(※개인 공부 목적의 게시물입니다.)
1) 프로그래머스 > sql > select > 조건에 맞는 개발자 찾기
<문제설명>
SKILLCODES 테이블은 개발자들이 사용하는 프로그래밍 언어에 대한 정보를 담은 테이블입니다.
SKILLCODES 테이블의 구조는 다음과 같으며, NAME, CATEGORY, CODE는 각각 스킬의 이름, 스킬의 범주, 스킬의 코드를 의미합니다.
스킬의 코드는 2진수로 표현했을 때 각 bit로 구분될 수 있도록 2의 제곱수로 구성되어 있습니다.
| NAME | TYPE | UNIQUE | NULLABLE |
|---|---|---|---|
| NAME | VARCHAR(N) | Y | N |
| CATEGORY | VARCHAR(N) | N | N |
| CODE | INTEGER | Y | N |
DEVELOPERS 테이블은 개발자들의 프로그래밍 스킬 정보를 담은 테이블입니다.
DEVELOPERS 테이블의 구조는 다음과 같으며, ID, FIRST_NAME, LAST_NAME, EMAIL, SKILL_CODE는 각각 개발자의 ID, 이름, 성, 이메일, 스킬 코드를 의미합니다.
SKILL_CODE 컬럼은 INTEGER 타입이고, 2진수로 표현했을 때 각 bit는 SKILLCODES 테이블의 코드를 의미합니다.
| NAME | TYPE | UNIQUE | NULLABLE |
|---|---|---|---|
| ID | VARCHAR(N) | Y | N |
| FIRST_NAME | VARCHAR(N) | N | Y |
| LAST_NAME | VARCHAR(N) | N | Y |
| VARCHAR(N) | Y | N | |
| SKILL_CODE | INTEGER | N | N |
예를 들어 어떤 개발자의 SKILL_CODE가 400 (=b'110010000')이라면, 이는 SKILLCODES 테이블에서 CODE가 256 (=b'100000000'), 128 (=b'10000000'), 16 (=b'10000')에 해당하는 스킬을 가졌다는 것을 의미합니다.
<예시>
SKILLCODES 테이블
| NAME | CATEGORY | CODE |
|---|---|---|
| C++ | Back End | 4 |
| JavaScript | Front End | 16 |
| Java | Back End | 128 |
| Python | Back End | 256 |
| C# | Back End | 1024 |
| React | Front End | 2048 |
| Vue | Front End | 8192 |
| Node.js | Back End | 16384 |
DEVELOPERS 테이블
| ID | FIRST_NAME | LAST_NAME | SKILL_CODE | |
|---|---|---|---|---|
| D165 | Jerami | Edwards | jerami_edwards@grepp.co | 400 |
| D161 | Carsen | Garza | carsen_garza@grepp.co | 2048 |
| D164 | Kelly | Grant | kelly_grant@grepp.co | 1024 |
| D163 | Luka | Cory | luka_cory@grepp.co | 16384 |
| D162 | Cade | Cunningham | cade_cunningham@grepp.co | 8452 |
<문제>
DEVELOPERS 테이블에서 Python이나 C# 스킬을 가진 개발자의 정보를 조회하려 합니다. 조건에 맞는 개발자의 ID, 이메일, 이름, 성을 조회하는 SQL 문을 작성해 주세요.
결과는 ID를 기준으로 오름차순 정렬해 주세요.
<풀이코드>
SELECT ID,
EMAIL,
FIRST_NAME,
LAST_NAME
FROM DEVELOPERS
WHERE (SKILL_CODE & (SELECT CODE FROM SKILLCODES WHERE NAME = 'Python')) > 0
OR
(SKILL_CODE & (SELECT CODE FROM SKILLCODES WHERE NAME = 'C#')) > 0
ORDER BY ID;
<설명>
-
WHERE (SKILL_CODE & (SELECT CODE FROM SKILLCODES WHERE NAME = 'Python')) > 0 OR (SKILL_CODE & (SELECT CODE FROM SKILLCODES WHERE NAME = 'C#')) > 0- 비트연산자 &(AND;교집합)으로 연산하면 2진수로 바뀌어 연산됨
- 개발자 SKILL_CODE에 'Python'의 CODE가 포함되어 있다면 둘의 &연산 결과는 0 이상일 것
- "Python 이거나 C# 스킬을 가지는" 조건이므로 OR 사용
[& 연산자]
A & B > 0 : B가 A에 포함됨
A & B = 0 : B가 A에 포함안됨
A & B = B : 모든 B가 A에 포함됨
SKILL_CODE = 400 -> 110010000
('Python') CODE = 256 -> 100000000
110010000 & 100000000 = 10000000 -> 10진수 : 256
(0보다 큼 => Python스킬을 가지고 있음)
SKILL_CODE = 400 -> 110010000
('C#') CODE = 1024 -> 10000000000
110010000 & 10000000000 = 00000000000 -> 10진수 : 0
(=> C#스킬을 가지고있지 않음)
[비트 연산자]
| 연산자 | 설명 |
|---|---|
| & | AND연산(둘다 참일 경우에만 만족) |
| | | OR연산(둘 중 하나만 참이여도 만족) |
| ^ | XOR연산(값이 달라야 참(1), 같으면 거짓(0)) |
| ~ | NOT연산 |
| << | 왼쪽 시프트 연산자(왼쪽 값을 오른쪽 값만큼 비트를 왼쪽으로 이동) |
| >> | 오른쪽 시프트 연산자(왼쪽 값에 오른쪽 값만큼의 부호비트를 채우면서 오른쪽으로 이동) |
(MySQL에서 2진수 표현하는 방법 : b' ' -> ' ' 안에 2진수 적기)
-
SKILL_CODE & (SELECT CODE FROM SKILLCODES WHERE NAME = 'Python')- 서브쿼리를 사용해서 얻은 컬럼값과 &연산가능
[서브쿼리]
- 서브쿼리는 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문을 말함
- 괄호() 안에 작성
- 서브쿼리는 메인쿼리의 컬럼을 사용할 수 있지만, 메인쿼리는 서브쿼리의 컬럼을 사용할 수 없음
- SELECT절 서브쿼리 - 스칼라 서브쿼리(Scalar SubQuery)
# 서브쿼리를 하나의 컬럼처럼 사용
SELECT col1, (SELECT ...)- FROM절 서브쿼리 - 인라인 뷰(Inline View)
# 서브쿼리를 하나의 테이블처럼 사용(테이블 대체 용도)
FROM (SELECT ...)- WHERE절 서브쿼리 - 일반 서브쿼리
# 서브쿼리를 하나의 변수(상수)처럼 사용
WHERE col = (SELECT ...)
WHERE col IN (SELECT ...)2) 프로그래머스 > sql > select > 부모의 형질을 모두 가지는 대장균 찾기
<문제설명>
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다.
ECOLI_DATA 테이블의 구조는 다음과 같으며, ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각 대장균 개체의 ID, 부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ID | INTEGER | FALSE |
| PARENT_ID | INTEGER | TRUE |
| SIZE_OF_COLONY | INTEGER | FALSE |
| DIFFERENTIATION_DATE | DATE | FALSE |
| GENOTYPE | INTEGER | FALSE |
최초의 대장균 개체의 PARENT_ID 는 NULL 값입니다.
<예시>
ECOLI_DATA 테이블
| ID | PARENT_ID | SIZE_OF_COLONY | DIFFERENTIATION_DATE | GENOTYPE |
|---|---|---|---|---|
| 1 | NULL | 10 | 2019/01/01 | 1 |
| 2 | 1 | 2 | 2019/01/01 | 1 |
| 3 | 1 | 100 | 2020/01/01 | 3 |
| 4 | 2 | 16 | 2020/01/01 | 2 |
| 5 | 4 | 17 | 2020/01/01 | 8 |
| 6 | 3 | 101 | 2021/01/01 | 5 |
| 7 | 2 | 101 | 2022/01/01 | 5 |
| 8 | 6 | 1 | 2022/01/01 | 13 |
(각 대장균별 형질을 2진수로 나타낼 수 있음)
<문제>
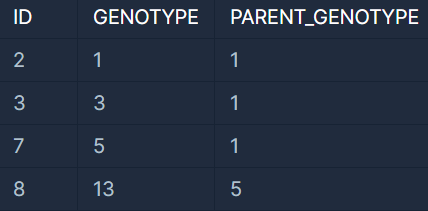
부모의 형질을 모두 보유한 대장균의 ID(ID), 대장균의 형질(GENOTYPE), 부모 대장균의 형질(PARENT_GENOTYPE)을 출력하는 SQL 문을 작성해주세요.
이때 결과는 ID에 대해 오름차순 정렬해주세요.
<풀이코드>
SELECT B.ID,
B.GENOTYPE,
A.GENOTYPE AS PARENT_GENOTYPE
FROM ECOLI_DATA A
JOIN
ECOLI_DATA B
ON A.ID = B.PARENT_ID
#A(부모)의 ID와 B(자식)의 부모ID가 같다는 것을 기준으로 함
WHERE B.GENOTYPE & A.GENOTYPE = A.GENOTYPE
#A(부모)형질을 모두 보유하고 있는 B(자식)를 구함
ORDER BY B.ID;<설명>
-
FROM ECOLI_DATA A JOIN ECOLI_DATA B ON A.ID = B.PARENT_ID- A테이블을 부모, B테이블을 자식테이블이라고 가정
- 부모테이블의 ID와 자식테이블의 부모ID가 같다는 조건으로 JOIN함
※ LEFT JOIN 시, 왼쪽테이블에 부모뿐만 아니라 자식도 포함되기 때문에 온전히 부모의 형질만 확인할 수 없음
(x = A(부모), y = B(자식))
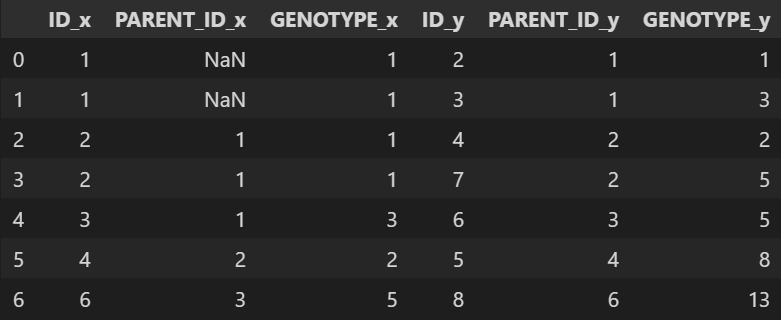
-
ID_x가 부모 대장균의 ID, ID_y가 자식 대장균의 ID
-
WHERE B.GENOTYPE & A.GENOTYPE = A.GENOTYPE- 비트연산자 중 AND연산자(&;교집합)를 사용하여 부모형질과 자식형질을 비교
- B(자식)형질이 A(부모)형질을 모두 보유한다는 의미의 조건
(B.GENOTYPE & A.GENOTYPE > 0 은 부모의 형질을 하나만 보유해도 성립이 되기 때문에 적절하지 않음)
2진수 풀이과정)

결과)