시리즈 수정/추가/삭제
수정 (loc) 및 추가
from pandas import Series
data = [1000, 2000, 3000]
index = ["메로나", "구구콘", "하겐다즈"]
s = Series(data=data, index=index)
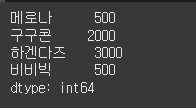
s.loc['메로나'] = 500 # 값 수정
s.loc['비비빅'] = 500 # 없는 값 삽입
print(s)다음 코드는 메로나 인덱스에 저장된 1000이라는 값을 500으로 변경합니다.
만약 없는 값을 작성한다면 새로운 값을 추가합니다.
삭제 (drop)
# print(s.drop('메로나')) // 원본은 삭제 안되게 잠금장치가 있음
from pandas import Series
data = [1000, 2000, 3000]
index = ["메로나", "구구콘", "하겐다즈"]
s = Series(data=data, index=index)
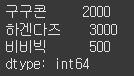
s.loc['메로나'] = 500 # 값 수정
s.loc['비비빅'] = 500 # 없는 값 삽입
s = s.drop('메로나') # s에다가 확실히 값을 반환
print(s)drop 메서드는 시리즈의 원본 데이터를 제거하지 않고 새로운 시리즈 객체를 반환합니다.
drop 메서드를 호출한 결과를 다시 변수에 바인딩하도록 코드를 작성해야 합니다.
시리즈 연산
덧셈
from pandas import Series
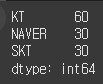
철수 = Series([10, 20, 30], index=['NAVER', 'SKT', 'KT'])
영희 = Series([10, 30, 20], index = ['SKT', 'KT', 'NAVER'])
가족 = 철수 + 영희
print(가족)데이터의 위치에 상관없이 같은 인덱스를 갖는 종목끼리 덧셈을 수행하고, 같은 인덱스에 계산 결과를 저장하는 것을 알 수 있다.
뺏셈
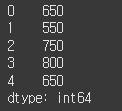
high = Series([42800, 42700, 42050, 42950, 43000])
low = Series([42150, 42150, 41300, 42150, 42350])
diff = high - low
print(diff)같은 인덱스를 갖는 각각의 값을 빼고 그 결과를 diff에 저장했다. (변동폭 구하기)
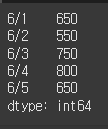
date = ["6/1", "6/2", "6/3", "6/4", "6/5"]
high = Series([42800, 42700, 42050, 42950, 43000], index=date) # index만 date추가
low = Series([42150, 42150, 41300, 42150, 42350] , index=date)
diff = high - low
print(diff)인덱스를 날짜로 바꾸어보겠다.
max_idx = 0
max_val = 0
for i in range(len(diff)):
if diff[i] > max_val:
max_val = diff[i]
max_idx = i
print(max_idx)
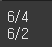
print(diff.index[max_idx])최댓값의 인덱스 뽑기를 해보겠다.
print(diff.idxmax())
print(diff.idxmin())더 쉬운 방법
나눗셈
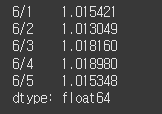
date = ["6/1", "6/2", "6/3", "6/4", "6/5"]
high = Series([42800, 42700, 42050, 42950, 43000], index=date)
low = Series([42150, 42150, 41300, 42150, 42350] , index=date)
profit = high / low
print(profit)같은 인덱스를 갖는 각각의 값을 나누고 그 결과를 profit에 저장했다.
만약 누적시키고 싶을 때 (누적 수익률 구하기)
date = ["6/1", "6/2", "6/3", "6/4", "6/5"]
high = Series([42800, 42700, 42050, 42950, 43000], index=date)
low = Series([42150, 42150, 41300, 42150, 42350] , index=date)
profit = high / low
print(profit.cumprod()) # prod가 곱이라는 뜻이기 때문에
# 누적합이라는 뜻의 cumsum()도 됨.
# 누적곱 값만 가져오기
# print( profit.cumprod( ).iloc[ -1 ] )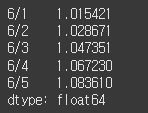
곱셈
date = ["6/1", "6/2", "6/3", "6/4", "6/5"]
high = Series([42800, 42700, 42050, 42950, 43000], index=date)
low = Series([42150, 42150, 41300, 42150, 42350] , index=date)
profit = high * low
print(profit)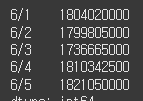
max, min
high = Series([42800, 42700, 42050, 42950, 43000])
low = Series([42150, 42150, 41300, 42150, 42350])
diff = high - low
print(diff.max())
print(diff.min())
시리즈에서 제일 큰 값을 찾을 때 max함수를 사용한다.
시리즈에서 제일 작은 값을 찾을 때 min함수를 사용한다.
Unique
from pandas import Series
companyData = {
"삼성전자": "전기,전자",
"LG전자": "전기,전자",
"현대차": "운수장비",
"NAVER": "서비스업",
"카카오": "서비스업"
}
s = Series(companyData)
print(s.unique())
중복을 제거하고 리스트를 가져오고 싶을 때가 있습니다. 이 경우 unique 메서드를 사용합니다.

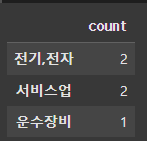
value_counts
from pandas import Series
companyData = {
"삼성전자": "전기,전자",
"LG전자": "전기,전자",
"현대차": "운수장비",
"NAVER": "서비스업",
"카카오": "서비스업"
}
s.value_counts()value_counts() 메서드를 사용하면 값의 출현 빈도를 계산해서 시리즈 객체로 반환한다.

안녕하세요 게임개발을 공부하고 있는 돼지인간 입니다.