필터링
Map
from pandas import Series
def remove_comma(x):
return int(x.replace(",", ""))
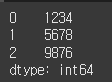
s = Series(["1,234", "5,678", "9,876"])
result = s.map(remove_comma)
print(result)Map: 반복문 형식으로 시리즈 요소 하나하나 매핑 시켜줌
Map 응용(작다, 크다 분석)
def is_greater_than_5000(x): # 5000보다 큰지 작은지 비교
if x > 5000:
return "크다"
else :
return "작다"
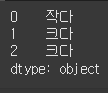
s = Series([1234, 5678, 9876]) # map으로 요소 하나하나 매핑하여 비교
result = s.map(is_greater_than_5000)
print(result)파라미터 x에는 시리즈에 저장된 값이 차례로 입력되고, 비교 연산의 결과 "크다", "작다"는 문자열이 저장된 시리즈를 반환한다.
시리즈 필터링
from pandas import Series
data = [42500, 42550, 41800, 42550, 42650]
index = ['2019-05-31','2019-05-30', '2019-05-29','2019-05-28','2019-05-27']
s = Series(data=data, index=index)
cond = s > 42000
print(cond)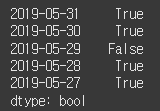
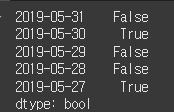
close = [42500, 42550, 41800, 42550, 42650]
open = [42600, 42200, 41850, 42550, 42500]
index = ['2019-05-31', '2019-05-30', '2019-05-29', '2019-05-28', '2019-05-27']
open = Series(data=open, index=index)
close = Series(data=close, index=index)
cond = close > open
print(cond)이번에는 시가와 종가를 시리즈 객체로 표현한 후 종가가 시가보다 큰지를 비교해 보겠다.
- 만약 종가가 시가보다 높았던 상승 마감한 날의 종가를 출력하려면 어떻게 해야 할까요?
- 만약 종가가 시가보다 높았던 상승 마감한 날짜를 출력하려면 어떻게 해야 할까요?
print(close[close > open])
print(close.index[close>open])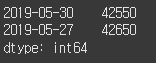

이번에는 종가가 시가보다 높은 날의 거래일과 변동폭을 출력해 보겠습니다.
close = [42500, 42550, 41800, 42550, 42650]
open = [42600, 42200, 41850, 42550, 42500]
index = ['2019-05-31', '2019-05-30', '2019-05-29', '2019-05-28', '2019-05-27']
open = Series(data=open, index=index)
close = Series(data=close, index=index)
diff = close - open
print(diff[close > open])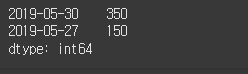
정렬 및 순위
sort_values() : 데이타 기준으로
from pandas import Series
data = [3.1, 2.0, 10.1, 5.1]
index = ['000010', '000020', '000030', '000040']
s = Series(data=data, index=index)
print(s)
# 정렬 (오름차순)
s1 = s.sort_values()
print(s1)
# 정렬 (내림차순)
s2 = s.sort_values(ascending=False)
print(s2)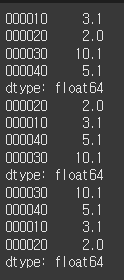
rank() : 인덱스 기준으로
data = [3.1, 2.0, 10.1, 3.1]
index = ['000010', '000020', '000030', '000040']
s = Series(data=data, index=index)
print(s.rank()) # 오름차순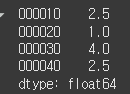
data = [3.1, 2.0, 10.1, 3.1]
index = ['000010', '000020', '000030', '000040']
s = Series(data=data, index=index)
print(s.rank(ascending=False)) # 내림차순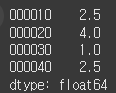

안녕하세요 게임개발을 공부하고 있는 돼지인간 입니다.