인덱싱과 슬라이싱
넘파이는 파이썬 리스트를 확장해서 만들었기 때문에 리스트가 제공하는 대부분의 기능을 사용할 수 있다. 인덱싱에 사용하는 인덱스는 리스트와 동일하게 데이터 하나에 하나씩 맵핑됩니다.
import numpy as np
# arnage 함수로 0~3 범위의 데이터가 저장된 ndarray를 만들고 reshape 메서드로 2행 2열로 변환한다
arr = np.arange(4).reshape(2,2)
print(arr) # 슬라이싱 하기 전 코드
print(arr[0]) # 슬라이싱한 코드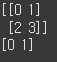
주피터 노트북은 timeit이라는 특수 명령을 제공합니다. timeit뒤에 나오는 코드를 1000만 번 반복 실행하고 걸린 시간의 평균을 반환한다.
a=np.arange(10000).reshape(100, 100)
%timeit a[0, 50] # 연속적으로 처리하는게 훨씬 빠름
a=np.arange(10000).reshape(100, 100)
%timeit a[0][50] # 느림
arr = np.arange(20).reshape(4, 5)
print(arr[ 1:4, 2:5])
print(arr[ 1: , 2: ])#행은 2이고 열은 1이다
#아래의 코드와 위의 코드는 똑같다 굳이 target을 쓸필요 없이 이중 괄호로 지정할 수 있다
#: target = [ 1: , 2: ]#1행 2열
#: print(arr[ target ])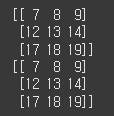
브로드 캐스팅
브로드캐스팅은 기초 파이썬 문법에 반복문을 사용해서 전체 데이터에 연산을 적용했던거와 달리, 넘파이는 연산이 전체 데이터로 확장된다.
또한 반복문을 사용하지 않으니 코드의 가독성 또한 좋아진다.
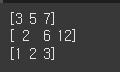
a = np.array( [ 1, 2, 3] )
b = np.array( [ 2, 3, 4] )
print( a + b ) # ndarray 요소 값끼리 더함
print( a * b ) # ndarray 요소 값끼리 곱함
print( a % b ) # ndarray 요소 값끼리 나머지를 구함
같은 인덱스를 갖는 데이터 간의 연산이 적용
브로드캐스팅은 간단히 말해 위에 사진과 같이 작은 크기의 ndarray가 큰 크기의 ndarray로 확장된다는 것을 의미한다.
함수와 메서드
sum 함수
arr = np.arange(8).reshape(4, 2)
print(arr)
print(arr.sum())
4행 2열의
ndarray에sum메서드를 적용하니 전체 데이터의 합이 계산되는 모습

sum 함수 응용
arr = np.arange(8).reshape(4, 2)
print(arr.sum(axis=0))
print(arr.sum(axis=1))axis=0은 x축 방향으로 데이터의 합을 구하라는 의미로 각각의 행 단위로 합을 구하고 그 결과를 ndarray로 반환한다.
axis=1은 y축 방향으로 합을 구해서 열 단위로 데이터의 합을 계산한다.
axis 파라미터를 입력하지 않으면 default로 axis=None이 되며, 전체 데이터의 합을 계산한다.
sum 외에도 min(최솟값), max(최댓값), mean(평균), std(표준편차), var(분산) 메서드를 사용할 수 있습니다.
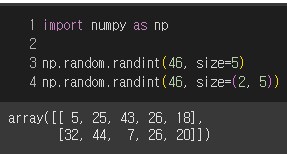
size
size 파라미터를 사용하면 생성되는 숫자의 개수를 지정할 수 있다.
파라미터에 하나의 값 혹은 튜플로 크기를 지정할 수 있고, 튜플을 입력했다면 앞의 숫자가 로우의 길이, 뒤의 숫자가 컬럼의 길이이다.