Scatter Plot
Scattor Plot(산점도)는 두 변수의 상관관계를 점으로 표현한 그래프 입니다.
Express를 활용한 기본 사용방법
예제 1) 직접 입력 방법
import plotly.express as px
fig = px.scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16])
fig.show()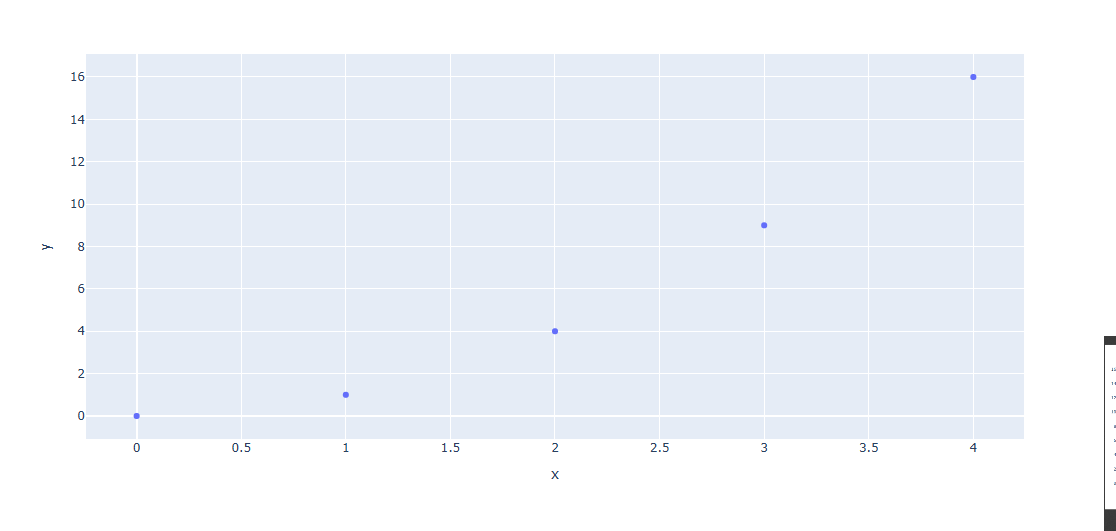
예제 2) 데이터 셋을 활용한 방법
import plotly.express as px
# 데이터 불러오기
df = px.data.iris()
fig = px.scatter(data_frame=df, x="sepal_width", y="sepal_length")
fig.show()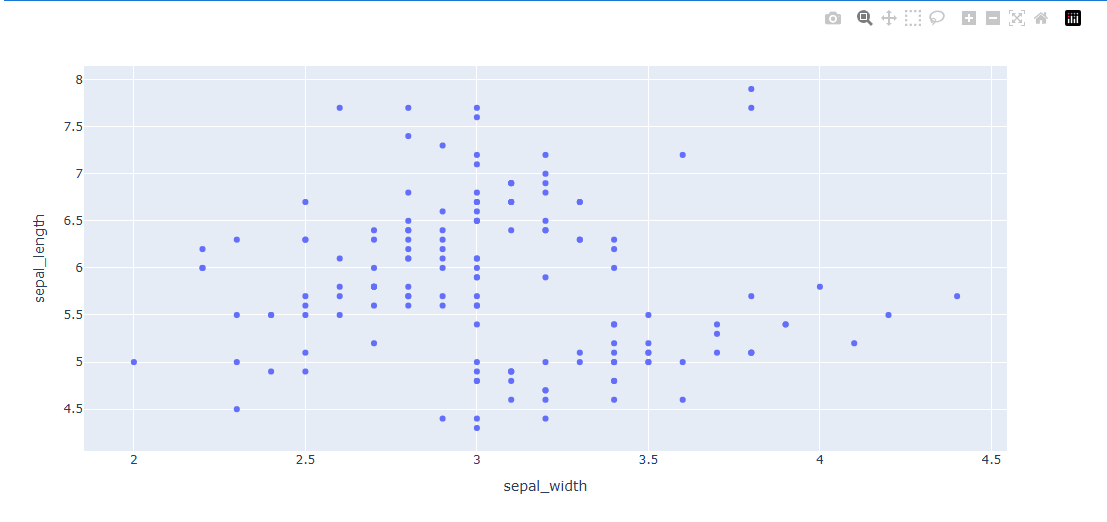
graph_objects를 활용한 기본 사용
import plotly.graph_objects as go
# 데이터 생성
import numpy as np
np.random.seed(1)
N = 100
random_x = np.linspace(0, 1, N)
random_y0 = np.random.randn(N) + 5
random_y1 = np.random.randn(N)
random_y2 = np.random.randn(N) - 5
# Figure 생성
fig = go.Figure()
# Scatter Trace 추가
fig.add_trace(go.Scatter(x=random_x, y=random_y0,
mode='markers',
name='markers'))
fig.add_trace(go.Scatter(x=random_x, y=random_y1,
mode='lines+markers',
name='lines+markers'))
fig.add_trace(go.Scatter(x=random_x, y=random_y2,
mode='lines',
name='lines'))
fig.show()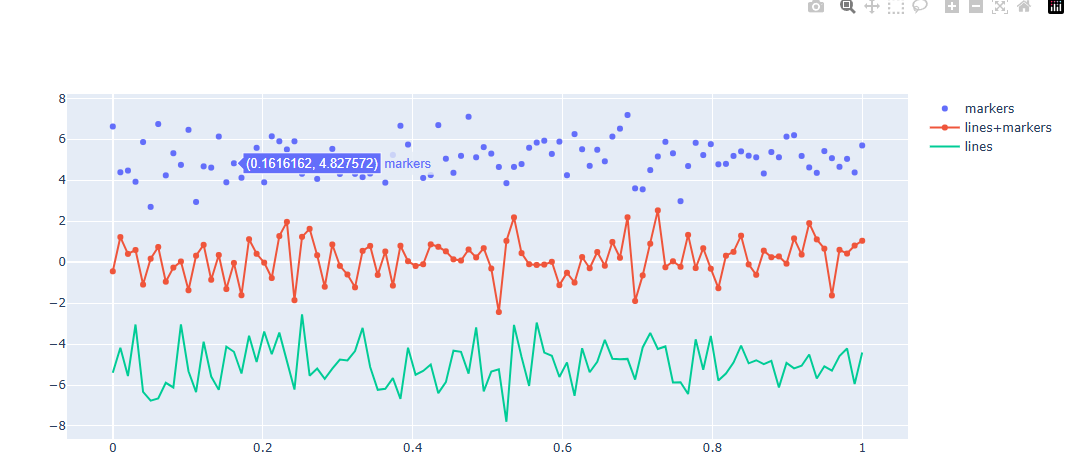
express 를 활용한 다양한 기능
- 마커 색으로 데이터 분류하기
import plotly.express as px
# 데이터 불러오기
df = px.data.iris()
# 색으로 구분하고 싶은 데이터 컬럼 명을 "color = "로 지정
fig = px.scatter(data_frame = df, x = "sepal_width", y = "sepal_length", color = "species")
fig.show()
꽃의 품종에 따라 색깔을 다르게 표시(색을 지정하지 않았기에 기본 팔레트)
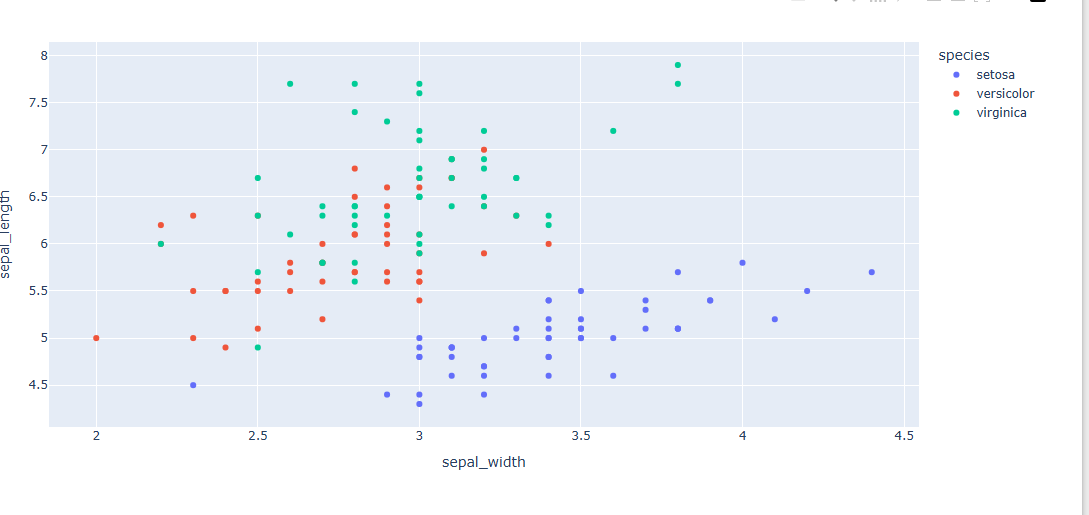
- 마커 크기 다르게 표시하기
import plotly.express as px
# 데이터 불러오기
df = px.data.iris()
fig = px.scatter(data_frame=df, x="sepal_width", y="sepal_length", size='petal_length')
fig.show()
꽃 잎의 길이에 따라 분류하므로 꽃 잎의 길이가 길 수록 점의 크기가 커진 것을 알 수 있다.
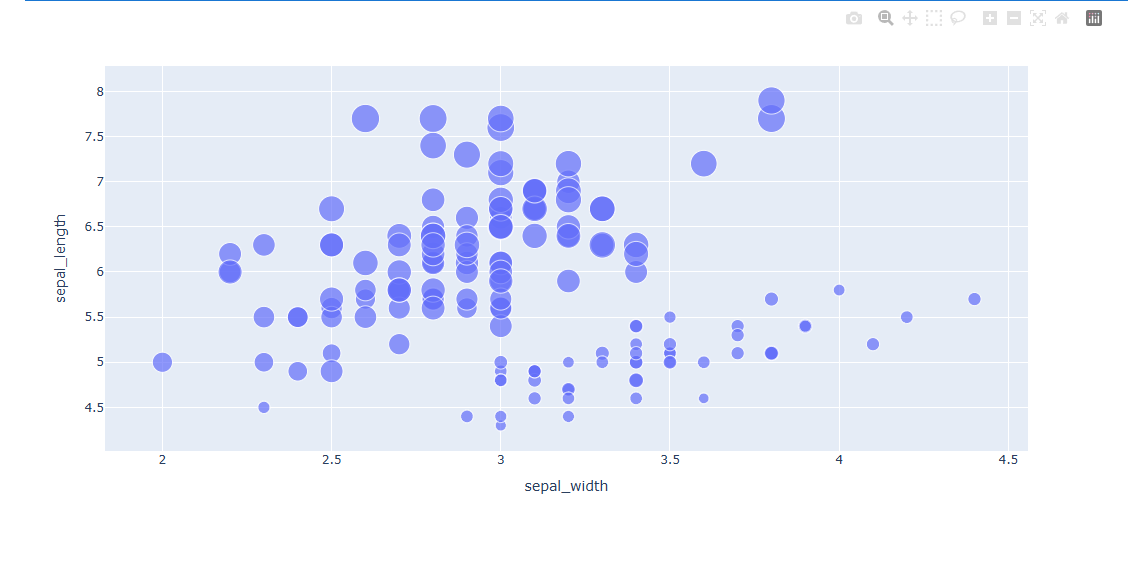
- 마커 스타일로 데이터 표시하기
import plotly.express as px
# 데이터 불러오기
df = px.data.iris()
fig = px.scatter(data_frame=df, x="sepal_width", y="sepal_length",color="species", symbol="species")
fig.show()
품종에 따라서 simbol이 변했다(ploty의 기본값으로 설정되어 있음)
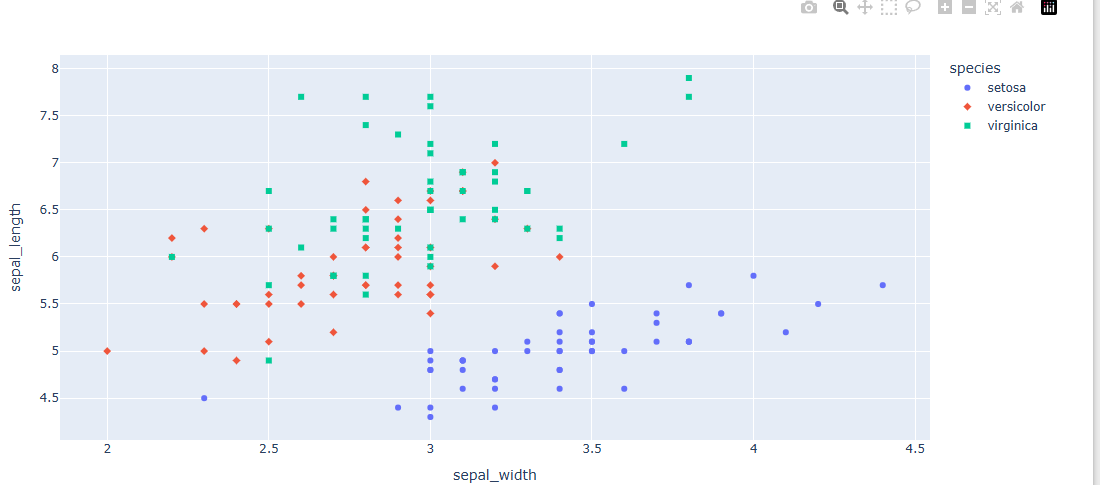
- 추세선 추가하기
import plotly.express as px
# 데이터 불러오기
df = px.data.tips()
fig = px.scatter(data_frame=df, x="total_bill", y="tip", trendline="ols")
fig.show()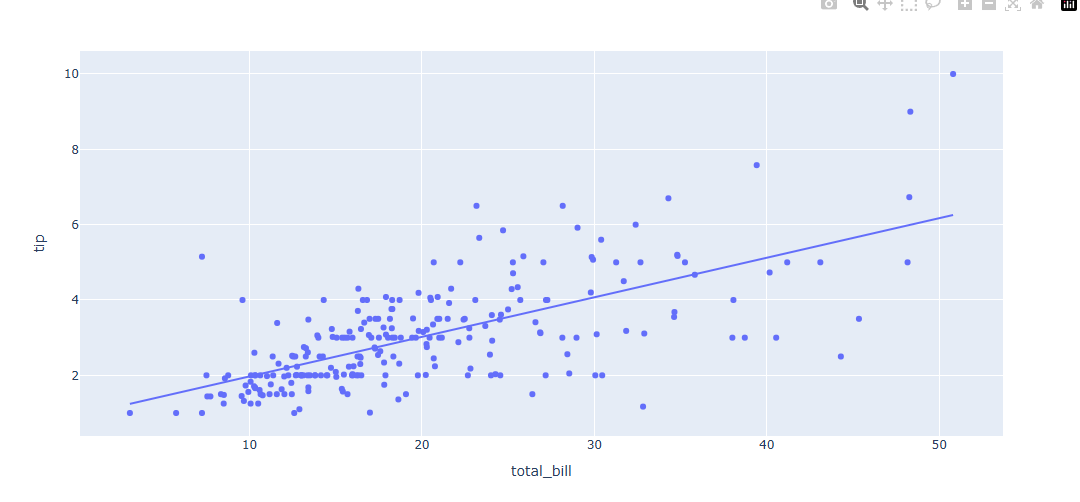
pip install statsmodels추세선 기능을 사용하려며 import을 해야함
- 여러개로 나눠 그리기 (Facet)
import plotly.express as px
# 데이터 불러오기
df = px.data.tips()
fig = px.scatter(data_frame=df, x="total_bill", y="tip",color="smoker", facet_col="sex")
fig.show()
성별, 담배 피는 여부에 따라서 나눠 그린것을 확인 할 수 있다.
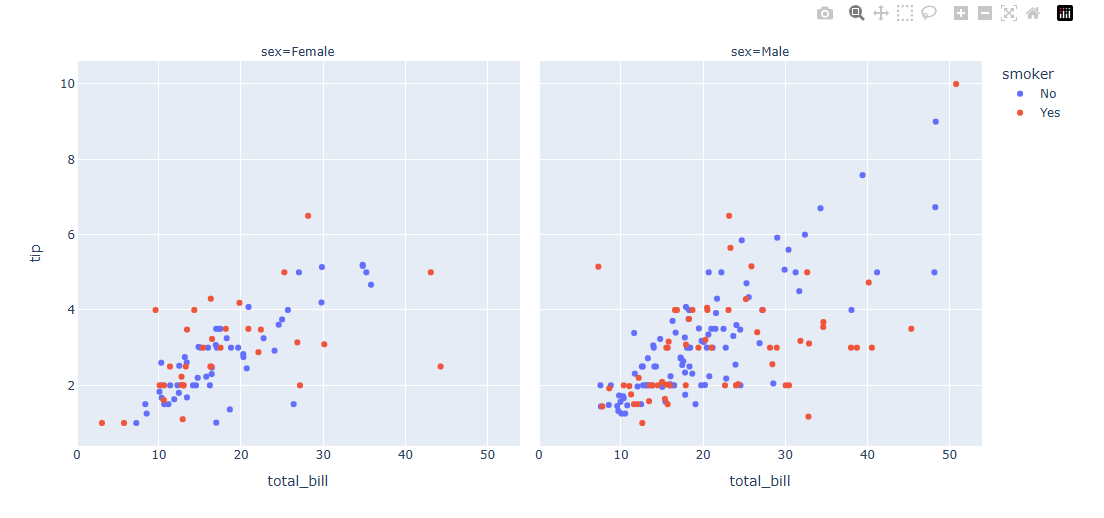
- 마커 스타일 변경하기
fig.update_traces(marker_color= 마커 색,
marker_size=마커 크기,
marker_line_width=마커 테두리 두깨,
marker_line_color=마커 테두리 색,
marker_angle = 마커 각도,
marker_symbol = 마커 모양,
marker_opacity = 마커 투명도,
)이런식의 예제로 마커의 종류를 바꿀 수 도 있다.
import plotly.express as px
# 데이터 불러오기
df = px.data.iris()
# Scatter Plot 생성
fig = px.scatter(df, x="sepal_width", y="sepal_length",color="species")
#마커 스타일 변경
fig.update_traces(marker_size=12, marker_symbol="arrow", marker_angle=45, marker_line_width=2, marker_line_color="DarkSlateGrey")
fig.show()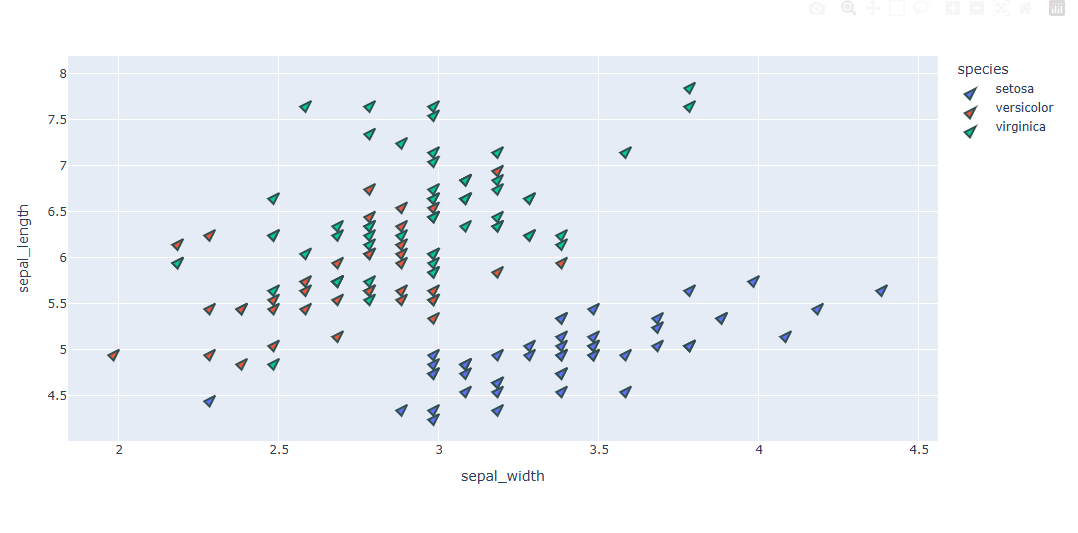
- 번외(마커의 종류 알아보기)
# 마커의 종류 알아보는 코드
import plotly.graph_objects as go
from plotly.validators.scatter.marker import SymbolValidator
raw_symbols = SymbolValidator().values
namestems = []
namevariants = []
symbols = []
for i in range(0,len(raw_symbols),3):
name = raw_symbols[i+2]
symbols.append(raw_symbols[i])
namestems.append(name.replace("-open", "").replace("-dot", ""))
namevariants.append(name[len(namestems[-1]):])
fig = go.Figure(go.Scatter(mode="markers", x=namevariants, y=namestems, marker_symbol=symbols,
marker_line_color="midnightblue", marker_color="lightskyblue",
marker_line_width=2, marker_size=15,
hovertemplate="name: %{y}%{x}<br>number: %{marker.symbol}<extra></extra>"))
fig.update_layout(title="Mouse over symbols for name & number!",
xaxis_range=[-1,4], yaxis_range=[len(set(namestems)),-1],
margin=dict(b=0,r=0), xaxis_side="top", height=1400, width=400)
fig.show()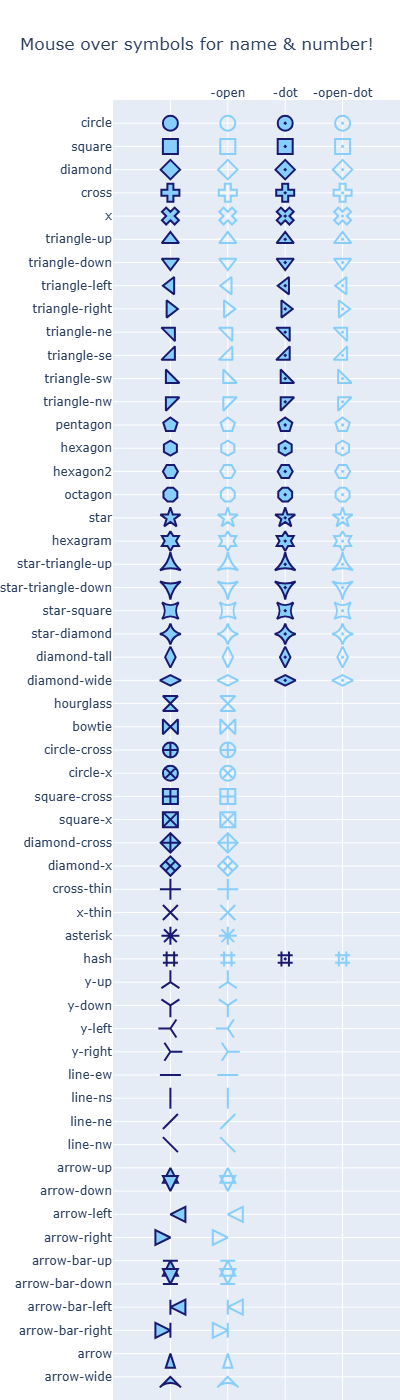
Line Plot
Line Plot은 연속적으로 변화하는 값을 순서대로 점으로 나타내고 이를 선으로 연결한 그래프 입니다.
Express를 활용한 기본 사용방법
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
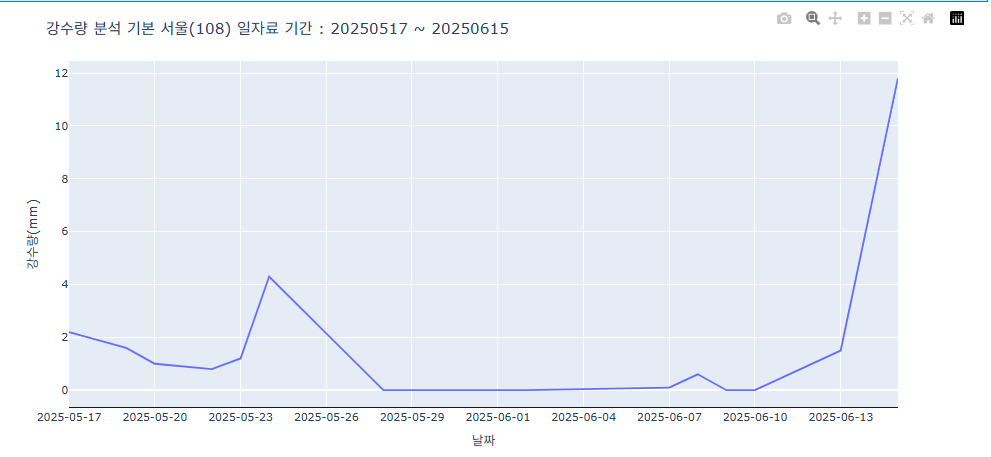
data = pd.read_csv('rain_amount.csv', skiprows=6, encoding='utf-8')
data.columns = data.columns.str.strip()
data['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data = data[['날짜', '지점', '강수량(mm)']].dropna()
# express를 활용해 기본적으로 line 그래프를 그려봤다.
fig = px.line(data_frame= data, x="날짜", y="강수량(mm)")
# 알아보기 쉽게 하기 위해 추가한 것(제목과 날짜 축 관리)
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', tickformat="%Y-%m-%d")
fig.update_layout(
title=dict(
text="강수량 분석 기본 서울(108) 일자료 기간 : 20250517 ~ 20250615",
)
)
fig.show()
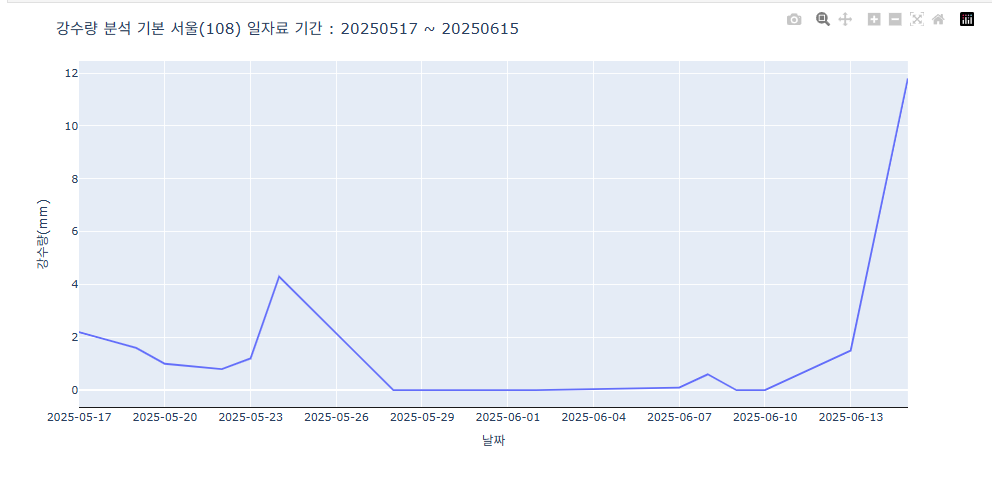
graph_objects를 활용한 기본 사용
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
data = pd.read_csv('rain_amount.csv', skiprows=6, encoding='utf-8')
data.columns = data.columns.str.strip()
data['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data = data[['날짜', '지점', '강수량(mm)']].dropna()
# Line Trace 추가
fig.add_trace(go.Scatter(x=data['날짜'], y=data['강수량(mm)'], mode='lines'))
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', tickformat="%Y-%m-%d")
fig.update_layout(
title=dict(
text="강수량 분석 기본 서울(108) 일자료 기간 : 20250517 ~ 20250615",
)
)
fig.show()
express 를 활용한 다양한 기능
- 라인 색 다르게 표시하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
data_seoul = pd.read_csv('rain_amount.csv', skiprows=6, encoding='utf-8')
data_busan = pd.read_csv('rain_amount_busan.csv', skiprows=6, encoding='utf-8')
data_seoul.columns = data_seoul.columns.str.strip()
data_busan.columns = data_busan.columns.str.strip()
data_seoul['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_seoul = data_seoul[['날짜', '지점', '강수량(mm)']].dropna()
data_busan['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_busan = data_busan[['날짜', '지점', '강수량(mm)']].dropna()
data_seoul['지점'] = '서울'
data_busan['지점'] = '부산'
# 서울과 부산 데이터프레임 합치기(둘의 데이터프레임을 합쳐서 지점에 따라 색을 다르게 보이게 함)
data_combined = pd.concat([data_seoul, data_busan], ignore_index=True)
# Line Trace 추가
fig = px.line(data_combined, x="날짜", y="강수량(mm)", color='지점')
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', tickformat="%Y-%m-%d")
fig.update_layout(
title=dict(
text="강수량 분석 서울과 부산 비교 (20250517 ~ 20250615)",
)
)
fig.show()
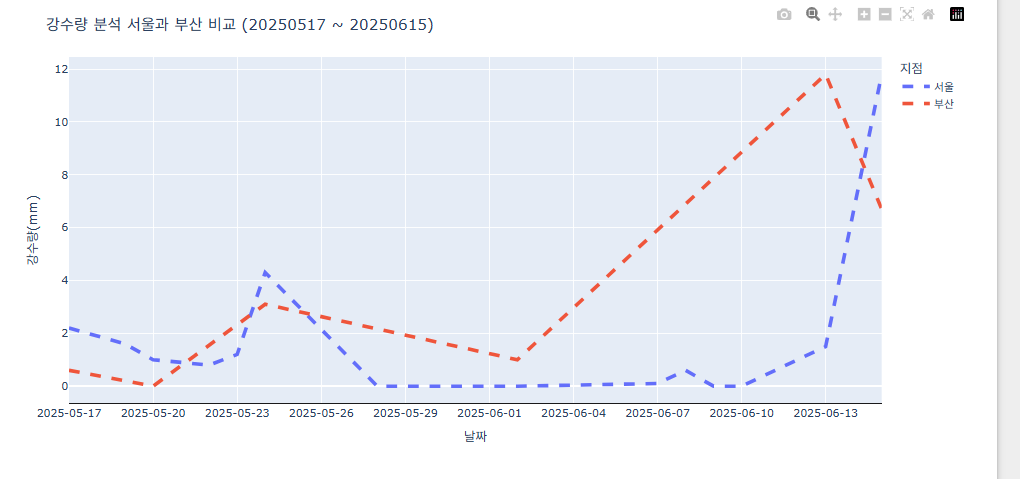
서울, 부산의 강수량을 합쳐 비교해보았다. 선의 색을 지점마다 다르게 표시하였다.
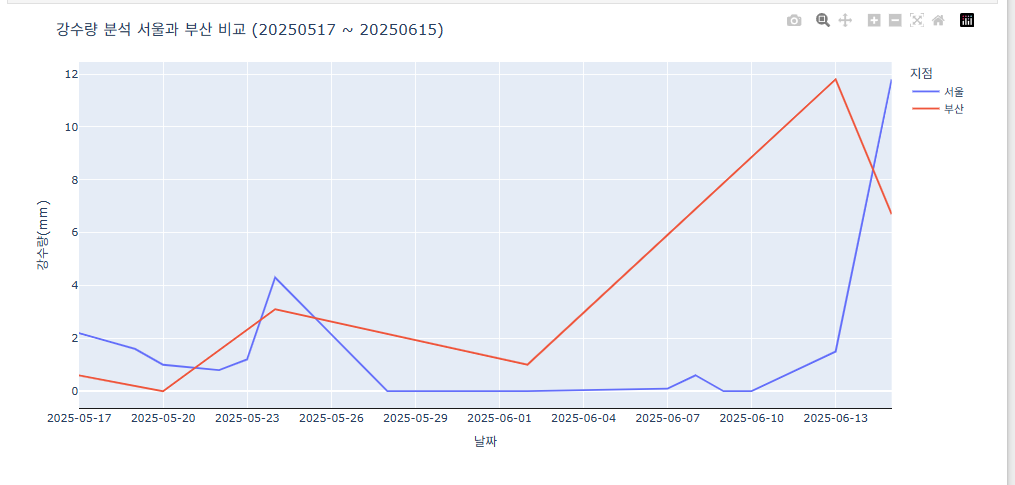
- 마커 같이 표시하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
data_seoul = pd.read_csv('rain_amount.csv', skiprows=6, encoding='utf-8')
data_busan = pd.read_csv('rain_amount_busan.csv', skiprows=6, encoding='utf-8')
data_seoul.columns = data_seoul.columns.str.strip()
data_busan.columns = data_busan.columns.str.strip()
data_seoul['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_seoul = data_seoul[['날짜', '지점', '강수량(mm)']].dropna()
data_busan['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_busan = data_busan[['날짜', '지점', '강수량(mm)']].dropna()
data_seoul['지점'] = '서울'
data_busan['지점'] = '부산'
# 서울과 부산 데이터프레임 합치기(둘의 데이터프레임을 합쳐서 지점에 따라 색을 다르게 보이게 함)
data_combined = pd.concat([data_seoul, data_busan], ignore_index=True)
# Line Trace 추가
fig = px.line(data_combined, x="날짜", y="강수량(mm)", color="지점", markers=True) # Markers를 True로 설정하여 점 표시
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', tickformat="%Y-%m-%d")
fig.update_layout(
title=dict(
text="강수량 분석 서울과 부산 비교 (20250517 ~ 20250615)",
)
)
fig.show()
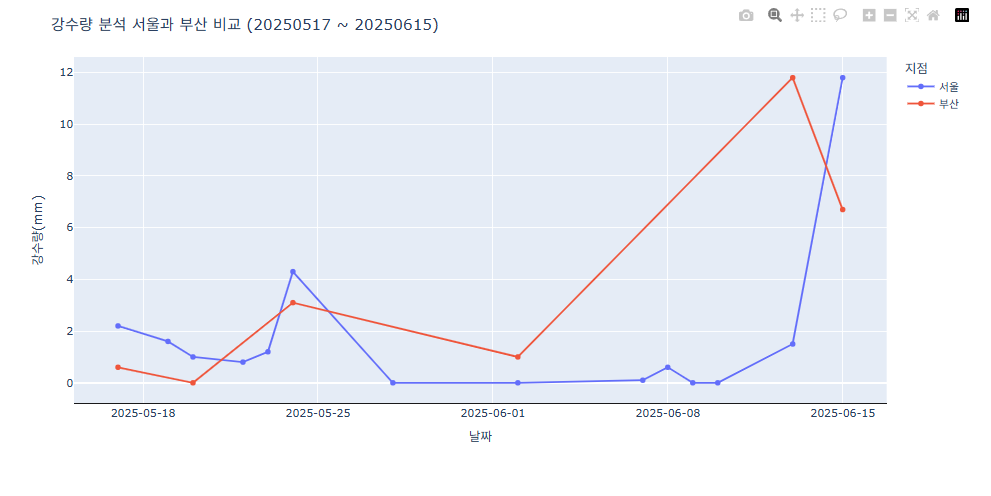
- 마커 스타일 다르게 표시하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
data_seoul = pd.read_csv('rain_amount.csv', skiprows=6, encoding='utf-8')
data_busan = pd.read_csv('rain_amount_busan.csv', skiprows=6, encoding='utf-8')
data_seoul.columns = data_seoul.columns.str.strip()
data_busan.columns = data_busan.columns.str.strip()
data_seoul['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_seoul = data_seoul[['날짜', '지점', '강수량(mm)']].dropna()
data_busan['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_busan = data_busan[['날짜', '지점', '강수량(mm)']].dropna()
data_seoul['지점'] = '서울'
data_busan['지점'] = '부산'
# 서울과 부산 데이터프레임 합치기(둘의 데이터프레임을 합쳐서 지점에 따라 색을 다르게 보이게 함)
data_combined = pd.concat([data_seoul, data_busan], ignore_index=True)
# Line Trace 추가
fig = px.line(data_combined, x="날짜", y="강수량(mm)", markers=True, symbol="지점") # Markers를 True로 설정하여 점 표시
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', tickformat="%Y-%m-%d")
fig.update_layout(
title=dict(
text="강수량 분석 서울과 부산 비교 (20250517 ~ 20250615)",
)
)
fig.show()
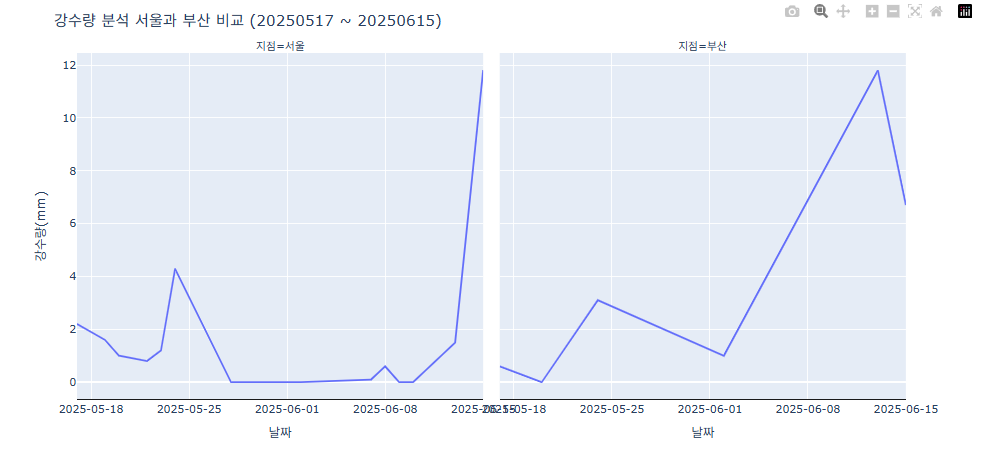
- 여러개로 나눠 그리기 (Facet)
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
data_seoul = pd.read_csv('rain_amount.csv', skiprows=6, encoding='utf-8')
data_busan = pd.read_csv('rain_amount_busan.csv', skiprows=6, encoding='utf-8')
data_seoul.columns = data_seoul.columns.str.strip()
data_busan.columns = data_busan.columns.str.strip()
data_seoul['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_seoul = data_seoul[['날짜', '지점', '강수량(mm)']].dropna()
data_busan['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_busan = data_busan[['날짜', '지점', '강수량(mm)']].dropna()
data_seoul['지점'] = '서울'
data_busan['지점'] = '부산'
# 서울과 부산 데이터프레임 합치기(둘의 데이터프레임을 합쳐서 지점에 따라 색을 다르게 보이게 함)
data_combined = pd.concat([data_seoul, data_busan], ignore_index=True)
# Line Trace 추가
fig = px.line(data_combined, x="날짜", y="강수량(mm)", facet_col="지점") # facet_col을 활용해 두개로 그래프를 나눔
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', tickformat="%Y-%m-%d")
fig.update_layout(
title=dict(
text="강수량 분석 서울과 부산 비교 (20250517 ~ 20250615)",
)
)
fig.show()
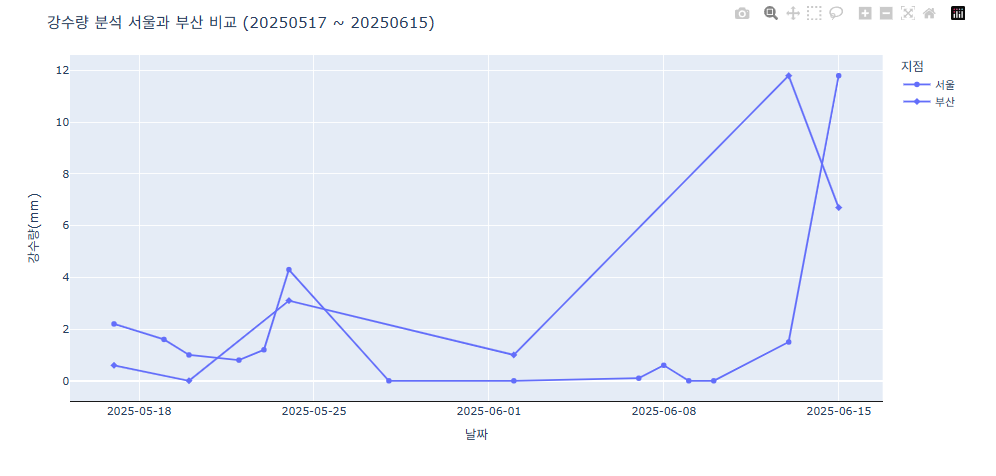
- 라인 스타일 변경하기
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
data_seoul = pd.read_csv('rain_amount.csv', skiprows=6, encoding='utf-8')
data_busan = pd.read_csv('rain_amount_busan.csv', skiprows=6, encoding='utf-8')
data_seoul.columns = data_seoul.columns.str.strip()
data_busan.columns = data_busan.columns.str.strip()
data_seoul['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_seoul = data_seoul[['날짜', '지점', '강수량(mm)']].dropna()
data_busan['날짜'] = pd.to_datetime(data['날짜'], errors='coerce')
data_busan = data_busan[['날짜', '지점', '강수량(mm)']].dropna()
data_seoul['지점'] = '서울'
data_busan['지점'] = '부산'
# 서울과 부산 데이터프레임 합치기(둘의 데이터프레임을 합쳐서 지점에 따라 색을 다르게 보이게 함)
data_combined = pd.concat([data_seoul, data_busan], ignore_index=True)
# Line Trace 추가
fig = px.line(data_combined, x="날짜", y="강수량(mm)", color="지점")
fig.update_traces(line_width=4,line_dash='dash') # line을 dash로 업데이트
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', tickformat="%Y-%m-%d")
fig.update_layout(
title=dict(
text="강수량 분석 서울과 부산 비교 (20250517 ~ 20250615)",
)
)
fig.show()
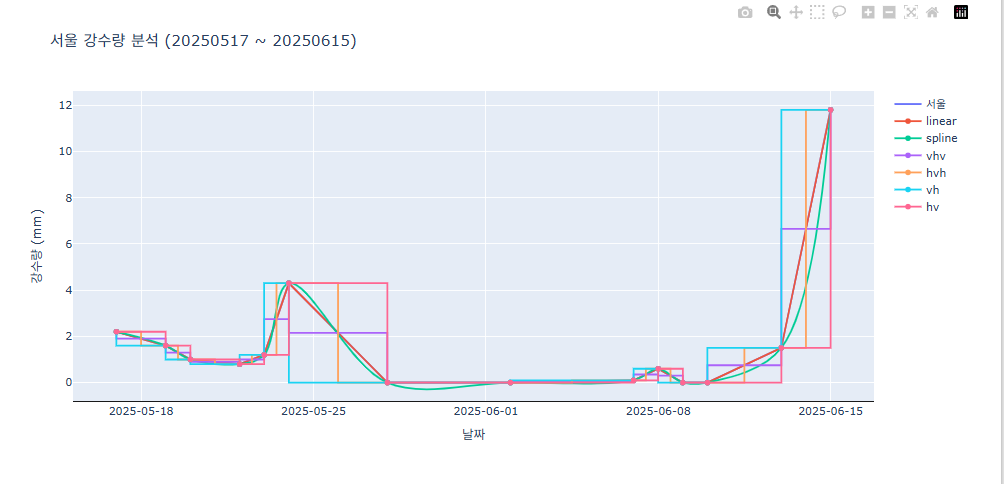
라인 Interpolation 방법 설정하기
go.Scatter(line_shape = 인터폴레이션 방법 설정)
- line_shape
linear : 점과 점 사이를 직선으로 연결합니다.
spline : 점과 점 사이를 곡선으로 연결합니다.
vhv : 점과 점 사이를 두 점의 평균선으로 연결합니다.
hvh : 가장 가까운 점의 값으로 선을 연결합니다.
vh : 다음 점의 위치로 선을 연결합니다.
hv : 이전 선의 위치로 선을 연결합니다
import pandas as pd
import plotly.graph_objects as go
data_seoul = pd.read_csv('rain_amount.csv', skiprows=6, encoding='utf-8')
data_seoul.columns = data_seoul.columns.str.strip()
data_seoul['날짜'] = pd.to_datetime(data_seoul['날짜'], errors='coerce')
data_seoul = data_seoul[['날짜', '지점', '강수량(mm)']].dropna()
data_seoul['지점'] = '서울'
fig = go.Figure()
fig.add_trace(go.Scatter(x=data_seoul['날짜'], y=data_seoul['강수량(mm)'], mode='lines', name='서울',
line_shape='linear'))
fig.add_trace(go.Scatter(x=data_seoul['날짜'], y=data_seoul['강수량(mm)'], name='linear', line_shape='linear'))
fig.add_trace(go.Scatter(x=data_seoul['날짜'], y=data_seoul['강수량(mm)'], name='spline', line_shape='spline'))
fig.add_trace(go.Scatter(x=data_seoul['날짜'], y=data_seoul['강수량(mm)'], name='vhv', line_shape='vhv'))
fig.add_trace(go.Scatter(x=data_seoul['날짜'], y=data_seoul['강수량(mm)'], name='hvh', line_shape='hvh'))
fig.add_trace(go.Scatter(x=data_seoul['날짜'], y=data_seoul['강수량(mm)'], name='vh', line_shape='vh'))
fig.add_trace(go.Scatter(x=data_seoul['날짜'], y=data_seoul['강수량(mm)'], name='hv', line_shape='hv'))
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', tickformat="%Y-%m-%d")
fig.update_layout(
title="서울 강수량 분석 (20250517 ~ 20250615)",
xaxis_title="날짜",
yaxis_title="강수량 (mm)",
)
fig.show()
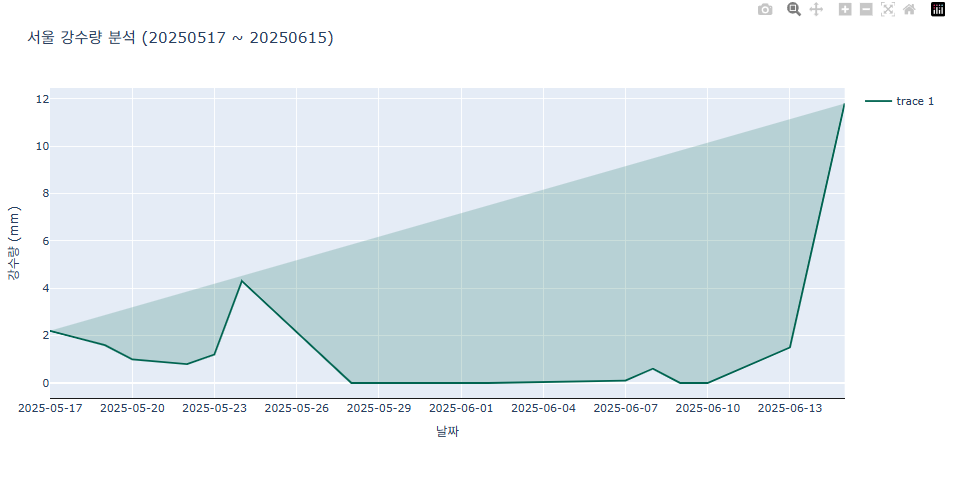
선과 선 사이 채우기
선과 선 사이를 채우면 순대 모양의 마치 오차범위를 내는 듯한 효과를 낼 수 있습니다.
go.Scatter(x = 범위 둘례 X 좌표,
y = 범위 둘례 Y 좌표,
fill = 'toself'
fillcolor = 범위 색
line_color = 테두리 색)예제)
import pandas as pd
import plotly.graph_objects as go
data_seoul = pd.read_csv('rain_amount.csv', skiprows=6, encoding='utf-8')
data_seoul.columns = data_seoul.columns.str.strip()
data_seoul['날짜'] = pd.to_datetime(data_seoul['날짜'], errors='coerce')
data_seoul = data_seoul[['날짜', '지점', '강수량(mm)']].dropna()
data_seoul['지점'] = '서울'
fig = go.Figure()
# 영역 채우기
fig.add_trace(go.Scatter(
x=data_seoul['날짜'],
y=data_seoul['강수량(mm)'],
fill='toself',
fillcolor='rgba(0,100,80,0.2)',
line_color='rgba(255,255,255,0)',
showlegend=False,
))
# 중간에 선 그리기
fig.add_trace(go.Scatter(
x=data_seoul['날짜'], y=data_seoul['강수량(mm)'],
line_color='rgb(0,100,80)',
))
fig.update_traces(mode='lines')
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', tickformat="%Y-%m-%d")
fig.update_layout(
title="서울 강수량 분석 (20250517 ~ 20250615)",
xaxis_title="날짜",
yaxis_title="강수량 (mm)",
)
fig.show()

안녕하세요 게임개발을 공부하고 있는 돼지인간 입니다.