
해당 논문은 2018년에 나온 것으로 기존 영어 중심의 word representation을 한국어에 특화되도록 자모 기반 subword decomposition 방법론을 제시한 논문입니다.
✔️ Introduction
word vector representation은 의미적, 통사적 지식을 임베딩하기 위해 만들어졌습니다. 기계 번역, 문서 분류 등 여러 downstream task에 사용되었으나 대부분의 word vector 연구는 영어에 기반한 것입니다.
하지만, 다른 언어의 경우 영어와 내부 구조가 달라 해당 word vector를 적용하기 어려움을 보입니다. 특히 한국어와 같이 형태론적으로 풍부한 언어의 경우 n-gram vector와 같이 subword 단위로 분해하는 것이 도움이 될 수는 있지만, 여전히 언어학적 구조를 고려하지는 못하는 모습을 보입니다.
한국어는 자음(consonant)과 모음(vowel)인 자모가 결합하여 음절을 이루는 방식이기에, char 단위 분해보다 자모 단위 분해가 언어적 특성을 살릴 수 있습니다. 그렇기에 논문에서는 char 단위와 자모 단위 분해 후 skip gram 모델에 태워 subword vector를 학습하는 방법론을 제시하였습니다. 추가로 기존 영어 중심의 NLP evaluation dataset을 한국어 버전으로 구축하여 평가를 용이하게 할 수 있도록 하였습니다.
✔️ Model
💡 Decomposition of Korean Words
한국어 음절은 초성(onset), 중성(nucleus), 종성(coda), 세 가지 자모모가 합쳐져 형성됩니다. 초성과 종성은 자음으로 구성되고, 중성은 모음으로 구성됩니다. 각각의 요소들은 어떻게 문자가 발음이 되는지 나타냅니다.

위의 예시에서 '해'의 경우에는 종성이 없고, '달'의 경우는 종성이 존재하는데, 논문에선 일괄적 처리를 위해서 각각 {ㅎ, ㅐ, e}, {ㄷ, ㅏ, ㄹ}로 분해하였습니다. 따라서 N개의 문자로 된 한국어 단어가 있을 때, 자모는 3N개로 생성됩니다. 또한, 단어의 시작과 끝에 <와 >을 추가하여 단어 간 경계를 구분하였습니다. 예를 들어 '강아지'는 {<, ㄱ, ㅏ, ㅇ, ㅇ, ㅇ, ㅏ, e, ㅈ, l, e}로 분해됩니다.
💡 Extracting N-grams from jamo Sequence
분해한 한국어 단어는 두 가지 N-grams을 거칩니다.
1. Chacter-level n-grams
2. Inter-character jamo-level n-grams
Character-level n-grams
종성이 없는 경우 e를 추가하기 때문에 단일 character라도 자모 단위로 분해가 가능합니다. 가령 '먹었다'라는 단어의 경우엔
{ㅁ, ㅓ, ㄱ}, {ㅇ, ㅓ, ㅆ}, {ㄷ, ㅏ, e}
로 분해가 가능합니다.
그 후, 분해한 unigram을 기반으로 인접한 unigram들을 결합시켜 n-gram을 만듭니다. 가령 두 개의 bigram과 한 개의 trigram이라 한다면,
{ㅁ, ㅓ, ㄱ, ㅇ, ㅓ, ㅆ}, {ㅇ, ㅓ, ㅆ, ㄷ, ㅏ, e}
{ㅁ, ㅓ, ㄱ, ㅇ, ㅓ, ㅆ, ㅇ, ㅓ, ㅆ, ㄷ, ㅏ, e}
로 나뉩니다. 마지막으로 <와 >을 포함한 단어의 전체 자모 시퀀스를 추가합니다.
Inter-character jamo-level n-grams
한국어는 교착어이기 때문에 단어 안에서 의미를 담당하는 부분에 문법을 담당하는 부분이 붙어서 형성되고, 수많은 변형을 일으킵니다. 이런 변형은 주로 자모 단위 정보에서 판명되곤 합니다. 가령, 주격조사 '이'와 '가'의 경우엔 이전 character의 종성의 존재 여부로 결정됩니다. 이런 특성을 고려하여 인접한 character 간의 자모 단위 n-gram도 사용하였습니다.
가령 자모 단위 trigram을 사용한다면 다음과 같습니다.
{<, ㅁ, ㅓ}, {ㅓ, ㄱ, ㅇ}, {ㄱ, ㅇ, ㅓ}, {ㅆ, ㄷ, ㅏ}, {ㅓ, ㅆ, ㄷ}, {ㅏ, e, >}
💡 Subword Information Skip-Gram
학습 코퍼스가 단어 시퀀스 로 구성된다 하면 target 단어 의 context 의 로그 확률은 다음과 같이 최대화됩니다.
c는 context window의 크기이고 t는 코퍼스의 전체 단어 수입니다. 기존 Skip-Gram 모델은 log \ p(w_{t+j}|w_t)를 위해 softmax 함수를 사용했으나, 이는 큰 연산 비용을 요구합니다. 따라서 Noise Contrastive Estimation을 통해 로그 확률를 최대화합니다.
🤔 Noise Contrastive Estimation?
확률 분포를 직접 추정하는 것 대신, 실제분포와 노이즈 분포를 분류하는 이진 분류 문제로 전환하여 효율적으로 학습하는 방법을 말합니다.
실제 단어 쌍을 positive sample, 무작위 생성 쌍을 negative sample로 설정하여 두 쌍을 구분하도록 학습합니다.
따라서 binary logistic loss를 적용하면
로 변환됩니다.
는 negative sample의 수이고, 는 skip-gram에서 사용하는 scoring function입니다. 기존 skip-gram 논문에서는 target word vector 와 context word vector 결과값인 의 dot product로 설정하였으나, 이후 subword information skip-gram 모델에서는 단어로부터 추출된 n-gram 집합의 평균 벡터로 설정합니다.
논문에서도 이를 따라 scoring function을 다음과 같이 설정합니다.
는 를 n-gram으로 분해한 집합이고, 는 각 원소입니다. 는 의 전체 원소 개수입니다. 일반적으로, 으로 설정됩니다.
전체 scoring function은 char 단위 n-gram과 자모 단위 n-gram의 합의 평균으로 결정됩니다.
는 char 단위 n-gram을 뜻하고, 는 자모 단위 n-gram을 뜻합니다. 은 char 단위 n-gram과 자모 단위 n-gram의 전체 수입니다. ()
✔️ Experiments
💡 Corpus
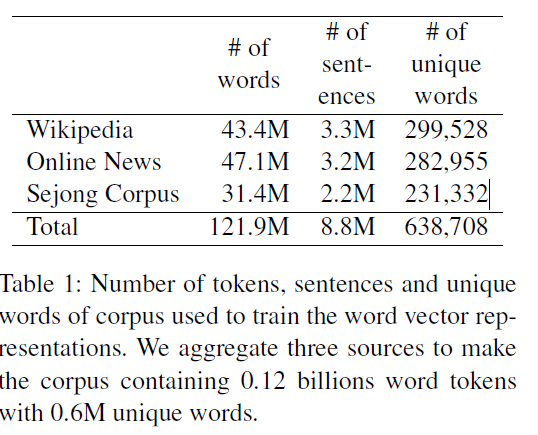
논문에선 다음 세 소스의 데이터로 638,708개의 고유한 단어를 가진 0.12 billion token의 corpus를 만들었습니다.
1. Korean Wikipeida
0.4M의 문서, 3.3M의 문장과 43.4M의 단어를 수집했습니다.
2. Online News Articles
5개의 주요 신문사에서 사회, 정치, 경제, 해외, 문화, 디지털 섹션의 기사를 수집했습니다. 기사는 2017년 9월부터 11월까지로 한정하였고, 3.2M의 문장과 47.1M 단어를 수집했습니다.
3. Sejong Corpus
'21세기 세종 계획'에 따라 수집된 한국어 코퍼스입니다. 해당 코퍼스는 1998년부터 2007년까지 formal text와 informal text 모두 포함하고 있습니다. 때문에 이 코퍼스는 위키피디아나 뉴스 기사에는 없는 토픽 및 문맥을 포함하고 있습니다.
💡 Evaluation Tasks and Datasets
논문에선 word similarity task와 word analogy task로 word vector의 성능을 평가합니다. 다만 한국어 평가 데이터셋이 없기에 직접 구축하여 사용하였습니다.
Word Similarity Evaluation Dataset
논문에서는 한국어 word similarity evaluation set을 구축하였습니다. 한국어 모어 화자인 두 학부생을 대상으로 기존 영단어 pair의 WS-353 데이터를 번역하였으며, 14명의 한국어 모어 화자가 번역한 단어의 유사성을 0부터 10까지 평가하였습니다. 14개의 score 중 가장 높은 점수와 낮은 점수를 제외하여 만들었으며, 기존 점수와의 상관관계는 0.82로 번역이 충분했음을 시사합니다.
Word Analogy Evaluation Dataset
논문에서는 역시 한국어 word analogy evaluation dataset을 구축했습니다. 데이터셋은 구문 평가용 5000개 데이터와 의미 평가용 5000개 데이터를 구축했습니다.
Semantic Feature Evaluation
semantic feature를 평가하기 위해 영어 버전을 참조했스빈다. 각 아이템은 다섯 개의 카테고리로 분류되며 각 카테고리는 1000 여개 정도로 이뤄져 있습니다.
- Captial-Country(Capt.): 나라 이름과 수도 페어입니다.
ex) 아테네 : 그리스 = 바그다드 : 이라크 - Male-Female(Gend.): 남자 여자 페어입니다.
ex) 왕자 : 공주 = 신사 : 숙녀 - Name-Nationality(Name): 유명인사와 출신지 페어입니다.
ex) 간디 : 인도 = 링컨 : 미국 - Country-Language(Lang): 나라 이름과 공식어 페어입니다.
ex) 아르헨티나 : 스페인어 = 미국 : 영어 - Miscellaneous(Mics.): 잡다한 페어를 포함합니다.
ex) 개구리 : 올챙이 = 말 : 망아지, 부산 : 경상남도 = 대구 : 경상북도
Syntactic Feature Evaluation
한국어 구문은 영어와 성질이 다르기 때문에 새로운 평가기준을 만들었습니다.
- Case: 여러 격조사는 보통명사에 부착됩니다. 이는 단어 레벨에서 표현되는 한국어를 평가할 수 있습니다.
ex) 교수 : 교수가 = 축구 : 축구가 - Tense: 현재 시제와 과거 시제를 비교합니다.
ex) 싸우다 : 싸웠다 = 오다 : 왔다 - Voice: 능동태와 수동태를 비교합니다.
ex) 팔았다 : 팔렸다 = 평가했다 : 평가됐다 - Verb ending: 동사의 어미 활용형을 비교합니다.
ex) 가다: 가고 = 쓰다: 쓰고 - Honorific(Honr.): 동사의 형태론적 변화를 비교합니다. 선어말어미 '-시-'가 대표적입니다.
ex) 도왔다: 도우셨다 = 됐다: 되셨다
Sentiment Analysis
word vector의 classification 성능을 평가하기 위해 binary sentiment classfication을 수행했습니다.
Dataset
Naver Sentiment Movie Corpus로 진행했습니다. 200k의 영화 리뷰가 있고 모든 리뷰는 140자를 넘지 않습니다. 각각의 리뷰는 긍/부정으로 분류되어 있어 binary classification을 하기 적합합니다. 논문에서는 train 100k, validation 25k, test 25k로 나눠 실험을 진행했고, 구두점이나 이상한 단어들은 사전에 제하고 실험하였습니다.
Classifier
sentiment classfier로는 hidden이 300인 단일 LSTM을 사용했고 dropout은 0.5를 적용했습니다. LSTM의 마지막 레이어에 sigmoid를 적용해서 이진 분류를 수행했습니다. loss로는 cross-entropy loss를 사용했고, Adam optimizer를 lr 0.001로 설정하여 실험했습니다.
💡Comparision Models
각 모델의 hyperparameter는 word similarity task에 튜닝되었습니다. 에폭은 5로 고정하였습니다.
-
Skip-Gram(SG): 차원은 300, negative sample은 5, window size도 5로 설정하였습니다.
-
Character-level Skip-Gram(SISG(ch)): char 단위 n-gram
으로 나뉩니다. n값은 2-4입니다. -
Jamo-level Skip-Gram with Empty Jongsung Symbol(SISG(jm)): 자모 단위 n-gram으로 쪼개고, 빈 종성값
e를 사용합니다. n값은 3-6입니다.
💡 Optimization
SGD와 linearly scheduling decay를 사용하였습니다. 초기 lr값은 .025입니다.
또한, char n-gram의 n은 1-4거나 1-6으로, 자모 단위 n-gram은 3-5로 설정했습니다. 각각 SISG(ch4+jm)과 SISG(ch6+jm)으로 명명하였습니다.
✔️ Results
💡 Word Similarity
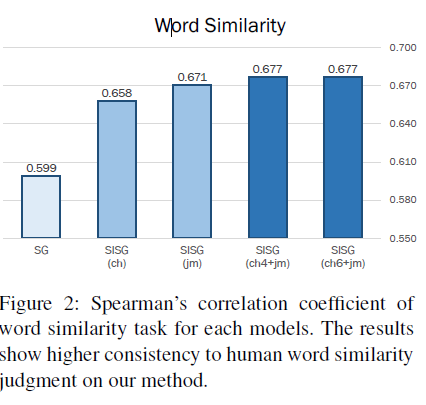
실험 결과 자모를 사용한 모델이 char 단위 모델보다 높은 점수를 기록했습니다. 이는 형태론적으로 풍부한 언어인 한국어의 경우 단어를 분해하는 것이 더 효과적이라는 것을 시사합니다.
💡 Word Analogy
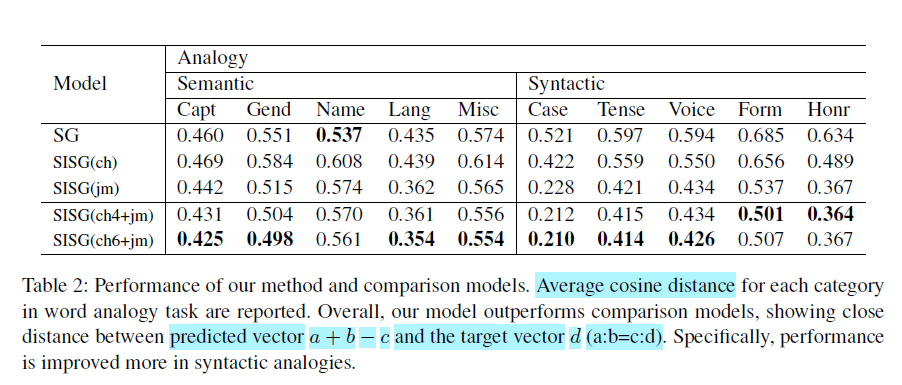
word analogy의 경우, 보통 a:b=c:d가 있고 그에 상응하는 벡터 가 있을 때 를 다른 벡터들과 코사인 거리를 계산해 비교합니다. 가 가장 높은 순위에 있을 경우 correct로 인식됩니다. 하지만 비교 모델들은 unique n-gram이나 unique word가 다르므로 top 1을 보는 것은 큰 의미가 없습니다. 따라서 와 간의 consine dinstance 값 자체를 지표로 사용했습니다.
결과를 보면, semantic analogy의 경우 단어를 char 단위로 나누는 것은 약간의 도움이 되나 자모 단위로 나누는 것은 기존보다 높은 성능을 보였습니다. Name-Nationality는 예외인데, 이는 단어를 자른다고 semantic feature가 드러나는 것이 아니기 때문에 발생하는 것이었습니다.
syntactic feature의 경우 단어를 더 깊은 레벨로 분해하는 건 해당 feature를 학습하기에 효과적이었습니다. 한국어는 교착어이므로 어근에 접사가 부착되어 단어를 형성하는 경우가 많습니다. 이를 자모 단위로 변환하여 분해하기에 더 학습에 용이한 것으로 추정됩니다.전체
💡 Sentiment Analysis
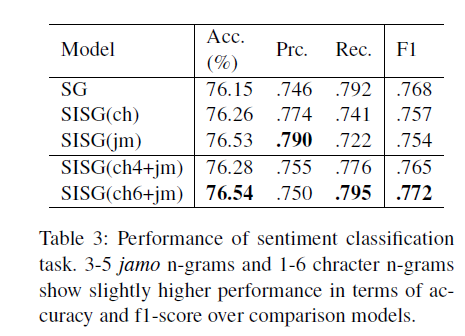
SISG(ch6+jm)이 근소하게 높은 성능을 보였습니다. 다만 F1-score의 경우 word level이 SISG(ch6+jm)과 비교가능할 정도의 점수였는데, 이는 데이터셋에 고유 명사가 많이 등장하여 단어 단위가 더 잘 이해할 수 있던 것으로 추정됩니다.
💡 Effect of Size n in both n-grams
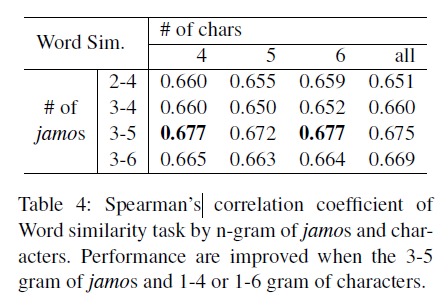
자모 단위의 경우 n=5,6이 성능 향상에 도움이 되었습니다. 반면 char 단위의 경우, n값을 어떤 것으로 하더라도 성능 향상을 보장하지 않았습니다. 대부분의 한국어 단어가 6글자 이하로 구성되어 있기 때문에 최대 n값은 6이고, 4글자 정도의 단어가 전체 코퍼스의 82.6%를 차지했기에 n=4가 적합했습니다.
✔️ Conclusion & Discussions
한국어 단어를 자모 단위나 char 단위로 자르는 것은 '-었'이나 '-시', '-고-' 등의 어근에 붙는 문자들을 잘 파악합니다. 하지만 오타가 포함된 데이터나 자모 혼자 문자처럼 사용하는 경우(ex. 'ㅋㅋ'), 또 띄어쓰기 오류 등의 경우가 자주 발생하기에 이를 고려해야할 필요가 있습니다.
