(※개인 공부 목적의 게시물입니다.)
프로그래머스 > sql > select > 대장균들의 자식의 수 구하기
<문제설명>
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다.
ECOLI_DATA 테이블의 구조는 다음과 같으며, ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각 대장균 개체의 ID, 부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ID | INTEGER | FALSE |
| PARENT_ID | INTEGER | TRUE |
| SIZE_OF_COLONY | INTEGER | FALSE |
| DIFFERENTIATION_DATE | DATE | FALSE |
| GENOTYPE | INTEGER | FALSE |
최초의 대장균 개체의 PARENT_ID 는 NULL 값입니다.
<예시>
ECOLI_DATA 테이블
| ID | PARENT_ID | SIZE_OF_COLONY | DIFFERENTIATION_DATE | GENOTYPE |
|---|---|---|---|---|
| 1 | NULL | 10 | 2019/01/01 | 5 |
| 2 | NULL | 2 | 2019/01/01 | 3 |
| 3 | 1 | 100 | 2020/01/01 | 4 |
| 4 | 2 | 17 | 2020/01/01 | 4 |
| 5 | 2 | 10 | 2020/01/01 | 6 |
| 6 | 4 | 101 | 2021/01/01 | 22 |
<문제>
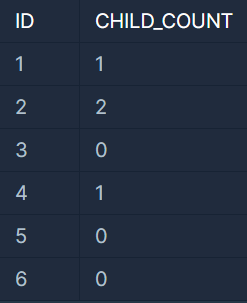
대장균 개체의 ID(ID)와 자식의 수(CHILD_COUNT)를 출력하는 SQL 문을 작성해주세요.
자식이 없다면 자식의 수는 0으로 출력해주세요.
이때 결과는 개체의 ID 에 대해 오름차순 정렬해주세요.
<풀이코드>
SELECT A.ID,
COUNT(B.ID) AS CHILD_COUNT
FROM ECOLI_DATA A
LEFT JOIN
ECOLI_DATA B
ON A.ID = B.PARENT_ID
GROUP BY A.ID
ORDER BY A.ID;<설명>
-
FROM ECOLI_DATA A LEFT JOIN ECOLI_DATA B ON A.ID = B.PARENT_ID- 자식이 없는 부모ID도 확인하기 위해 LEFT JOIN을 함(INNER JOIN을 할 경우 자식이 있는 ID만 출력됨)
A테이블 : x / B테이블 : y
[LEFT JOIN을 할 경우]
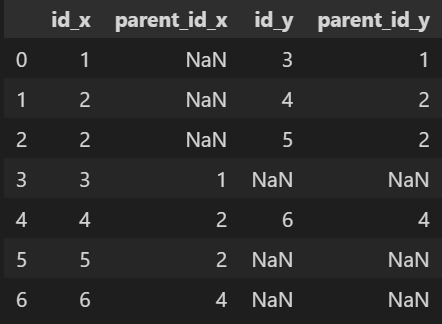
[INNER JOIN을 할 경우] : 자식개체가 없는 ID 3, 5, 6은 표시되지 않음
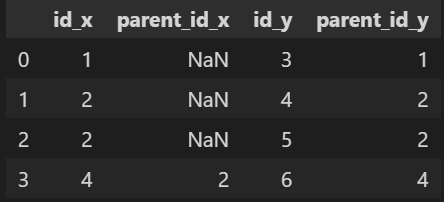
- ID 1의 자식ID -> 3
- ID 2의 자식ID -> 4, 5
- ID 4의 자식ID -> 6
- ID 1, 2는 부모가 없음
- ID 3, 5, 6은 자식이 없음
- 자식이 없는 부모ID도 확인하기 위해 LEFT JOIN을 함(INNER JOIN을 할 경우 자식이 있는 ID만 출력됨)
[LEFT/RIGHT/FULL JOIN]
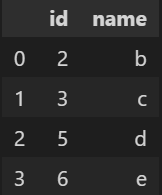
예시 데이터)
data1 / data2
 |  |
|---|
(ON data1.id = data2.id을 기준으로 한다고 가정)
-
LEFT JOIN : 왼쪽 테이블을 기준으로 ON조건에 해당하는 값이 있으면 값을 그대로 적고, 값이 없다면 NULL을 채움 => 왼쪽 테이블의 값은 모두 출력
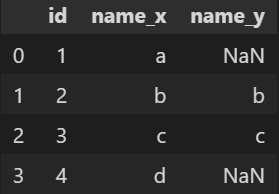
-
RIGHT JOIN : 오른쪽 테이블을 기준으로 ON조건에 해당하는 값을 적고, 값이 없다면 NULL 채움 => 오른쪽 테이블의 값은 모두 출력
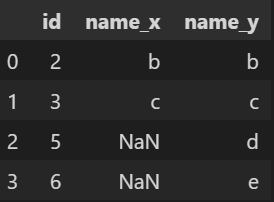
-
FULL JOIN : 양쪽 테이블 모두가 기준이 됨, LEFT JOIN결과와 RIGHT JOIN의 결과를 합집합한 것과 동일함, 중복데이터는 삭제
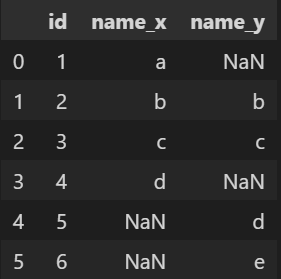
-
SELECT A.ID, COUNT(B.ID) AS CHILD_COUNT ... GROUP BY A.ID- A.ID별(부모 대장균 개체) 그룹으로 묶고, B.ID(자식 대장균 개체)의 개수를 셈
- COUNT 집계시 NULL을 제외하기 때문에, 자식이 없는 부모의 자식개수는 0으로 집계됨