이전 글에서 다룬 결정 트리는 부정확하다. 즉, 성능이 떨어진다는 단점이 있다.
But, 결정 트리를 응용하면 성능이 좋은 다른 모델들을 만들 수 있다.
앙상블(Ensemble)
- 여러 개의 모델을 만들고, 이 모델들의 예측을 합쳐서 종합적인 예측을 하는 기법
- 하나의 모델을 쓰는 대신, 수많은 모델들을 사용해 종합적인 판단을 한다.
예를 들어, 하나의 데이터에 대해서 100개의 모델 중 과반수가 A라고 예측하면 앙상블 기법에서는 그 데이터를 A라고 예측한다. - 앙상블 기법은 각 모델들이 가능한 서로 독립적일 때 가장 좋은 성능을 낸다.
- Voting, Bagging, Boosting이 있다.
Bagging과 Pasting
- 훈련 세트의 서브셋을 무작위로 구성하는 것
Bagging
- bootstrap(통계학에서 중복을 허용한 resampling) 데이터 셋을 사용해서 다수의 모델을 만든다.
- 훈련 세트에서 중복을 허용하여 샘플링하는 방식
- 만든 모델들의 예측을 종합(aggregating)한다.
Bagging
Bootstrap 데이터 셋을 만들어 내고, 모델들의 결정을 합친다(aggregating)고 해서 Bagging 이라고 한다.
oob 평가
- bagging을 사용할 때 어떤 샘플은 여러 번 사용되고, 어떤 샘플은 한 번도 선택되지 않을 수 있다.
- bagging에서 사용되지 않은 샘플을 oob(out-of-bag)이라 한다.
- 따라서 oob 샘플은 훈련에 사용되지 않았으므로 검증에 사용할 수 있다.
Pasting
- 훈련 세트에서 중복을 허용하지 않고 샘플링하는 방식
특성 샘플링
- 훈련 세트 안의 샘플들 뿐만 아니라 특성도 샘플링이 가능하다.
- 이미지와 같은 고차원의 데이터에 대해서 유용하다.
랜덤 패치 방식(Random Patches Method)
- 훈련 샘플과 특성을 모두 샘플링하는 방식
서브스페이스 방식(Random Subspaces Method)
- 훈련 샘플은 모두 사용하고 훈련 특성만 샘플링하는 방식
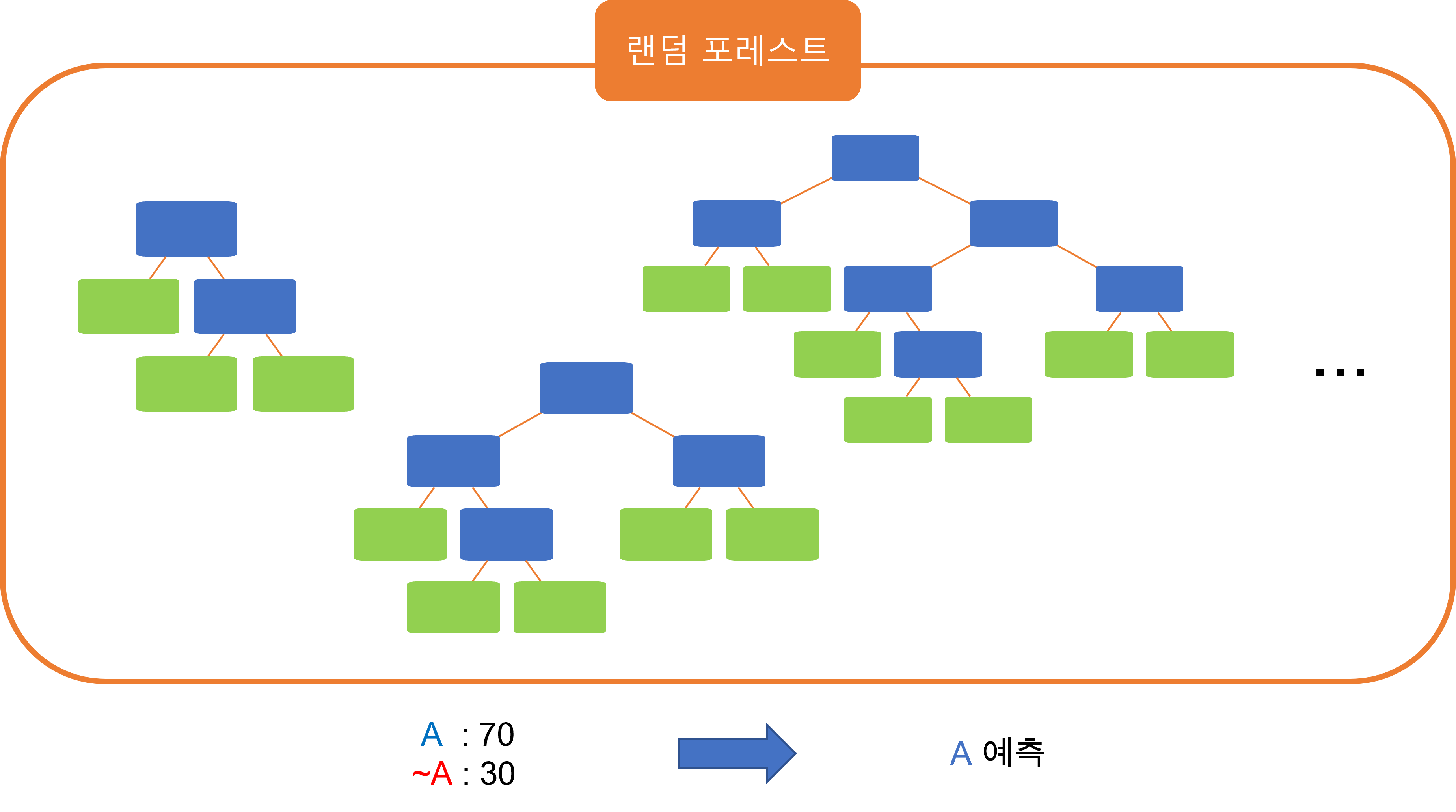
랜덤 포레스트(Random Forest)
- 트리 모델들을 임의로 많이 만들어서 다수결 투표로 결과를 종합하는 알고리즘
- 앙상블 기법 중 voting의 일종이다.
Bootstrapping
- 갖고 있는 데이터 셋으로 다른 데이터 셋을 만들어내는 방법
- 데이터 셋에 대해서 임의로 중복조합을 적용하는 방법이라고 볼 수 있다.
(특정 데이터가 여러 번 나올 수 있고, 어떤 데이터는 한 번도 나오지 않을 수 있다.)
- 모든 모델을 똑같은 데이터 셋으로 학습시키면 결과의 다양성이 떨어질 수 있기 때문에 사용한다.
결과의 다양성이 떨어지는 것을 막기 위해 각 모델을 임의로 만든 Bootstrap 데이터 셋으로 학습시킨다.
임의로 결정 트리 만들기
- 데이터의 속성을 임의로 골라 고른 속성에 대해서 지니 불순도를 구해서 root 노드의 질문을 정하고, 이를 반복하면 결정 트리를 만들 수 있다.
- 위 과정을 반복하면 수많은 결정 트리를 만들 수 있다.
Boosting
- 일부러 성능이 안좋은 모델들을 사용한다.
- 먼저 만든 모델들의 성능에 따라 그 다음 모델이 사용할 데이터 셋이 달라진다.
- 모델들의 예측을 종합할 때, 성능이 좋은 모델의 예측을 더 반영한다.
Boosting의 핵심: 성능이 안 좋은 약한 학습자(weak learner)들을 합쳐서 성능을 극대화한다.
스텀프(stump)
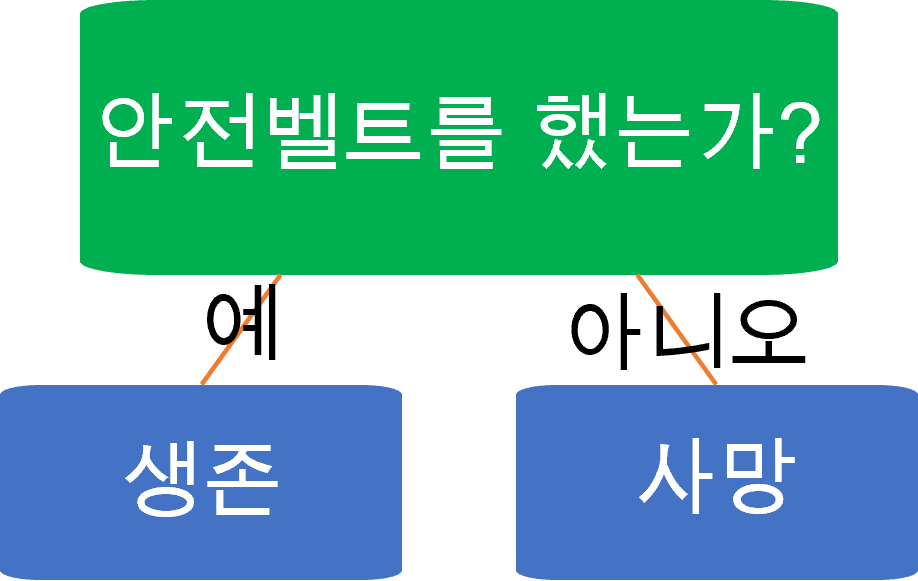
- 위와 같이 root 노드 하나와 분류 노드 두 개를 갖는 결정 트리이다.
- 성능은 평균적으로 50%보다 약간 좋다.
에이다 부스트(Adaboost)
- 성능이 별로 좋지 않은 결정 스텀프들을 많이 만든다.
- 스텀프를 만들 때, 전 스텀프들이 예측에 틀린 데이터들의 중요도를 더 높게 설정한다.
- 최종결정을 내릴 때, 성능이 좋은 결정 스텀프들의 예측의 비중은 높게, 그렇지 않은 결정 스텀프의 예측의 비중은 낮게 반영한다.
스텀프 생성 및 성능 계산
- 지니 불순도가 가장 낮은 질문으로 첫 스텀프를 만든다.
- 각 데이터는 중요도를 가진다. total_error는 틀리게 예측한 데이터의 중요도 합이다.
- 데이터의 중요도의 총합은 1이다.
- 첫 스텀프를 만들 때, 데이터는 모두 같은 중요도를 가진다.
스텀프 성능 :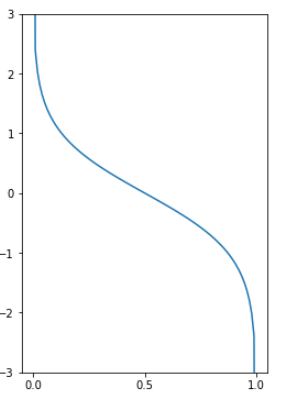
- total_error가 1에 가까워질수록 작아지고, 0에 가까워질수록 커진다.
- total_error = 1이면, 모든 데이터를 다 틀리게 예측한 경우이므로 성능이 매우 안좋으므로 성능은
- total_error = 0이면, 모든 데이터를 다 맞게 예측한 경우이므로 성능은
- total_error = 0.5면, 데이터 중 절반은 맞고 절반은 틀리게 예측하므로 성능이 아무 의미가 없어 0이 된다.
데이터 중요도 바꾸기
- 틀리게 예측한 데이터의 중요도는 높이고, 맞게 예측한 데이터의 중요도는 줄인다.
- 틀리게 예측한 데이터 중요도 :
- 맞게 예측한 데이터 중요도 :
- : 이전 중요도
- : 바뀐 후 중요도
- : 스텀프 성능
- 이후 중요도의 합이 1이 되게 하기 위해서 중요도마다 을 곱해준다.
스텀프 추가하기
- bootstrapping과 유사하지만, adaboost에서는 누적 분포 함수와 비슷하게 0~1까지 데이터 중요도를 이용해서 범위를 정해준다.
- 그 다음 0~1까지 임의의 수를 골라 해당 수가 포함되는 범위의 데이터를 추가한다.
- 중요도가 높은 데이터는 범위가 넓기 때문에 추가될 확률이 높다.
- 원래 데이터 셋의 크기만큼 반복한다.
- 새롭게 만들어진 데이터 셋의 지니 불순도를 이용해서 새로운 스텀프를 추가한다.
최종 예측
- 각 분류에 대해서 스텀프들의 성능의 합을 구한다.
- A라고 분류한 스텀프들의 성능 합: 1.5
- ~A라고 분류한 스텀프들의 성능 합: 0.7
- 위의 경우 A라고 분류한 스텀프들의 성능 합이 더 높으므로 adaboost의 예측 결과는 A이다.
그레디언트 부스팅(Gradient Boosting)
- 에이다부스트처럼 앙상블에 이전까지의 오차를 보정하도록 모델을 순차적으로 추가하는 방식
- 에이다부스트처럼 샘플의 가중치를 수정하는 대신 이전 모델이 만든 잔여 오차(residual error)로 새로운 모델을 학습시킨다.
확률적 그레디언트 부스팅(Stochastic Gradient Boosting)
- 각 트리가 훈련할 때 사용할 훈련 샘플의 비율을 지정하여 훈련 속도를 향상시키는 방법
- 편향이 증가하는 대신 분산이 낮아진다.
Stacking(Stacked Generalization)
- 앙상블에 속한 모든 모델의 예측을 취합하는 함수 대신 각 모델의 예측을 취합하는 모델을 훈련시키는 방법이다.
- 이 예측을 취합하는 마지막 모델을 블랜더(Blender) 또는 메타 학습기(Meta Learner)라고 한다.
- 서로 다른 훈련 방식으로 여러 가지 블랜더를 블랜더 레이어를 만들고, 블랜더들을 취합하는 블랜더를 사용하는 방법도 있다.
이 글은 코드잇 강의를 수강하며 정리한 글입니다. 더 자세한 설명은 코드잇을 참고하세요

미래의 개발자입니다!