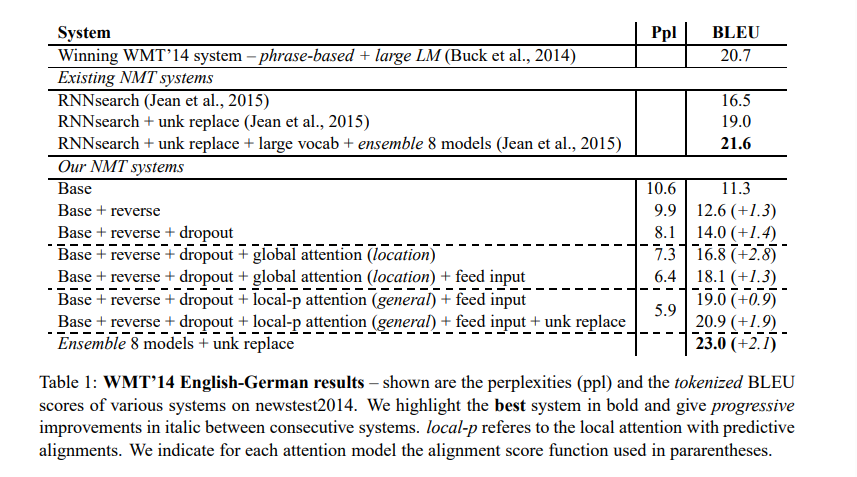
-
reverse: 소스 문장을 역순으로 입력
-
dropout이랑 global 사용 시 +2.8 BLEU로 Bahdanau attention 뛰어넘음
-
local-p를 사용할 때가 성능이 가장 좋게 나왔음
-
결과적으로 non-attention 구조보다 attention 구조를 사용했을 때가 5.0 BLEU 정도 더 높게 나옴
-
8개 모델 앙상블한 결과 23.0 BLEU로 SOTA(State Of The Art) 달성

- WMT'15 데이터에서도 SOTA 달성
✅ German-English Results
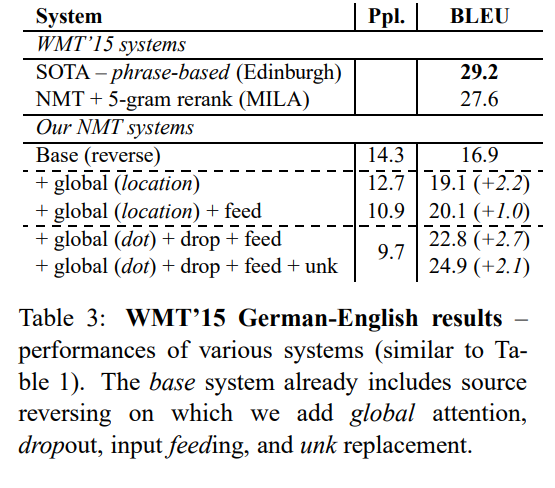
- SOTA 달성 실패
- 하지만 기존의 방식보다 global attention 사용으로 BLEU 점수 향상
✔ Analysis
✅ Learning curves
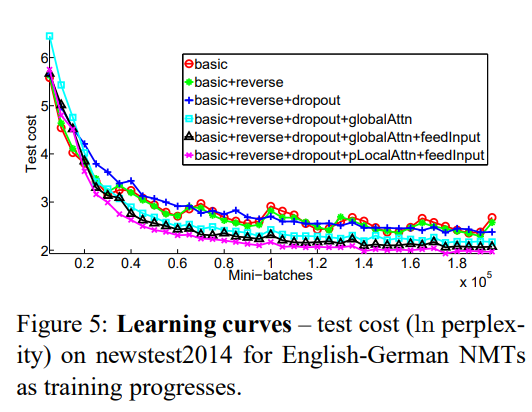
Figure 5는 Table 1의 모델 별로 learning curve를 도식화한 것입니다. attention이 있는 모델과 없는 모델 사이의 차이가 극명하게 드러납니다. 또한, local attention과 input feeding 기법이 성능 향상에 도움을 주고 있음을 알 수 있습니다.
✅ Effects of Translating Long Sentences
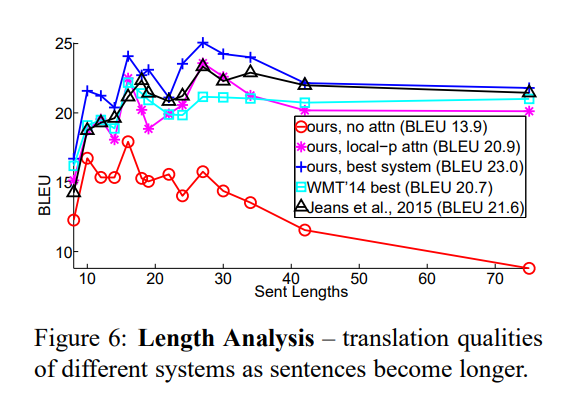
Figure 6는 비슷한 길이의 문장끼리 묶고 BLEU score를 비교한 그래프입니다. attention을 사용한 모델이 긴 문장에서 사용하지 않은 모델보다 좋은 겨로가를 나타내고 있는 것을 확인할 수 있습니다.
✅ Choices of Attentional Architectures
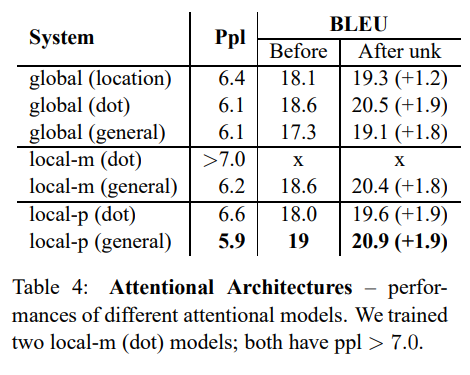
attention 구조 구성은 attention 모델(global, local-m, local-p)과 alignment function(location, dot, general, concat)들의 조합으로 이루어질 수 있습니다.
Table 4는 가능한 조합들의 perplexity와 BLEU score를 정리해놓은 것입니다. location 기반의 모델은 초창기 모델이기에 확실히 다른 alignment function보다는 성능이 떨어지는 걸 확인할 수 있습니다.
concat 함수의 경우 구현은 했으나 성능이 좋지 않아 더 많은 분석이 필요할 것으로 사료됩니다.
- concat의 경우 (Ppl)
- 6.7 (global)
- 7.1 (local-m)
- 7.1 (local-p)
또한, global 모델의 경우 dot 함수를 사용하는 것이 성능이 더 좋았고, local의 경우에는 general이 더 적합했습니다.
✅ Alignment Quality
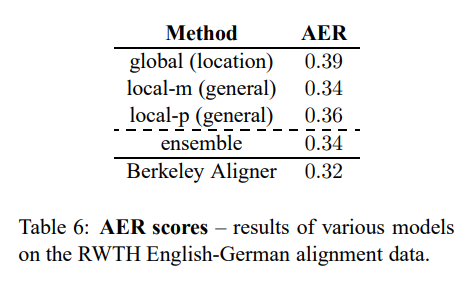
attention model에서 얻을 수 있는 건 word alignment(단어 정렬)입니다. 논문에서는 정렬 결과를 평가하기 위해 the alignment error rate(AER)를 지표로 평가하였습니다.
RWTH에서 제공한 508개 영어-독일어 Europarl 문장의 정답 정렬 데이터를 기반으로 attention model이 이를 그대로 생성하도록 강제 디코딩(force decode)를 수행했습니다. 그 후 각 타겟 단어에 대해 정렬 가중치가 가장 높은 단어 하나만을 선택하게 하여 일대일 정렬만 추출하였습니다.
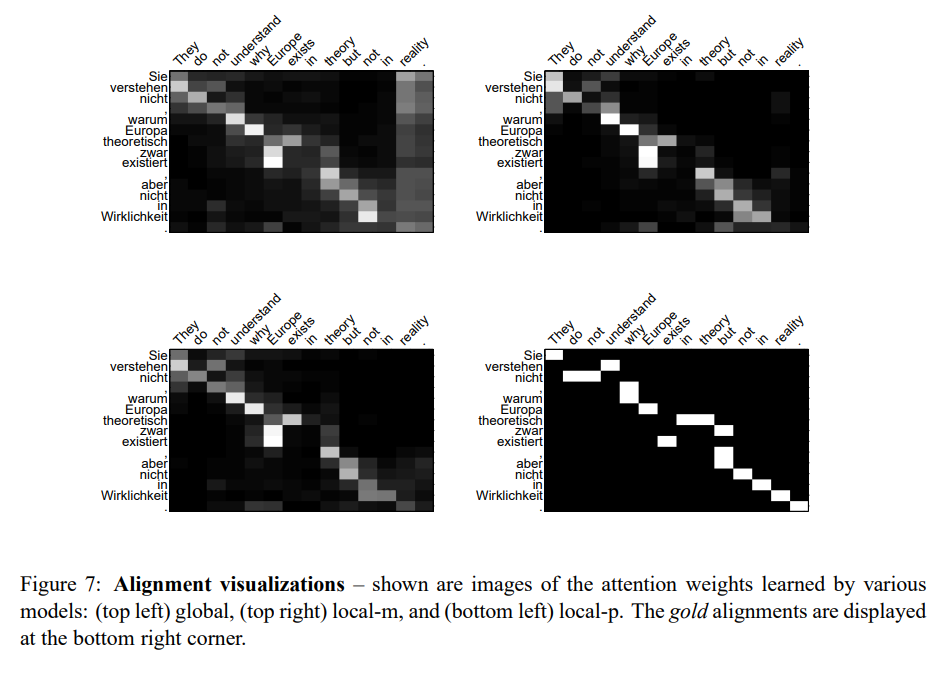
결과는 Table 6에서 볼 수 있듯, 일대다 정렬을 한 Berkely Aligner와 유사한 점수를 얻을 수 있었습니다. local model을 사용한 결과가 global을 사용한 결과보다 좋지 못했으며, 앙상블 모델 역시 local-m보다는 좋지 못했습니다. 이는 AER 결과와 BLEU 결과가 반드시 일치하지는 않는다는 점을 시사합니다. 다음은 일부 예시의 정렬을 시각화한 결과입니다.
✅ Sample Translations

다음은 영어-독일어 문장 샘플을 번역한 결과입니다.
-
attention model이 'Roger Dow'나 'Miranda Kerr' 같은 이름을 정확히 번역했음
- non-attention model은 적합한 이름을 생성하긴 했지만 소스와의 직접적인 연결성이 부족하여 정확하지는 않았음
-
non-attention model과 달리 이중 부정 구문을 정확하게 번역
-
길이가 긴 문장 역시 훨씬 더 정확하게 번역
