Bar Plot
Bar Plot은 막대 그래프 라고도 하며 범주형 데이터를 직사각형의 막대로 표현하는 그래프 입니다.
Express를 활용한 기본 사용방법
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
data = pd.read_csv('police_call.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['순번', '시도청', '건수']].dropna()
# express를 활용해 기본적으로 line 그래프를 그려봤다.
fig = px.bar(data_frame= data, x='시도청', y='건수')
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="시도청별 경찰청_주요 112 신고 건수 현황",
)
)
fig.show()
서울청에서 제일 신고 건수가 높은 것을 확인할 수 있고 두번째는 경기 남부청이다.
두 곳이 인구가 다른 지역에 비해 많은 것에 따라 인구가 많으면 범죄 발생 횟수가 높아진 것을
볼 수 있다.

graph_objects를 활용한 기본 사용
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
data = pd.read_csv('police_call.csv', encoding='utf-8')
data.columns = data.columns.str.strip()
data = data[['순번', '시도청', '건수']].dropna()
# graph_object를 활용해 그래프를 그려봤다.
fig.add_trace(go.Bar(x=["시도청"], y=["건수"]))
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_layout(
title=dict(
text="시도청별 경찰청_주요 112 신고 건수 현황",
)
)
fig.show()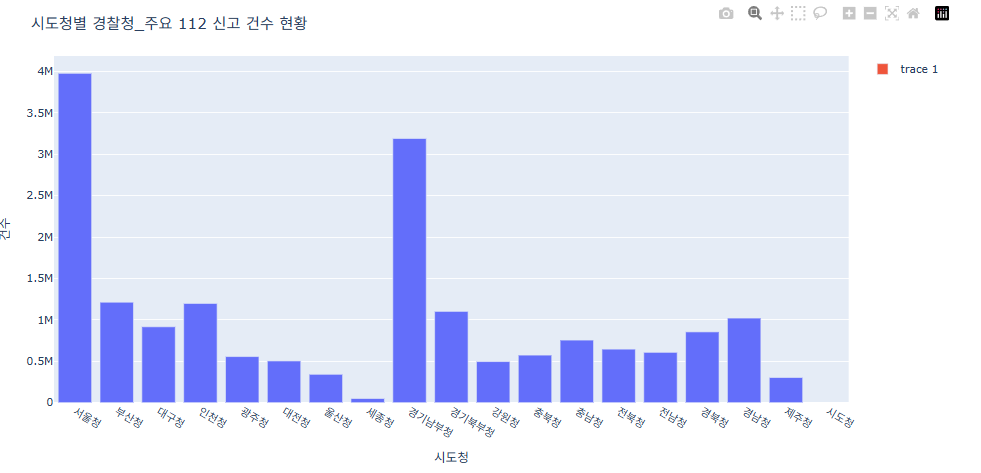
수평 막대그래프 그리기
- express
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
# CSV 불러오기
data = pd.read_csv('bilion.csv', encoding='utf-8')
data.columns = data.columns.str.strip() # 혹시 모를 공백 제거
# '구분'을 기준으로 나머지 연도 컬럼들을 long-format으로 변환
data_long = data.melt(id_vars='구분', var_name='연도', value_name='발생건수')
# 연도는 문자열로 되어 있으니 정렬을 위해 숫자형으로 바꾸는 것이 좋음 (선택사항)
data_long['연도'] = data_long['연도'].astype(str)
# 그래프 그리기
fig = px.bar(
data_frame=data_long,
x='발생건수',
y='구분',
color='연도',
barmode='group',
orientation='h',
title="경찰청 5대 범죄 발생 건수 (2018~2023)"
)
# 레이아웃 설정
fig.update_layout(
xaxis_title="범죄 유형",
yaxis_title="발생 건수",
legend_title="연도",
)
fig.show()
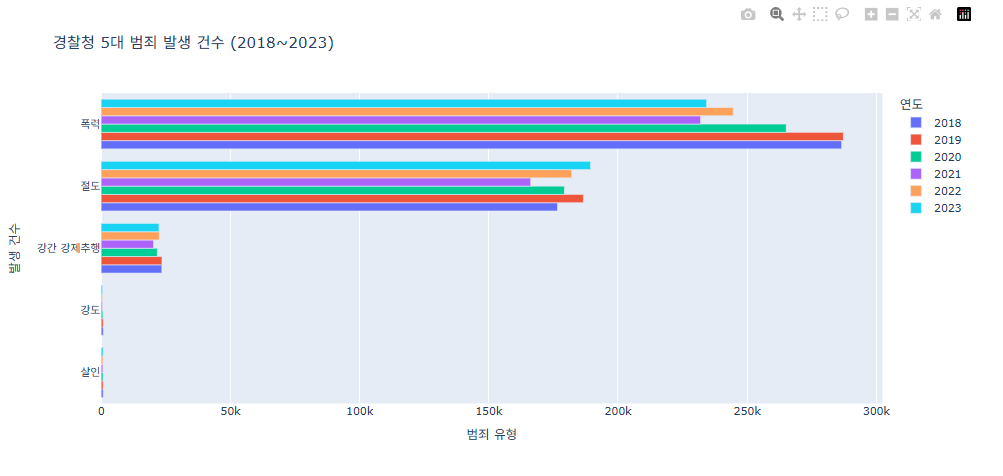
잘못 신고한 경우도 있겠지만 만약 실제로 범죄가 일어나 신고했다면
어떤 범죄가 가장 많이 발생했을까? 연도별로 확인해보면 가장 최근엔 폭력, 절도, 강간 순으로 범죄가 발생한 것으로 볼 수 있고 강도, 살인은 극히 드물다.
- graph_objects
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
# CSV 불러오기
data = pd.read_csv('bilion.csv', encoding='utf-8')
data.columns = data.columns.str.strip() # 혹시 모를 공백 제거
# '구분'을 기준으로 나머지 연도 컬럼들을 long-format으로 변환
data_long = data.melt(id_vars='구분', var_name='연도', value_name='발생건수')
# 연도는 문자열로 되어 있으니 정렬을 위해 숫자형으로 바꾸는 것이 좋음 (선택사항)
data_long['연도'] = data_long['연도'].astype(str)
# 그래프 그리기
for 연도 in sorted(data_long['연도'].unique()):
subset = data_long[data_long['연도'] == 연도]
fig.add_trace(go.Bar(
x=subset['발생건수'],
y=subset['구분'],
name=연도,
orientation='h'
))
# 레이아웃 설정
fig.update_layout(
xaxis_title="범죄 유형",
yaxis_title="발생 건수",
legend_title="연도",
)
fig.show()
위의 그래프와 같다.
막대 위에 텍스트 넣기
import pandas as pd
import plotly.express as px
# CSV 불러오기
data = pd.read_csv('cyberbilion.csv', encoding='utf-8')
data.columns = data.columns.str.strip() # 혹시 모를 공백 제거
# 2020년 '발생건수'만 선택
data_filtered = data[(data['연도'] == 2020) & (data['구분'] == '발생건수')]
# '구분'을 기준으로 나머지 범죄항목들을 long-format으로 변환
data_long = data_filtered.melt(id_vars=['연도', '구분'], var_name='범죄목록', value_name='발생건수')
# 막대 그래프 생성
fig = px.bar(data_long, x='발생건수', y='범죄목록', color='범죄목록',
title='2020년 발생건수별 사이버 범죄 유형', text_auto = True)
# 그래프 디자인 조정
fig.update_layout(
xaxis_title="발생 건수",
yaxis_title="범죄 목록",
height=800, # 그래프 크기 조정
xaxis_tickangle=45, # X축 레이블 회전
showlegend=False # 범례 숨기기
)
# 그래프 보여주기
fig.show()
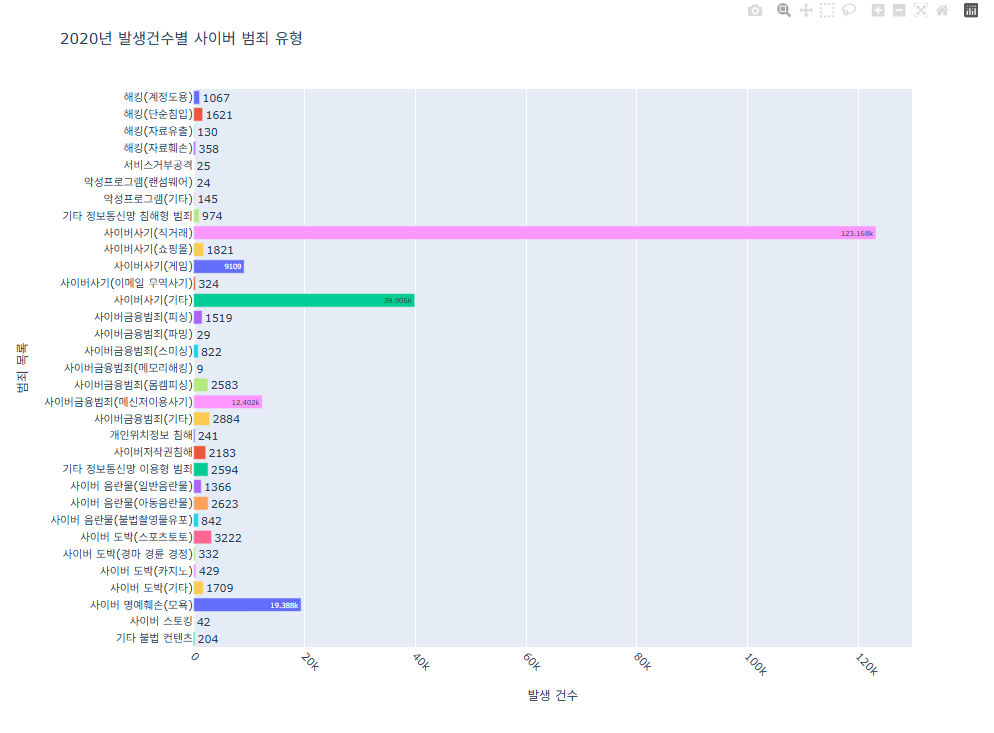
요즘 사이버 범죄가 성행하여 사이버 범죄의 발생현황이다. 직거래 품목에서 젤 많은 사기가 일어난 것으로 보인다.
쌓아 올려서 그리기
import pandas as pd
import plotly.express as px
# CSV 불러오기
data = pd.read_csv('protectbilion.csv', encoding='utf-8')
data.columns = data.columns.str.strip() # 혹시 모를 공백 제거
data = data[['유형', '사이버범죄 예방교육과목명', '년도']].dropna()
fig = px.bar(data, x="유형", y="사이버범죄 예방교육과목명", color = '사이버범죄 예방교육과목명', title="2023 사이버 범죄 예방 교육")
fig.show()
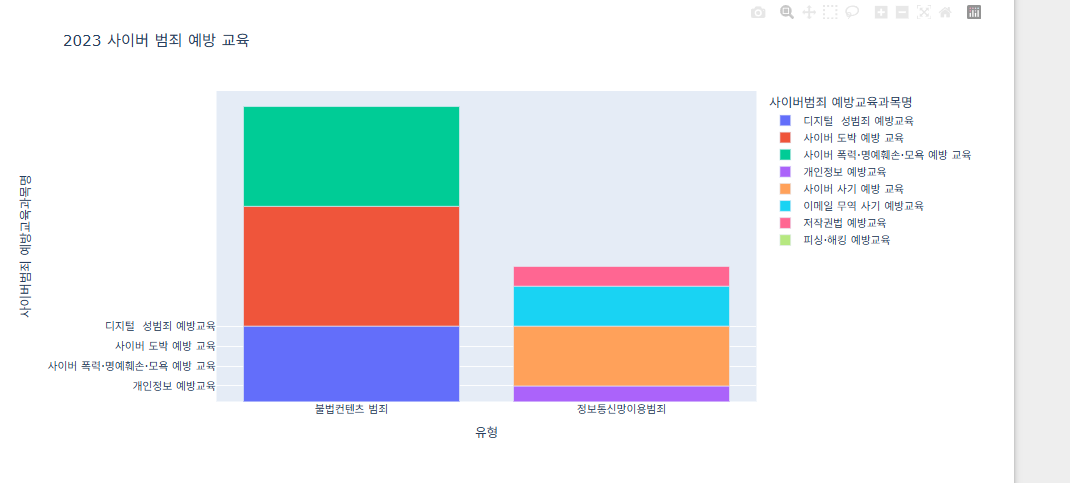
그럼 사이버 범죄 교육은 어떤 교육이 젤 많이 이루어 졌을까? 불법컨텐츠 범죄 유형에선 저작권법
정보통신망이용범죄에선 사이버 사기 예방 교육이 제일 많이 이루어졌다.

안녕하세요 게임개발을 공부하고 있는 돼지인간 입니다.