
SentencePiece는 Subword tokenizer의 일환으로 raw data에서 subword 모델링을 진행할 수 있다는 점에서 장점을 가집니다. 이러한 점은 SentencePiece가 end-to-end 및 언어 독립적인 시스템을 구축할 수 있게 해줍니다.
✔ Introduction
딥러닝이 발전하며 NMT(Meural machine translation)에 대한 관심이 증가하였습니다. NMT는 end-to-end 구조에 입각한 번역이 가능했지만, 여전히 많은 NMT 시스템들은 언어의존적이고 전/후처리 프로세서들을 사용하는 경우가 많았습니다.
이런 전/후처리 프로세서들은 손수 제작되고, 언어에 의존한 규칙을 기반으로 하였기에, 특성이 다른 언어를 학습하기 위해선 프로세서를 새로 만들어야 했습니다.
예를 들어, 공백 문자를 기준으로 단어가 구분되는 유럽권 언어들과 달리 한국어, 중국어, 일본어의 경우에는 프로세서가 별도로 필요한 상황이었습니다. 이러한 문제는 특히 다중언어 NMT 모델 학습에 어려움을 불러일으켰습니다.
본고에서 다루는 SentencePiece는 단어 사전 크기가 사전에 결정된 NLP 작업에 주로 쓰이는 언어 독립적인 text tokenizer와 detokenizer를 제공합니다. SentencePiece는 두 개의 subword segmentation 알고리즘으로 이루어져 있는데, BPE와 Unigram langauge model가 이에 해당합니다. 해당 알고리즘들을 기반으로 SentencePiece는 어떤 언어에도 편향되어 있지 않은 순수 end-to-end 시스템을 구축할 수 있게 되었습니다.
✔ System Overview
SentencePiece는 네 개의 구성품으로 이루어집니다.
-
Normalizer: semantically equivalent한 유니코드를 정규형식으로 바꿔줍니다.
-
Trainer: subword segmentation model을 normalized한 코퍼스로부터 학습시킵니다. 이때, 사용하는 subword model의 종류를 파라미터로 넘겨줍니다.
-
Encoder: 입력 텍스트를 Normalizer로 정규화하고, Trainer로 subword sequence로 바꿉니다.
-
Decoder: subword sequence를 정규화된 텍스트로 바꿉니다.

그림 1은 SentencePiece의 훈련 과정인 (spm_train), 인코딩 과정인 (spm_encode), 디코딩 과정인 (spm_decode)가 end-to-end로 이루어지는 모습을 보여줍니다. 또한 입력 텍스트는 spm_encode와 spm_decode를 거쳐 상호 전환(reversibly convertible)이 가능합니다.
✔ Library Design
📌 Lossless Tokenization
다음의 예시는 언어 의존적 전처리의 예시입니다.
- Raw text: Hello world.
- Tokenized: [Hello] [world] [.]
위의 토큰화된 시퀀스에서는 상호 전환을 할 수 없습니다.
raw text에서 "world"와 "." 사이에 공백 문자는 없었지만, tokenized된 결과에서는 둘 사이에 공백 문자가 있기 떄문입니다.
이처럼 토큰화된 시퀀스를 raw text로 변환하는 과정인 Detokenization는 언어마다의 특성으로 언어의존적일 수 밖에 없습니다.
- Raw text: [こんにちは世界。] (Helloworld.)
- Tokenized: [こんにちは] [世界] [。]
때문에 일일히 만든 규칙을 기반으로 언어의 특성에 맞는 프로세서를 위와 같이 구축했었습니다.
SentencePiece에서는 Decoder를 Encoder의 역연산을 수행하는 lossless tokenization을 설계했습니다. lossless tokenization은 입력 텍스트를 유니코드 문자의 시퀀스로 간주하여 처리하기 때문에 공백 문자 역시 일반 문자로 간주됩니다.
명확성을 위해 SentencePiece는 공백문자를 '_'(U+2581)로 바꾼 후, 임의의 subword sequence에 넣어 토큰화를 진행했습니다.
- Raw text: Hello_world.
- Tokenized: [Hello] [_wor] [ld] [.]
공백문자를 '_'로 대체함으로써 토큰화 후에도 공백문자의 위치를 표시할 수 있고, 디코드 시 다시 공백문자로 변환할 수 있게 하여 문장의 명확성을 올릴 수 있습니다.
또한 공백이 없음에도 분할이 되어 있는 경우, 그 위치를 '@@'으로 표시합니다.
- Tokenized: [Hello] [wor] [@@ld] [@@.]
📌 Efficient subword trainig and segmentation
기존의 subword segmentation 툴들은 subword model을 사전에 토큰화된 문장들에게서 학습합니다. 하지만 이런 학습법은 non-segmented한 언어들에게 효과적이지 못하고, lossless tokenization에도 악영향을 줄 수 있습니다.
때문에 SentencePiece는 몇 가지 기술들을 사용하였습니다.
예를 들어, 길이 의 입력 문장이 있을 때 BPE segmentation 알고리즘은 의 시간복잡도를 요구합니다. 하지만 SentencePiece는 binary heap을 사용하여 의 시간복잡도 알고리즘을 사용합니다. 또, unigram language model의 학습과 분할 복잡도는 입력 데이터 크기에 선형적으로 비례하도록 합니다.
📌 Vocabulary id management
SentencePiece는 입력 텍스트를 id 시퀀스로 바로 바꾸기 위해 id가 매핑된 단어 사전을 제공합니다.
단어 사전의 크기는 spm_train의 --vocab_size=<size>로 정해집니다. 기존 subword-nmt들이 병합 연산 수를 사전에 정해놓은 반면, SentencePiece는 unigram langauge model같은 여러 segmentation 알고리즘에 적용할 수 있도록 단어사전의 최종 크기를 인자로 넘겨줍니다.
SentencePiece는 메타 기호들(ex. UNK, EOS, BOS, PAD 등)의 id를 따로 설정할 수 있습니다. 메타 기호들의 실제 id는 커멘드 라인 플래그(command-line flag)에서 설정할 수 있습니다. 또한, 커스텀으로 메타 기호들을 정의할 수 있는데, <2ja>와 <2de>와 같은 다국어 모델에서 쓰이는 langauge indicator가 대표적인 예시입니다.
📌 Customizable character normalization
문자 정규화(Character normalization)는 의미적으로 동일한 유니코드 문자들로 이뤄져 있는 실제 텍스트를 다루는데 중요한 역할을 수행합니다. 일본어 전폭 라틴어 문자를 ASCII 라틴어 문자로 정규화하거나 소문자 변환(Lowercasing)이 대표적인 예시 중 하나입니다.
문자 정규화는 수작업으로 세운 규칙에 의해 구현되는 것이 일반적이었으나, 최근에는 NFC나 NFKC같은 유니코드 표준 정규화 방식이 높은 재현도로 인해 널리 쓰이고 있습니다. 이런 정규화 방식 역시 spm-train에서 --normalization_rule_name=nfkc와 같이 설정할 수 있습니다.
💡 유니코드 정규화(Unicode Normalization)
유니코드 정규화는 결합 문자나 한글 자모음 같은 연속적인 코드 포인트로 의미를 표현할 때 동등한 코드 포인트로 인식하게 하여 검색 및 비교가 가능하도록 합니다.
예를 들어 '각'이라는 단어가 있을 때, 이 글자는 '각'으로도 표현될 수 있고, 'ㄱ'과 'ㅏ', 'ㄱ'의 결합으로도 표현될 수 있습니다. 때문에 유니코드 등가성을 위해선 해당 문자열을 분해하거나(decomposition), 결합하여(composition) 정규화를 할 필요가 있습니다.
SentencePiece에서 이루어지는 정규화는 string to string mapping과 leftmost longest matching을 사용하여 구현됩니다. 또한, 정규화 규칙들은 효율적인 정규화를 위해 유한 상태의 트랜스듀서로 컴파일됩니다.

SentencePiece는 TSV 파일을 이용한 커스텀 정규화 규칙들 역시 지원합니다. 위의 그림 2는 TSV 파일의 예시를 보여주고 있습니다. 예시에서는 유니코드 시퀀스 [U+41, U+302, U+300]을 U+1EA6으로 변환하고 있습니다. spm_train의 --normalization_rule_tsv=<file>을 통해서 TSV 파일을 설정할 수 있습니다. 또한, task별로 기본 설정인 NFKC 규칙을 확장하는 형태로 규칙을 정의할 수 있습니다.
📌 Self-contained models
오늘날 많은 연구들이 사전학습된 모델을 사용하지만, (Post, 2018)에 따르면 사전학습에서 형성된 스키마(scheme)에서 발생한 조금의 차이가 BLEU 점수에 큰 영향을 줄 수 있다고 합니다. 또한, Moses toolkit나 NFKC 정규화 역시 어떤 버전과 설정을 따르냐에 따라 다른 결과로 이어지기도 합니다.
때문에, SentencePiece는 순수 self-contained 형태로 디자인된 모델을 가지고 있습니다. 모델 파일은 단어 사전과 분할 파라미터를 가지고 있을뿐만 아니라 사전에 컴파일된 유한 트랜스듀서도 포함합니다. SentencePiece의 결과는 오직 모델 파일에 의해서만 결정되며, 그러므로 높은 재현성을 보장할 수 있습니다.
모델은 구조적인 데이터를 직렬화하는 메커니즘을 가진 binary wire format Protocol buffer에 저장됩니다. 이를 통해 확장성과 더불어 하위호환성을 보장하며 데이터를 직렬화할 수 있습니다.
📌 Library API for on-the-fly processing
텍스트 전처리는 보통 오프라인 프로세싱으로 여기곤 하는데, 오프라인 전처리에는 두 가지의 문제점이 존재한다.
-
독립형 툴들이 유저들이 마주하는 NMT 어플들과 직접적으로 합쳐질 수 없기에, 즉석에서 유저들의 입력을 전처리해주지 못함.
-
오프라인 전처리는 종속절 단계의 데이터 증가와 노이즈 주입을 하는데 한계가 있어 성능 향상에 한계가 있다.
그렇기에, SentencePiece는 오프라인 전처리를 위한 독립적인 커맨드 라인 툴을 제공할 뿐만 아니라 즉각적 처리를 위한 C++, Python, Tensorflow 라이브러리 API를 제공하고 있습니다. 다음 이미지들은 각각 C++, Python, Tensorflow에서의 사용 모습입니다.



그림 6은 unigram language model를 사용해 subword regularization을 진행하는 파이썬 코드를 나타내고 있습니다. 여기서 텍스트인 "New York"은 실행횟수에 따라 다르게 토큰화되는데, 자세한 내용은 Subword Regularizaiton을 봐주시길 바랍니다.

✔ Experiments
📌 Comparison of different preprocessing
논문에서는 Kyoto Free Translation Task(KFTT)에 지정된 영어-일본어 번역을 기준으로 서로 다른 전처리 성능을 비교하였습니다. KFTT의 훈련, 개발, 평가 데이터은 각각 440k, 1166, 1160개의 문장으로 이루어져 있습니다.
단어 모델을 baseline model로 설정하고 SentencePiece(unigram language model)에 pre-tokenization이 적용된 경우/그렇지 않은 경우를 비교하였습니다. pre-tokenization이 적용된 경우는 subword-nmt를 사용한 일반적인 NMT 설정과 근본적으로 같습니다. pre-tokenization이 적용되지 않은 경우는 원본 문장에서 바로 서브워드 모델을 학습시키며 다른 외부적인 소스를 사용하지 않는다는 특징이 있습니다.
pre-tokenization에 사용할 토크나이저로는 영어의 경우 Moses tokenzier, 일본어의 경우 KyTea를 사용하였습니다.
평가 지표로는 case-sensitive BLEU 점수를 사용하였고, 도출된 일본어 문장은 분할되어 있지 않아 KyTea로 분할 후 평가에 반영하였습니다.
💡 case-sensitive BLEU score
: 대소문자를 구분하여 평가하는 BLEU 점수
<-> case-insensitive BLEU score
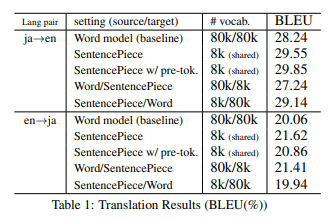
위의 표 1은 실험 결과로 다음과 같은 점을 확인할 수 있습니다.
-
subword segmentation을 적용한 SentencePiece는 baseline 모델과 비교했을 때 꾸준한 향상을 보였습니다.
-
ja->en의 경우 향상이 미미해서 큰 차이가 없었고, en->ja의 경우에는 오히려 BLEU 점수가 낮아졌습니다.(with pre-tokenization)
BLEU 점수가 큰 향상을 보인 건 다음과 같은 경우인데,
-
SentencePiece가 일본어에 적용되었을 때
-
타겟 문장이 일본어일때
일본어는 non-segmented 언어이기에 pre-tokenization이 최종 단어 사전을 결정하는데 큰 장애물로 작용했던 걸로 사료됩니다.
종합했을때, 원본 문장으로부터 이뤄지는 비지도 분할은 특정 도메인의 일본어 단어사전을 찾는데 효과적이다고 판단할 수 있습니다.
📌 Segmentation performance
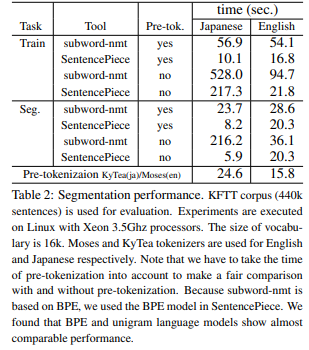
표2는 여러 설정에서의 학습과 분할 성능을 요약하고 있습니다.
영어 데이터의 학습과 분할 과정에서 SentencePiece와 subword-nmt의 속도는 pre-tokenization의 유무와 별개로 비슷했습니다. 이는 영어가 segmented 언어이기도 하고, 단어 사전 추출을 위한 검색 공간이 제한적이었기 때문에 어느 정도 예측된 결과였습니다.
반면, 원본 일본어 데이터를 적용했을 때는 SentencePiece가 높은 성능 향상을 보였습니다.(without pre-tokenization에서) 분할 과정에서의 속도는 subword-nmt보다 380배 정도 빨랐으며, 이는 SentencePiece가 원본 데이터를 바로 처리하는데 충분히 빠른 속도를 보이며 pre-tokenization이 필요하지 않다는 것을 시사합니다.
즉, SentencePiece가 순수 data-driven하고 언어 독립적인 시스템을 구축하는데 도움을 줄 수 있다는 의미로도 해석됩니다. (영어와 일본어 각각 21k sentences, 74k sentences per second로, 즉각적인 처리가 가능한 수준입니다.)
