
Box Plot
Box plot은 상자수염차트, 봉, 캔들 등 다양한 이름을 가진 차트입니다. 데이터의 통계적 의미를 표현할때 자주 사용되는 매우 유용한 차트입니다.
express 활용 방법
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('alcohol.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['나이']].dropna()
data = data.head(500)
# 그래프 그리기
fig = px.box(data_frame=data, y='나이')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="음주운전 발생 나이"
)
)
fig.show()
음주운전 연령 분포는 20대 후반~40대 중반이 중심이고,
30대 중반~40대가 가장 많은 비중을 차지하는 것을 볼 수 있다.
어린 나이나 고령의 음주운전은 상대적으로 적은 것을 볼 수 있다.
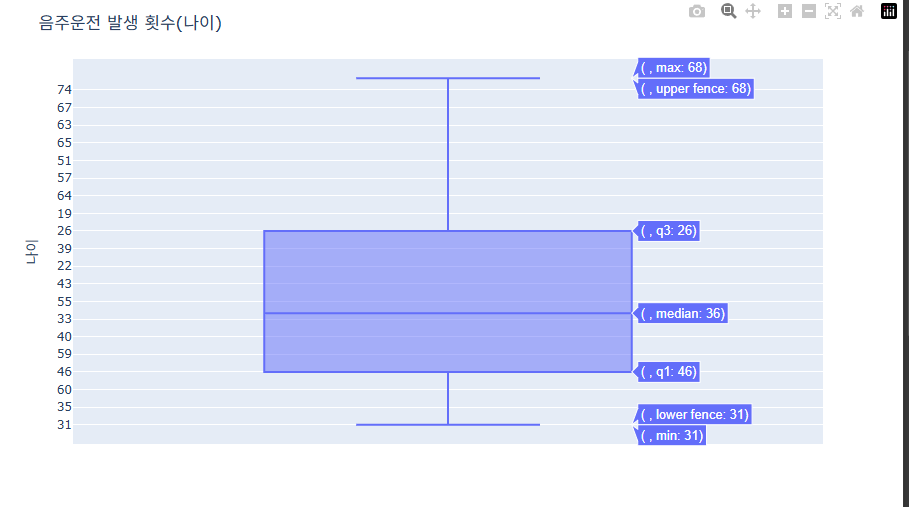
graph_objects 활용방법
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('alcohol.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['나이']].dropna()
data = data.head(500)
# 그래프 그리기
fig.add_trace(go.Box(y=data['나이']))
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="음주운전 발생 나이"
)
)
fig.show()
express 를 활용한 다양한 기능
- Point 같이 표시하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('alcohol.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['나이']].dropna()
data = data.head(500)
# 그래프 그리기
fig = px.box(data_frame=data, y='나이', points='all')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="음주운전 발생 나이)"
)
)
fig.show()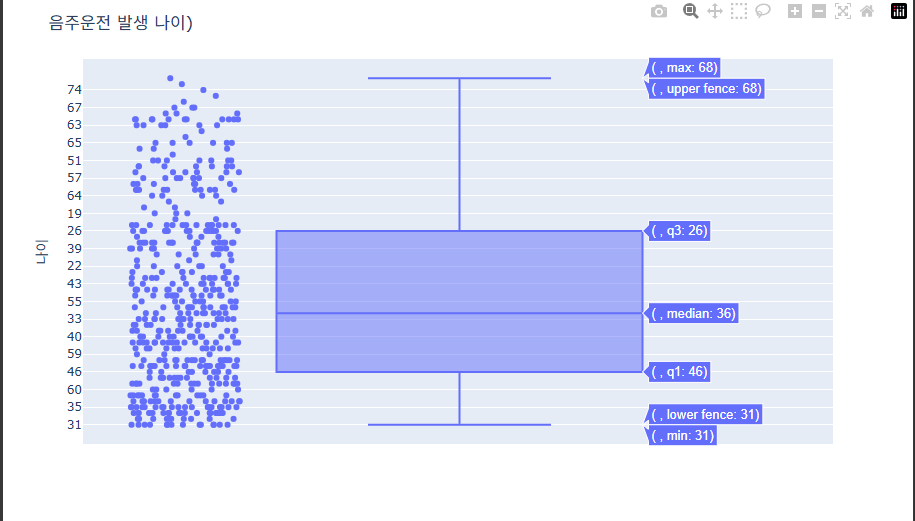
- 마커 색으로 데이터 분류하여 표시하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('alcohol.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['나이', '성별']].dropna()
data = data.head(500)
# 그래프 그리기
fig = px.box(data_frame=data, y='나이', color='성별')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="음주운전 발생 나이)"
)
)
fig.show()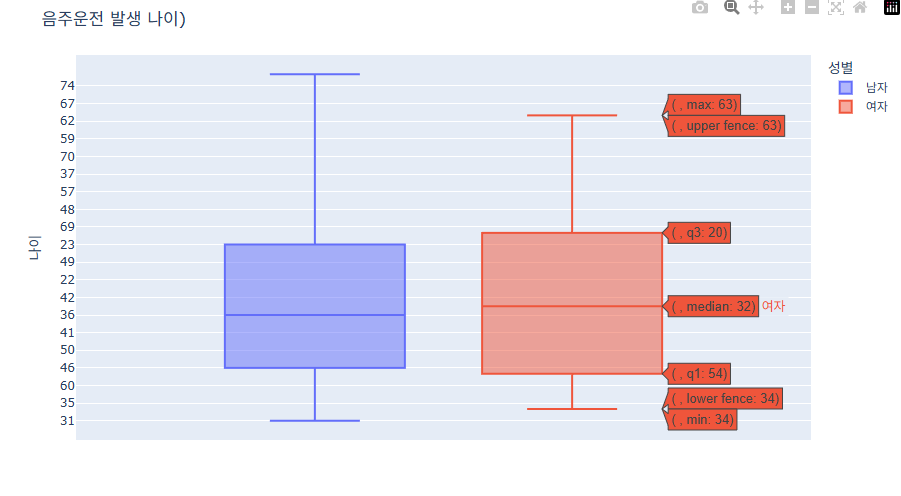
- 노치 표현하기, 및 스타일 변경
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('alcohol.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['나이', '성별']].dropna()
data = data.head(500)
# 그래프 그리기
fig = px.box(data_frame=data, y='나이', notched=True)
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="음주운전 발생 나이)"
)
)
fig.update_traces(marker_color= "green",marker_size = 5, line_width= 2, line_color="blue",fillcolor= 'red', whiskerwidth=0.5)
fig.show()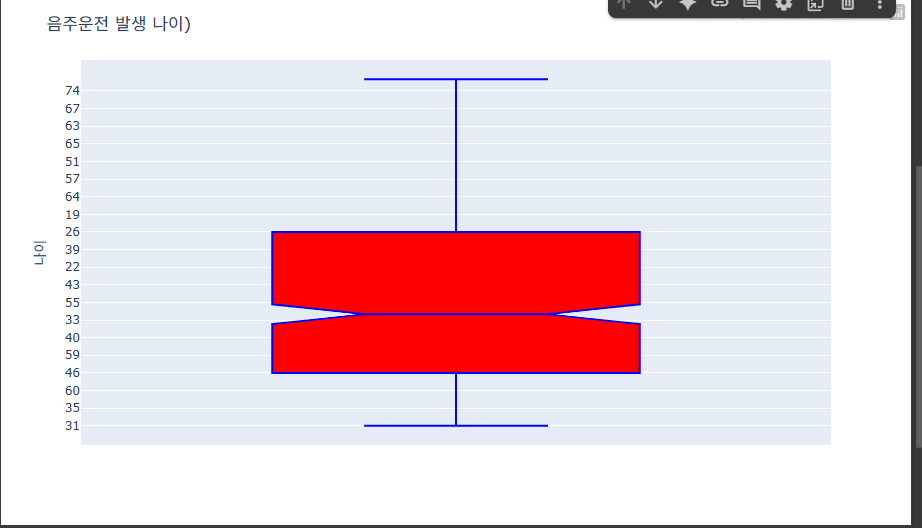
- 가로로 그리기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('alcohol.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['나이', '성별']].dropna()
data = data.head(500)
# 그래프 그리기
fig = px.box(data_frame=data, x='나이', color='성별') # Y -> X변경
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="음주운전 발생 나이)"
)
)
fig.show()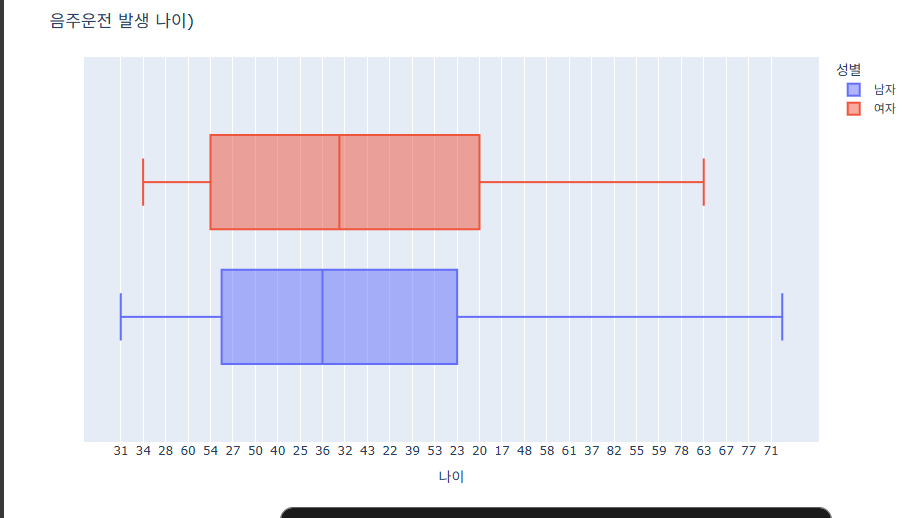
Histogram
Histogram은 마치 Bar plot(막대 차트)와 생김새는 비슷하지만, 순서형 자료와 수치형 자료를 도수분포표를 이용해서 그래프로 나타낸 것을 의미합니다.
express, graph_objects를 활용한 방법
# express 방법
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['키', '성별']].dropna()
# 그래프 그리기
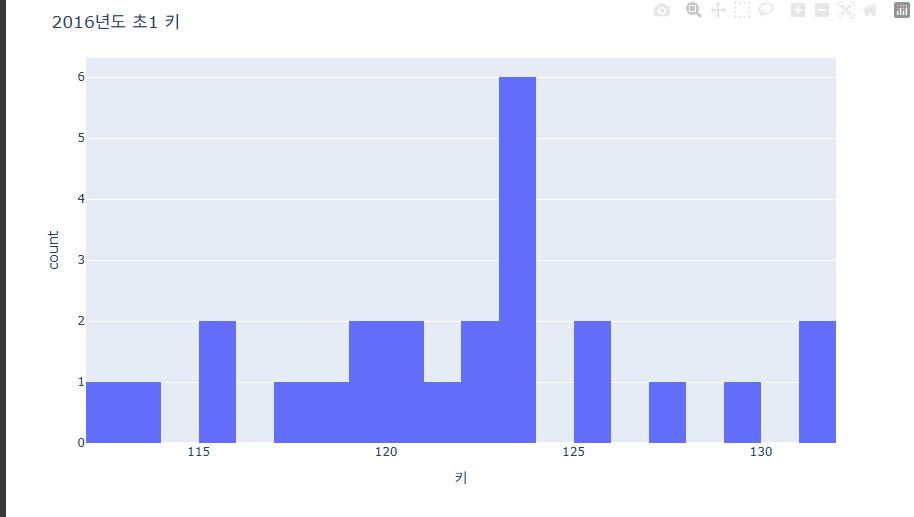
fig = px.histogram(data_frame=data, x='키', nbins=20) # bin 사이즈를 변경하여 경향성을 조금 더 세분화하게 나눴다.
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="2016년도 초1 키"
)
)
fig.show()# graph_object 방법
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['키', '성별']].dropna()
# 그래프 그리기
fig = px.histogram(data_frame = data, x="키", nbins=20)
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="2016년도 초1 키"
)
)
histfunc 을 활용하여 다른 계산식 적용하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('dobak.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['건수', '발매일자']].dropna()
# 그래프 그리기
fig = px.histogram(data, x="발매일자", y="건수", histfunc='avg')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="강원랜드 발매일자 및 건수 평균"
)
)
fig.show()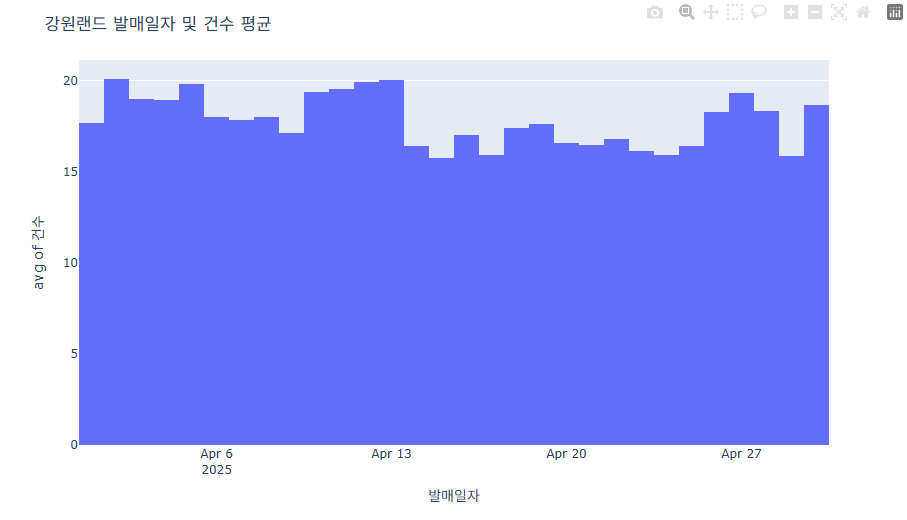
normalization 타입 정하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('dobak.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['건수', '발매일자']].dropna()
# 그래프 그리기
fig = px.histogram(data, x="발매일자", y="건수", histnorm = 'probability')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="강원랜드 발매일자 및 건수 평균"
)
)
fig.show()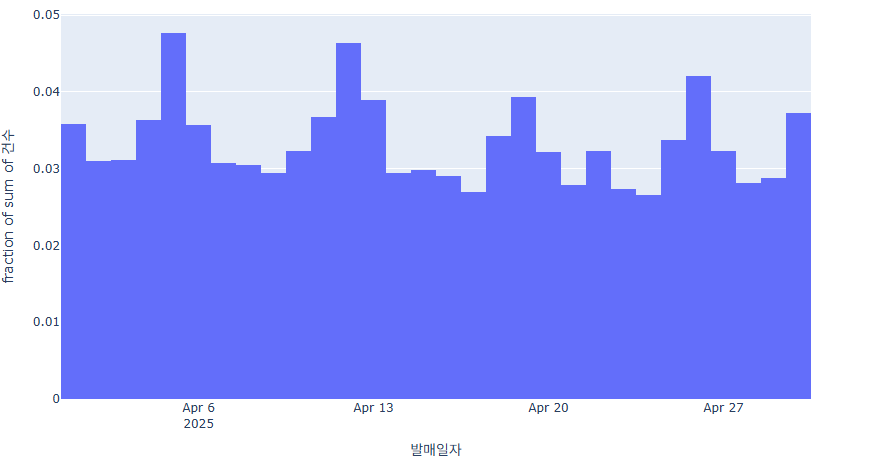
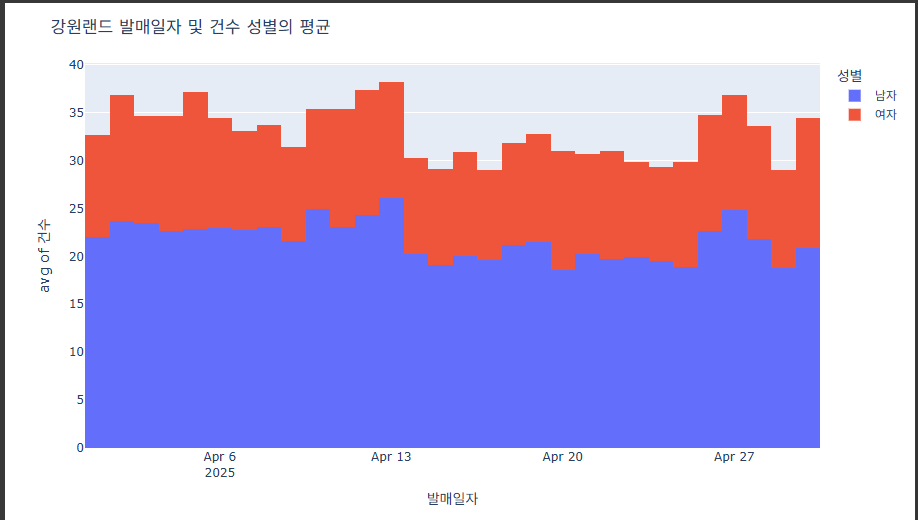
막대 겹쳐그리기/위로 쌓기
# 위로 쌓기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('dobak.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['건수', '발매일자', '성별']].dropna()
# 그래프 그리기
fig = px.histogram(data, x="발매일자", y="건수", color='성별', histfunc='avg')
fig.update_layout(barmode='stack')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="강원랜드 발매일자 및 건수 성별의 평균"
)
)
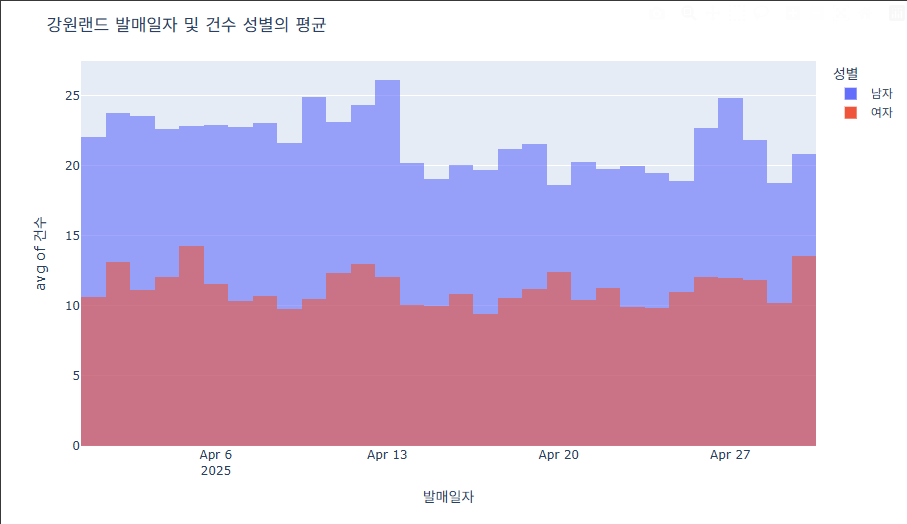
# 겹쳐 그리기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('dobak.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['건수', '발매일자', '성별']].dropna()
# 그래프 그리기
fig = px.histogram(data, x="발매일자", y="건수", color='성별', histfunc='avg', opacity=0.6)
fig.update_layout(barmode='overlay')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="강원랜드 발매일자 및 건수 성별의 평균"
)
)
히스토그램 가로로 그리기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['키', '성별']].dropna()
# 그래프 그리기
fig = px.histogram(data_frame=data, y='키', nbins=20) # bin 사이즈를 변경하여 경향성을 조금 더 세분화하게 나눴다.
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="2016년도 초1 키"
)
)
fig.show()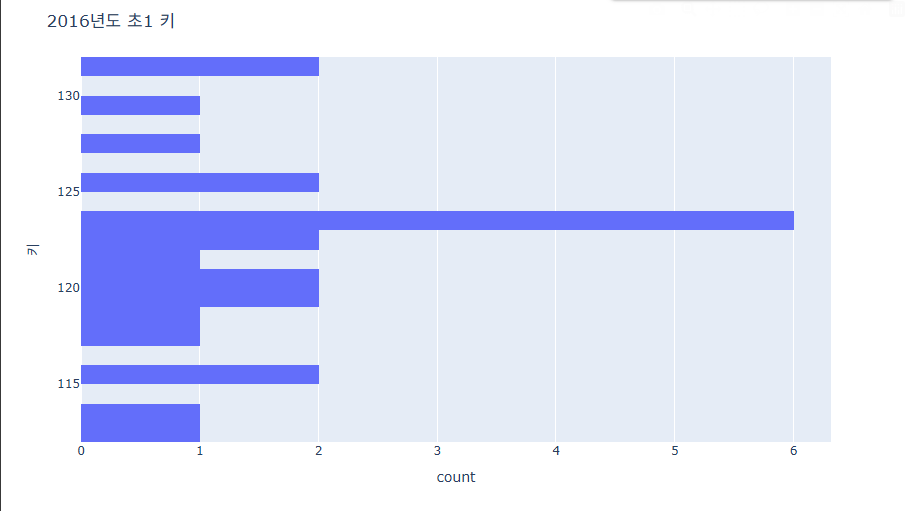
히스토그램 스타일 변경하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['키', '성별']].dropna()
# 그래프 그리기
fig = px.histogram(data_frame=data, y='키', nbins=20) # bin 사이즈를 변경하여 경향성을 조금 더 세분화하게 나눴다.
fig.update_traces(marker_color = 'red', marker_line_width=2, marker_line_color='blue', marker_opacity =0.5)
fig.update_layout(bargap=0.2)
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="2016년도 초1 키"
)
)
fig.show()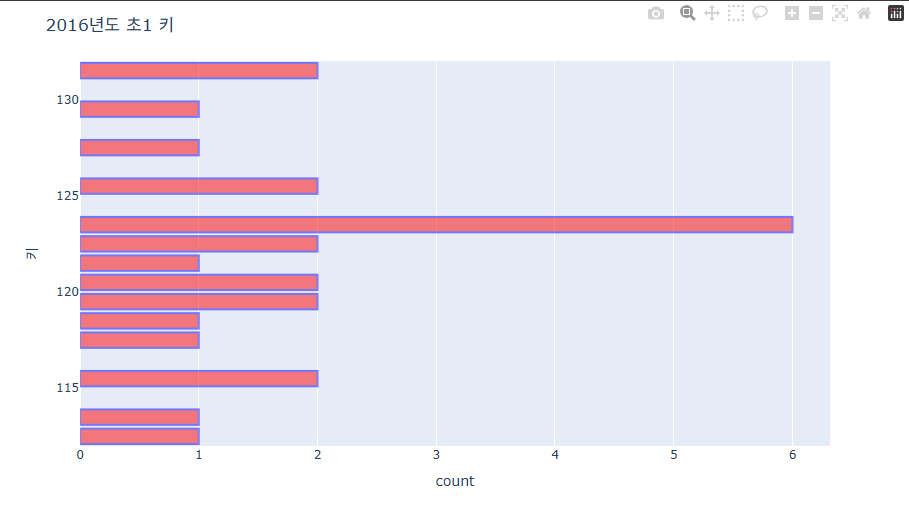
Violin Plot
Violin Plot(바이올린 플롯)은 Box Plot과 동일하게 일변량, 연속형 데이터의 분포를 설명하기 위해 사용되는 그래프 입니다. 데이터의 통계적 의미를 표현할때 자주 사용되는 매우 유용한 차트입니다.
express, graph_object를 활용하여 그리기
# express를 활용한 방법
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall_weight.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['몸무게(kg)']].dropna()
# 그래프 그리기
fig = px.violin(data, y="몸무게(kg)")
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="학생건강검진조사결과 (만6세 ~ 만18세)"
)
)
fig.show()# graph_object를 활용한 방법
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall_weight.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['몸무게(kg)']].dropna()
# 그래프 그리기
fig.add_trace(go.Violin(y=data['몸무게(kg)']))
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="학생건강검진조사결과 (만6세 ~ 만18세)"
)
)
fig.show()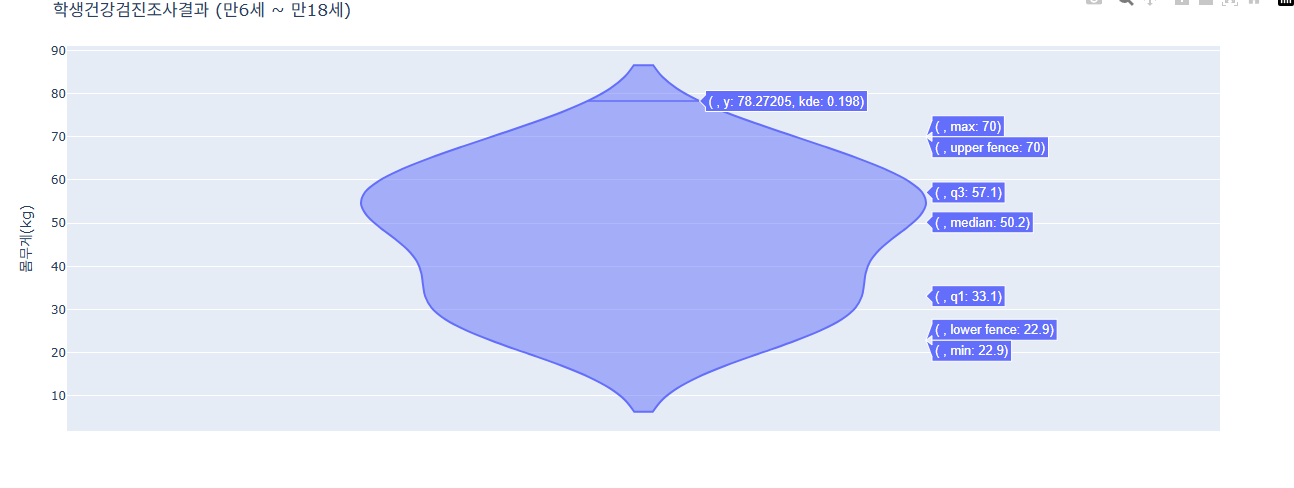
point 같이 표시하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall_weight.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['몸무게(kg)']].dropna()
# 그래프 그리기
fig = px.violin(data, y="몸무게(kg)", points='all')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="학생건강검진조사결과 (만6세 ~ 만18세)"
)
)
fig.show()
마커 색으로 데이터 분류하여 표시하기
만약 겹치고 싶다면 violinmode= 'overlay'로 설정하면 된다.
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall_weight.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['구분', '몸무게(kg)', '성별']].dropna()
# 그래프 그리기
fig = px.violin(data, x='성별', y="몸무게(kg)", color='성별' )
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="학생건강검진조사결과 (만6세 ~ 만18세)"
)
)
fig.show()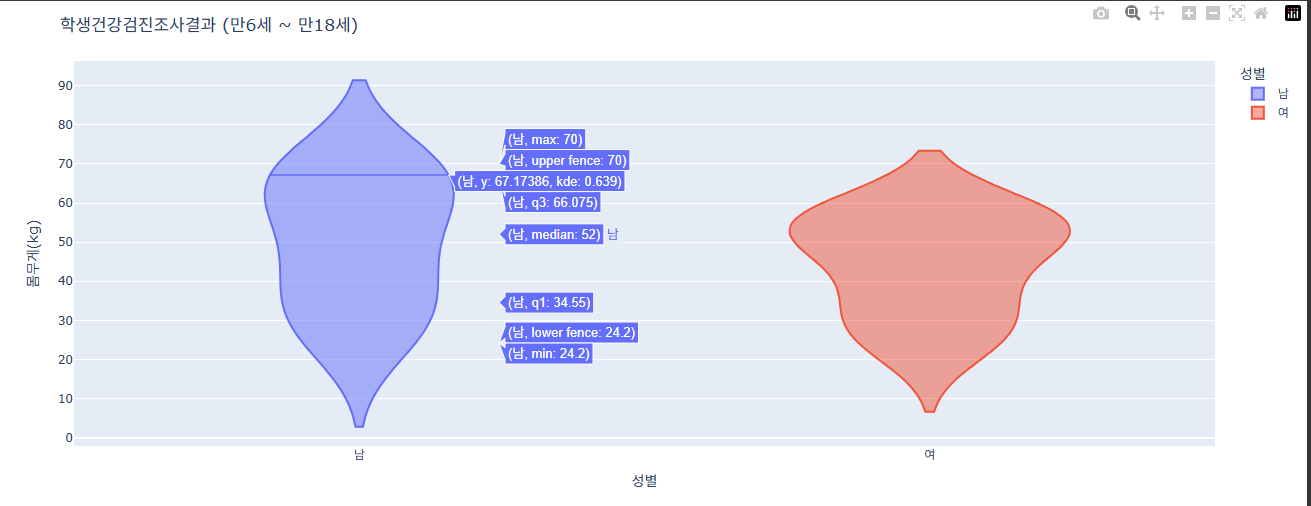
내부에 BoxPlot 같이 표시하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall_weight.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['구분', '몸무게(kg)', '성별']].dropna()
# 그래프 그리기
fig = px.violin(data, x='성별', y="몸무게(kg)", color='성별', box=True)
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="학생건강검진조사결과 (만6세 ~ 만18세)"
)
)
fig.show()
반쪽만 그리기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall_weight.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['구분', '몸무게(kg)', '성별']].dropna()
# 그래프 그리기
fig = px.violin(data, x='성별', y="몸무게(kg)", color='성별')
fig.update_traces(side='positive') # 한쪽만 그리기
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="학생건강검진조사결과 (만6세 ~ 만18세)"
)
)
fig.show()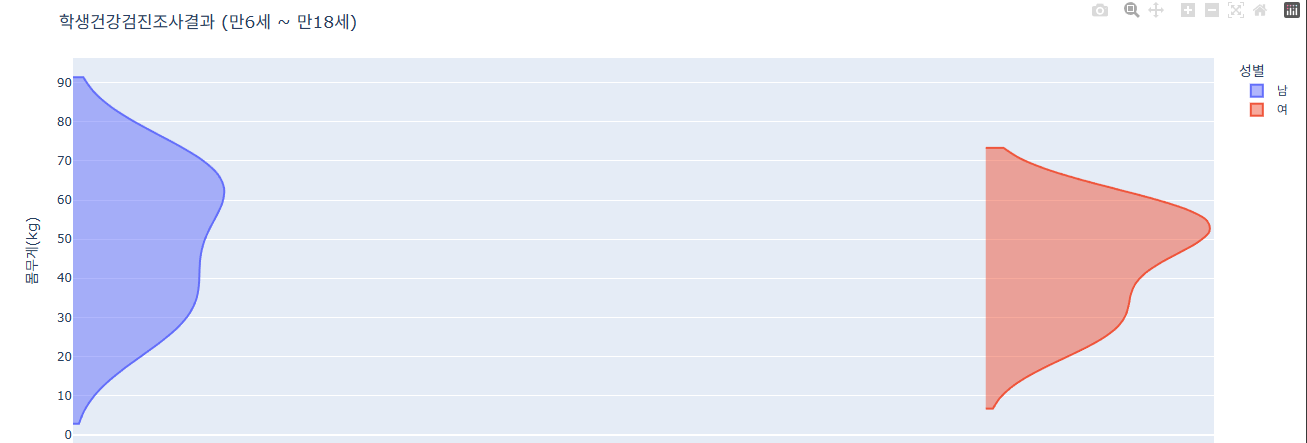
반쪽 그래프를 활용해서 양쪽에 다른 Violin 표현하기
import pandas as pd
import plotly.graph_objects as go
# 데이터 로드 및 전처리
data = pd.read_csv('tall_weight.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['구분', '몸무게(kg)', '성별']].dropna()
data['성별'] = data['성별'].str.strip()
data['몸무게(kg)'] = pd.to_numeric(data['몸무게(kg)'], errors='coerce')
data = data.dropna(subset=['몸무게(kg)'])
fig = go.Figure()
# 왼쪽 그래프
male_weight = data[data['성별'] == '남']['몸무게(kg)']
fig.add_trace(go.Violin(
x=['몸무게 분포'] * len(male_weight),
y=male_weight,
name='남자',
side='negative',
line_color='blue',
fillcolor='blue',
opacity=0.6,
))
# 오른쪽 그래프
female_weight = data[data['성별'] == '여']['몸무게(kg)']
fig.add_trace(go.Violin(
x=['몸무게 분포'] * len(female_weight),
y=female_weight,
name='여자',
side='positive',
line_color='red',
fillcolor='red',
opacity=0.6,
))
fig.update_layout(
title="학생건강검진조사결과 (만6세 ~ 만18세)",
violingap=0,
violinmode='overlay',
yaxis_title='몸무게(kg)',
xaxis_title='성별',
width=900
)
fig.show()

Violin 가로로 그리기, 스타일 지정하기
from os import P_PGID
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import numpy as np
data = pd.read_csv('tall_weight.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['구분', '몸무게(kg)', '성별']].dropna()
# 그래프 그리기
fig = px.violin(data, x="몸무게(kg)",points='all')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="학생건강검진조사결과 (만6세 ~ 만18세)"
)
)
fig.update_traces(marker_color= "red",marker_size = 5, line_width= 2, line_color="blue",fillcolor= 'green', opacity=0.5)
fig.show()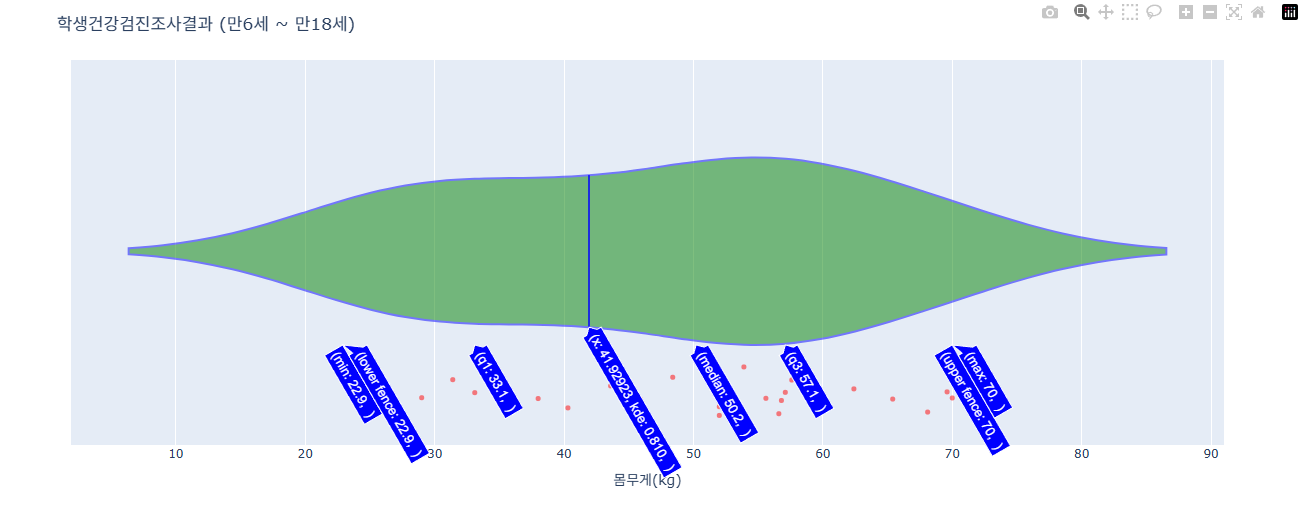

안녕하세요 게임개발을 공부하고 있는 돼지인간 입니다.