선형/비선형추세선 그래프
추세선이란 산점도에 나타난 자료의 관계 또는 흐름을 통계적 기법으로 선형 또는 비선형의 선으로 표현한 선 입니다. 보통 경향파악, 미래예측에 사용되며 특히 주식 차트 분석 분야에서 주로 사용됩니다.
패키지 설치
추세선 기능을 활용하기 위해선 statsmodels 패키지를 추가 설치해야 합니다.
pip install statsmodels기본 사용방법
추세선은 Scatter Plot과 함께 사용됩니다.
import plotly.express as px
df = px.data.tips()
# 그래프 그리기
fig = px.scatter(df, x="total_bill", y="tip", trendline="ols") # trendline은 추세선을 의미한다.
fig.show()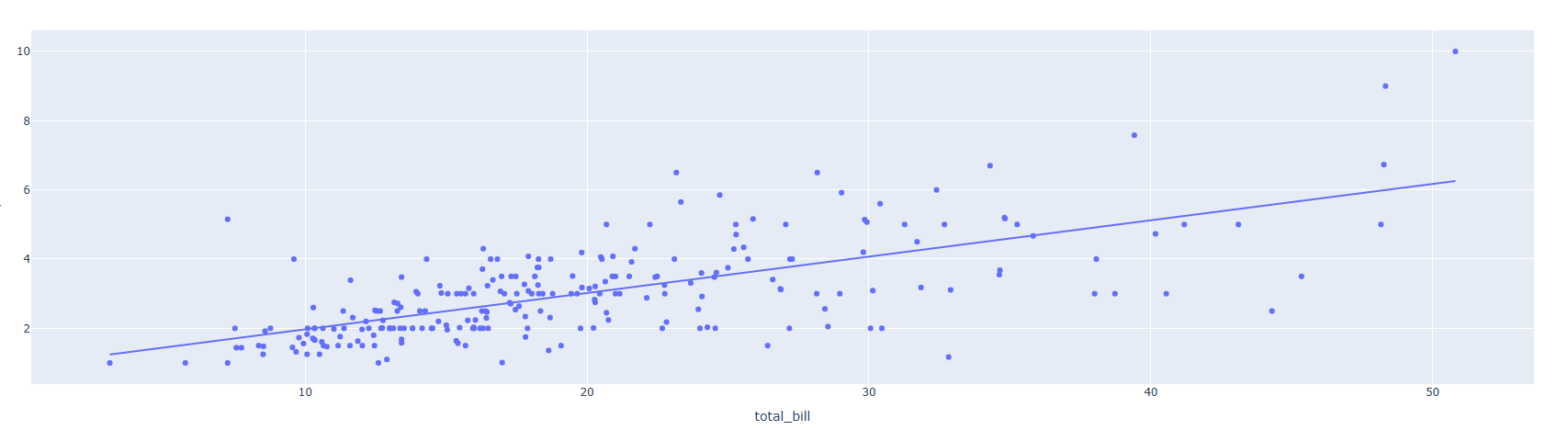
- Color 를 통해 범주형 데이터를 분류하면 각 범주 별 추세선을 각각 추가합니다.
import plotly.express as px
df = px.data.tips()
# 그래프 그리기
fig = px.scatter(df, x="total_bill", y="tip", color="sex", trendline="ols") # trendline은 추세선을 의미한다.
fig.show()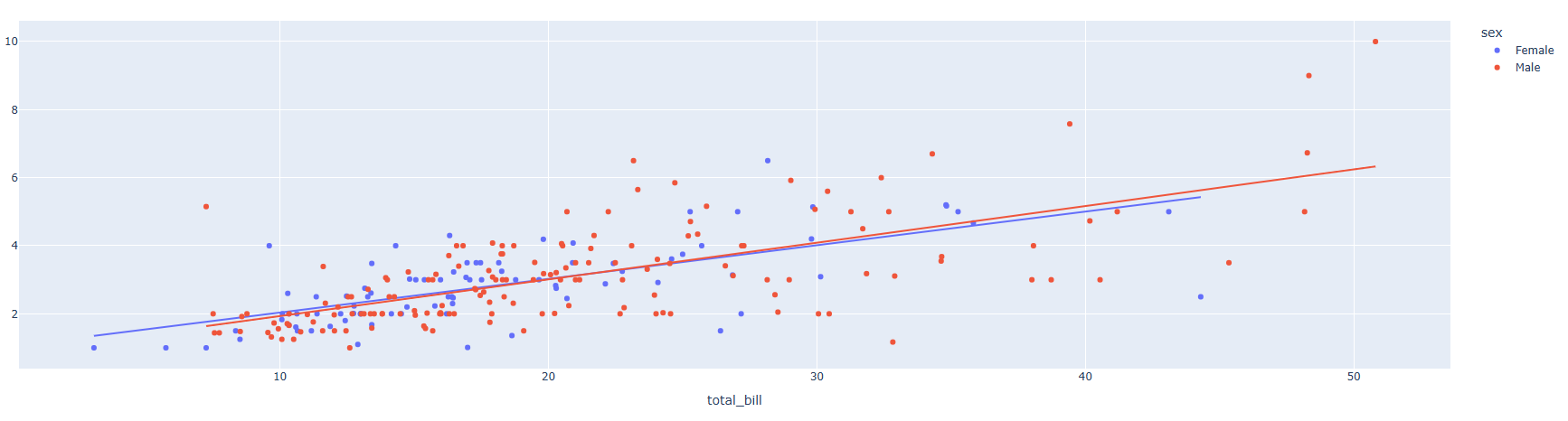
- 만약 Color로 범주형 데이터를 분류하고 추세선은 전체 데이터를 활용해서 구분하고 싶다면 trendline_scope="overall" 로 지정합니다.
import plotly.express as px
df = px.data.tips()
# 그래프 그리기
fig = px.scatter(df, x="total_bill", y="tip", color="sex", trendline="ols", trendline_scope="overall") # trendline은 추세선을 의미한다.
fig.show()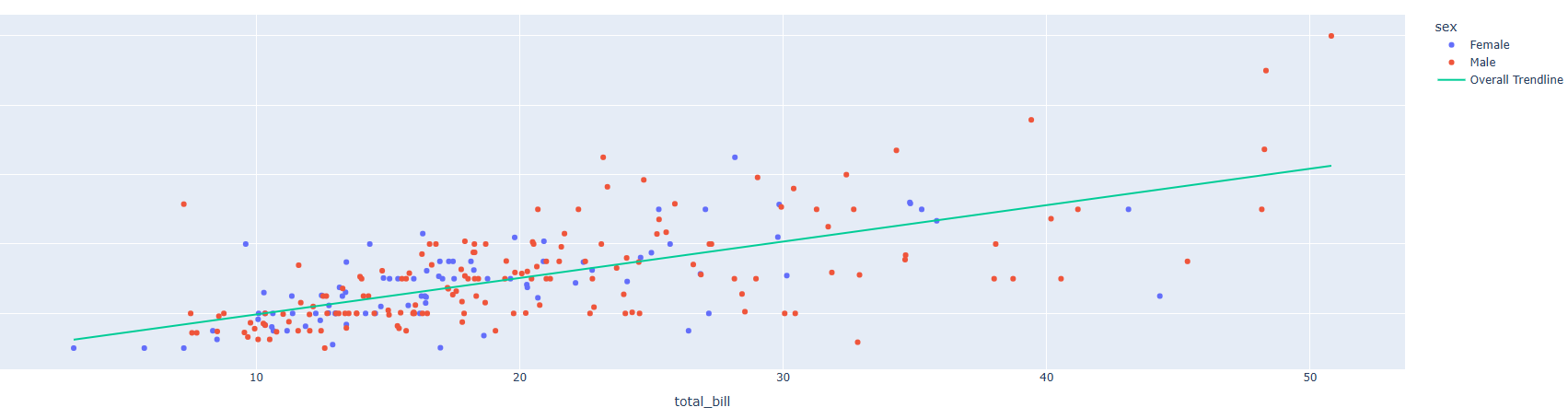
추세선 결과 Table 보기
results = px.get_trendline_results(fig)
results.px_fit_results.iloc[0].summary()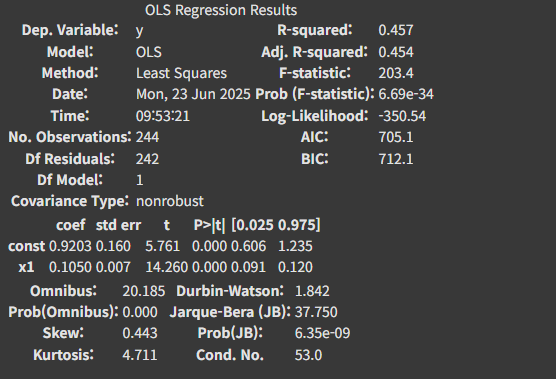
OLS 로그 함수로 피팅하기
import plotly.express as px
#데이터 불어오기
df = px.data.gapminder(year=2007)
#그래프 그리기
fig = px.scatter(df, x="gdpPercap", y="lifeExp", trendline="ols", trendline_options=dict(log_x=True))
fig.show()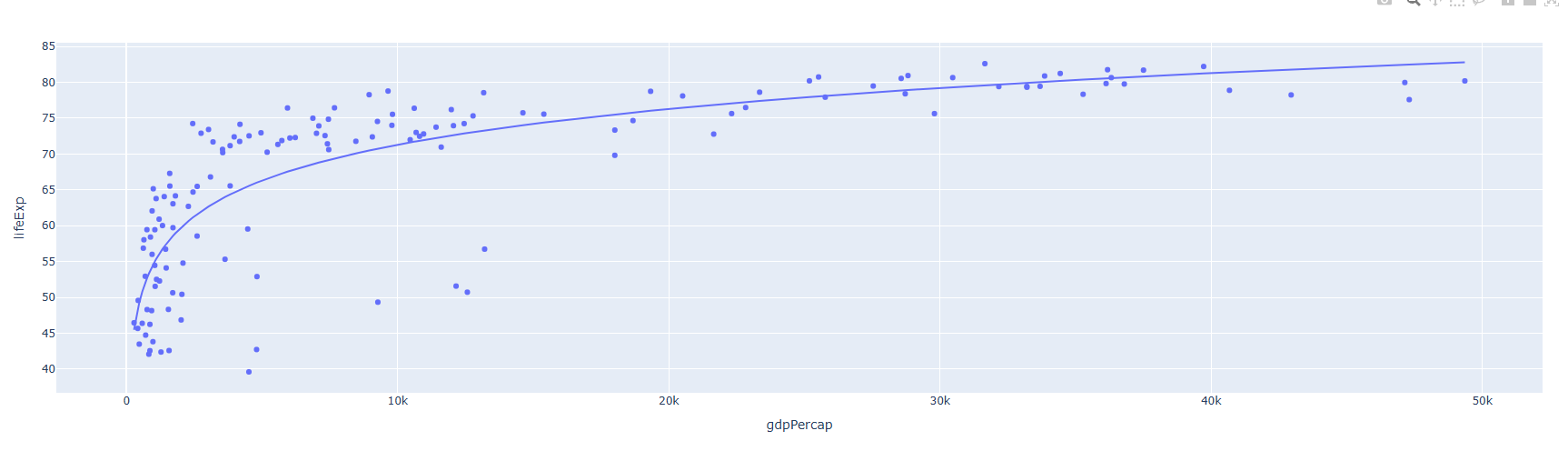
Locally Weighted Scatterplot Smoothing (LOWESS)
import plotly.express as px
#데이터 불어오기
df = px.data.gapminder(year=2007)
#그래프 그리기
fig = px.scatter(df, x="gdpPercap", y="lifeExp", trendline="lowess")
fig.show()
위에 그래프는 너무 추세가 뭉게져서 나온 느낌입니다. 이럴경우 LOWESS 의 smoothing 정도를 변경하여 수정이 가능합니다.
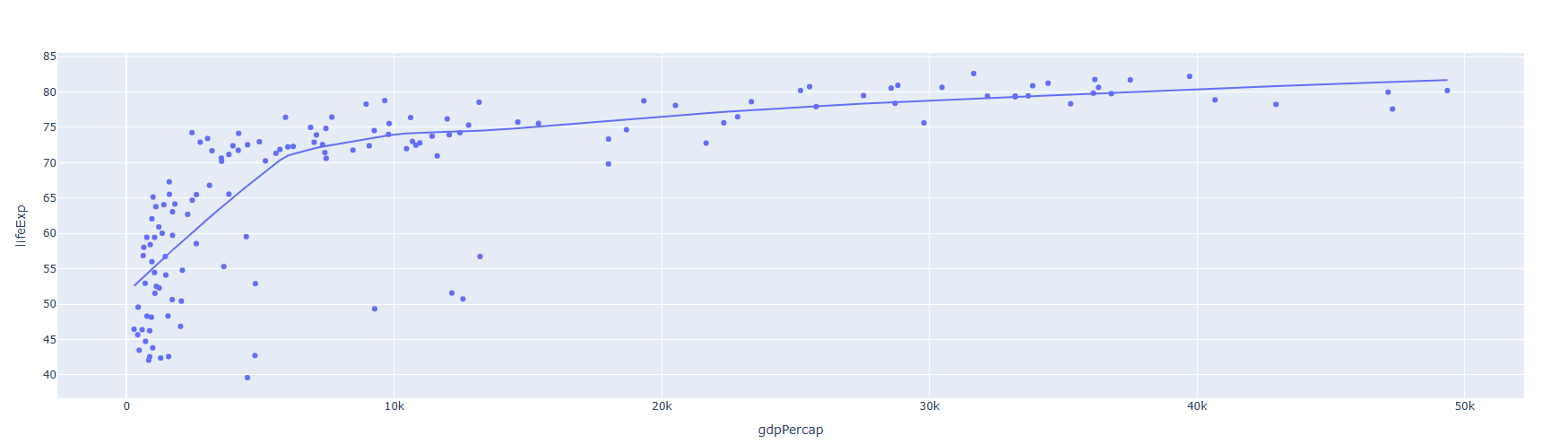
trendline_options=dict(frac=0.1)위의 줄을 추가하는 것으로 수정 가능
이동 평균선
- 기본 이동 평균선
import plotly.express as px
# 데이터 불러오기
df = px.data.stocks(datetimes=True)
fig = px.scatter(df, x="date", y="GOOG", trendline="rolling", trendline_options=dict(window=5))
fig.show()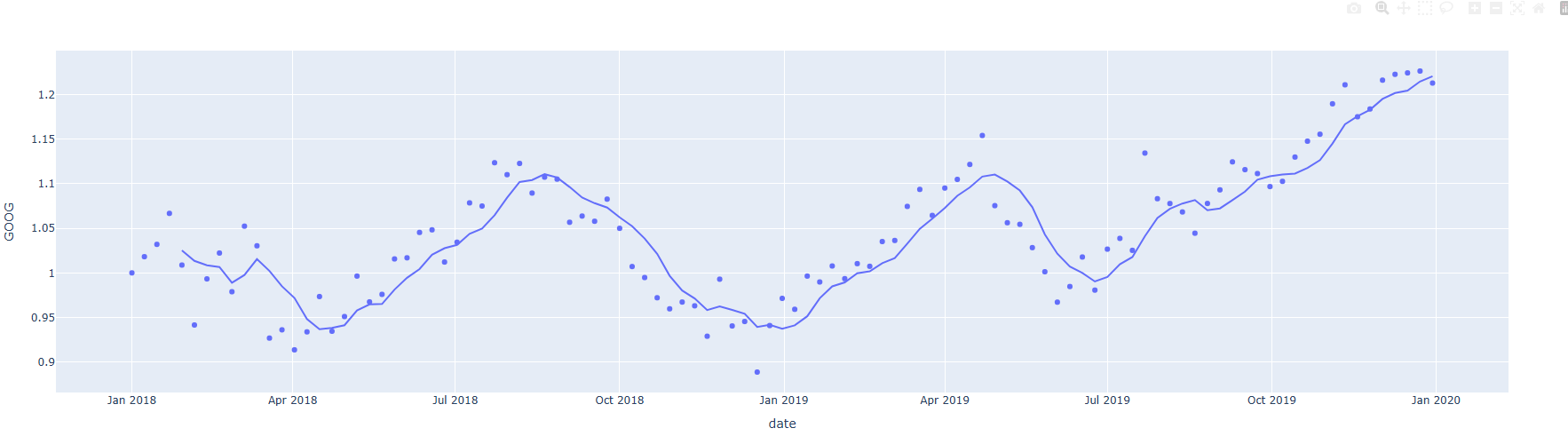
- exponentially weighted 이동평균선
import plotly.express as px
# 데이터 불러오기
df = px.data.stocks(datetimes=True)
fig = px.scatter(df, x="date", y="GOOG", trendline="ewm", trendline_options=dict(halflife=2))
fig.show()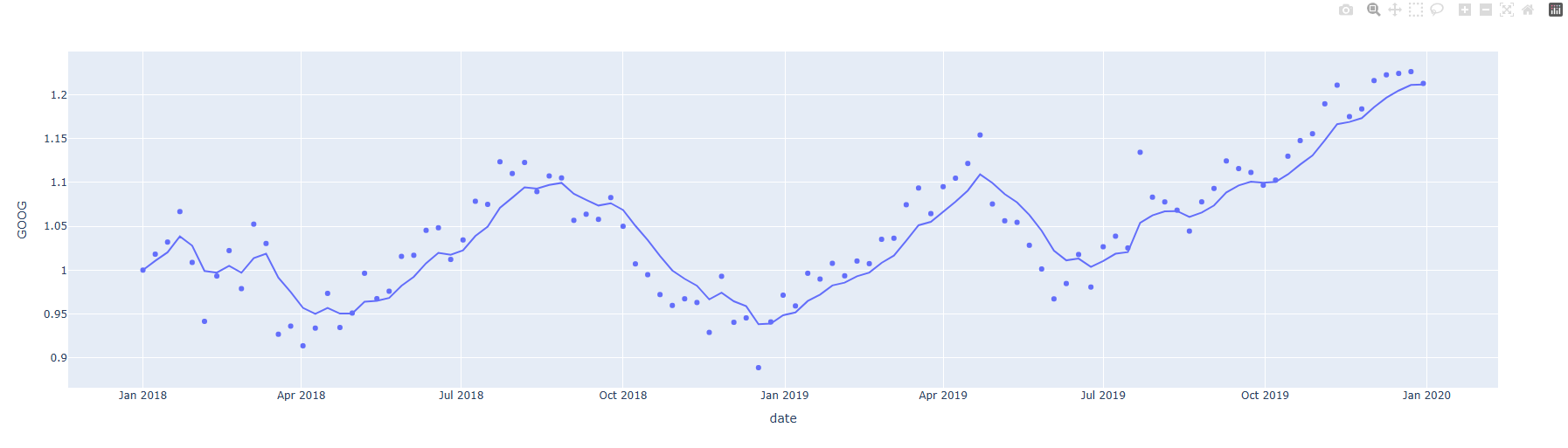
- Cumulative 이동 평균선
import plotly.express as px
# 데이터 불러오기
df = px.data.stocks(datetimes=True)
fig = px.scatter(df, x="date", y="GOOG", trendline="expanding")
fig.show()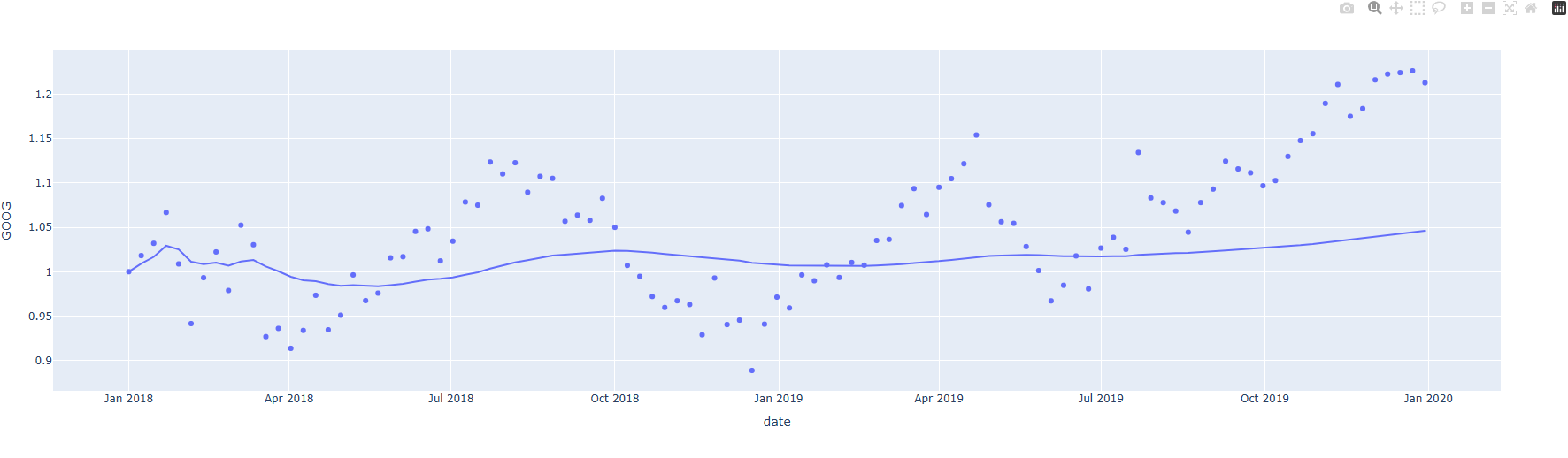
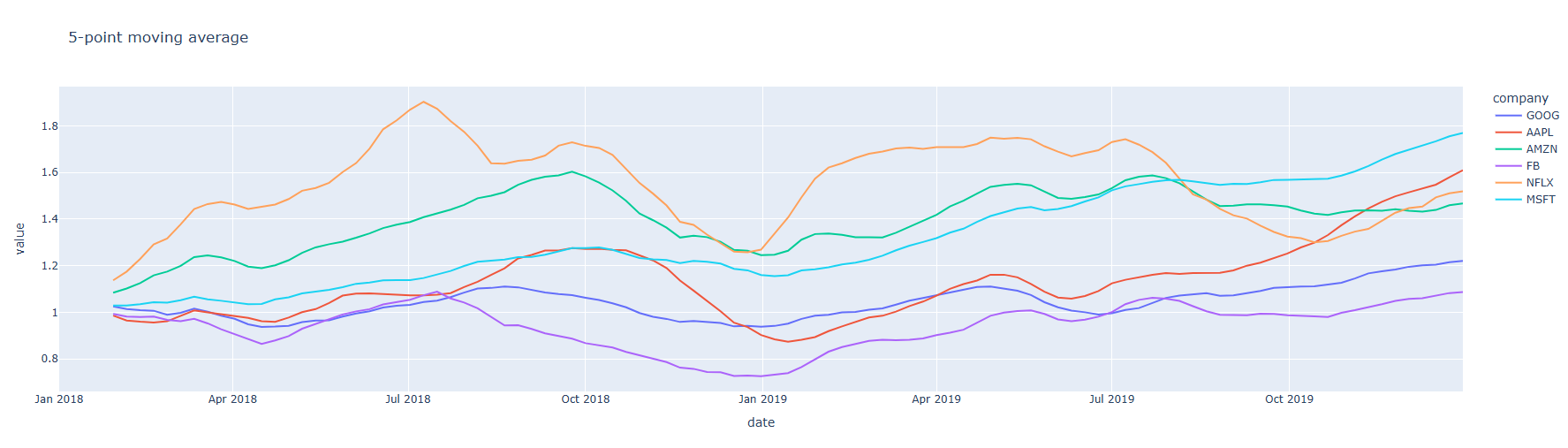
추세선만 그리기
import plotly.express as px
#데이터 불러오기
df = px.data.stocks(indexed=True, datetimes=True)
# 그래프 그리기
fig = px.scatter(df, trendline="rolling", trendline_options=dict(window=5),
title="5-point moving average")
# 라인만 남기기
fig.data = [t for t in fig.data if t.mode == "lines"]
fig.update_traces(showlegend=True)
fig.show()
주변확률분포 그래프
주변 분포(Marginal Distribution) 그래프란 Main Plot 위 또는 오른쪽에 있는 1차원의 그래프로 데이터의 분포를 보여줍니다. Plotly 에서는 express 의 Scatterplot, Histogram 에 내장되어 있습니다.
Scatter Plot 주변 분포 사용방법
import plotly.express as px
import pandas as pd
# 데이터 불러오기
df = pd.read_csv('money.csv', encoding='utf-8')
df.columns = df.columns.str.strip()
# 그래프 그리기
fig = px.scatter(df,
x=["임금 (상위25퍼센트)","임금 중위값", "임금 (하위25퍼센트)"],
y="직업명",
marginal_x="histogram"
)
fig.update_layout(
title=dict(
text="직업별 임금(상위, 중위, 하위) 값"
)
)
fig.show()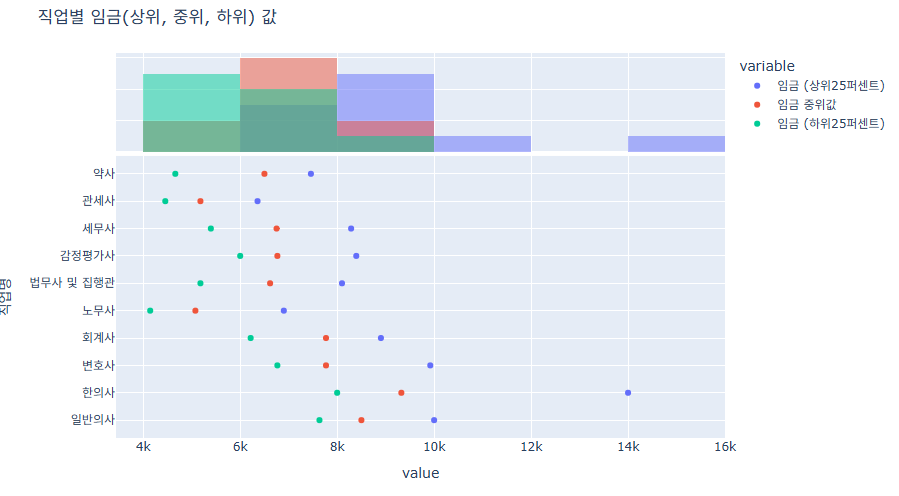
histogram 사용 주변 분포 사용방법 및 COLOR사용
import plotly.express as px
import pandas as pd
# 데이터 불러오기
df = pd.read_csv('money.csv', encoding='utf-8')
df.columns = df.columns.str.strip()
# 그래프 그리기
fig = px.histogram(df,
x="직업명",
y="임금 (상위25퍼센트)",
marginal="box"
)
fig.update_layout(
title=dict(
text="직업별 임금(상위, 중위, 하위) 값"
)
)
fig.show()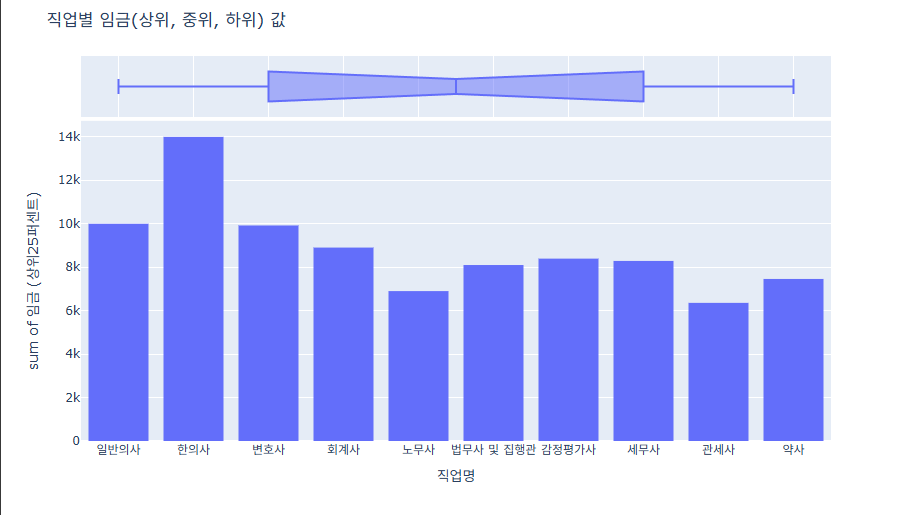
density_heatmap 사용 주변 분포 사용방법
import plotly.express as px
import pandas as pd
# 데이터 불러오기
df = pd.read_csv('money.csv', encoding='utf-8')
df.columns = df.columns.str.strip()
# 그래프 그리기
fig = px.density_heatmap(df,
x="임금 (하위25퍼센트)",
y="임금 (상위25퍼센트)",
marginal_x="box", marginal_y="violin"
)
fig.update_layout(
title=dict(
text="직업별 임금(상위, 중위, 하위) 값"
)
)
fig.show()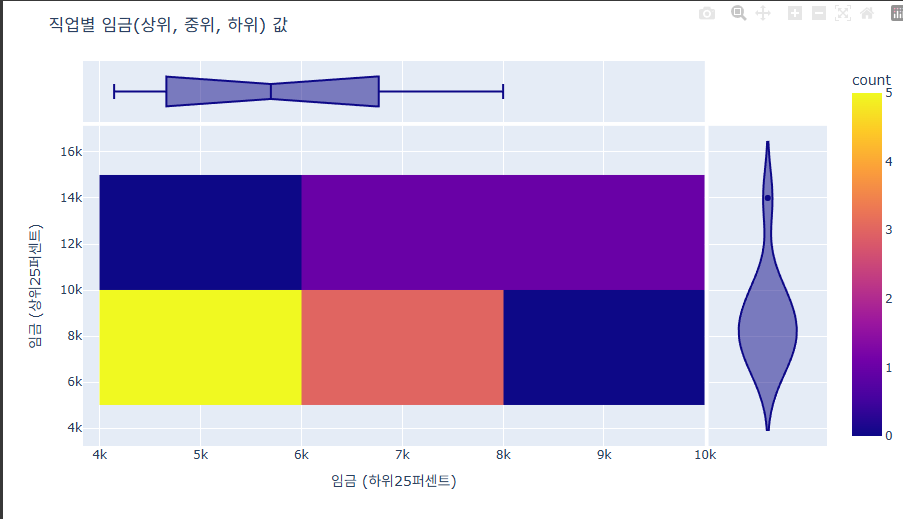
주변 분포 그래프 여러개로 나눠 그리기(Facet)
import plotly.express as px
# 데이터 불러오기
df = px.data.iris()
# 그래프 그리기
fig = px.scatter(df, x="total_bill", y="tip", color="sex", facet_col="day", marginal_x="box")
fig.show()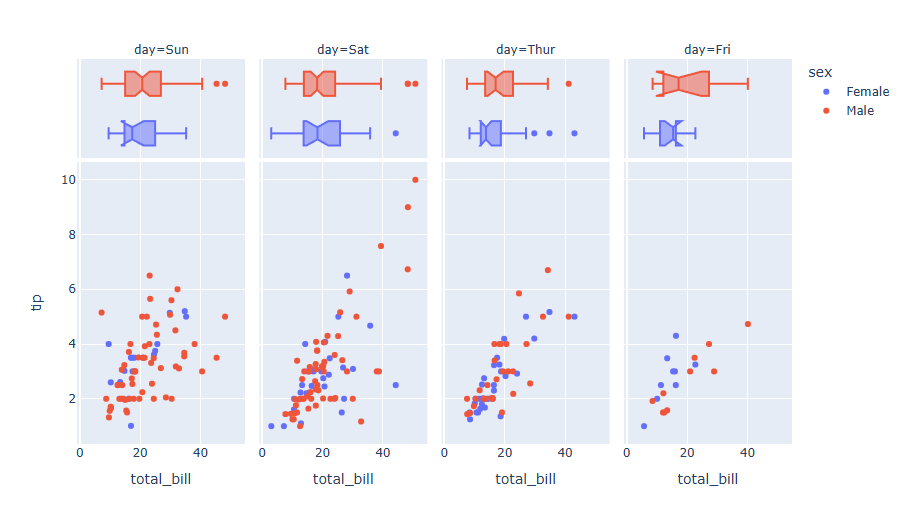
Candlestick Chart
Candlestick 은 총 4개의 값으로 구성됩니다. - 시가(Open) : 장이 열리고 최초가격 - 종가(Close) : 장이 마감하고 마지막으로 끝난 가격 - 고가(High) : 장이 열리고 나서 가장 높았던 가격 - 저가 (Low) : 장이 열리고 나서 가장 낮은 가격
기본 사용 방법
fig.add_trace(go.Candlestick(
x=날짜 리스트,
open=시가 리스트,
high=고가 리스트,
low=저가 리스트,
close=종가 리스트))금 시세 예제
import plotly.express as px
import pandas as pd
import plotly.graph_objects as go
# 데이터 불러오기
df = pd.read_csv('goldstocK.csv', encoding='utf-8')
fig = go.Figure()
fig.update_layout(
title=dict(
text="금 시세"
)
)
fig.add_trace(go.Candlestick(x=df['Date'],open=df['Open'],high=df['High'],low=df['Low'],close=df['Close']))
fig.show()
fig.show()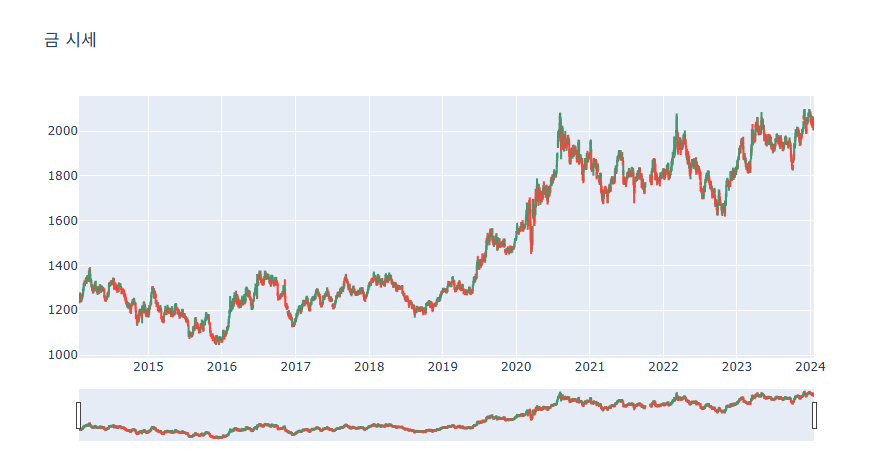
Rangeslider 삭제하기, Candlestick 스타일 커스터마이징하기
import plotly.express as px
import pandas as pd
import plotly.graph_objects as go
# 데이터 불러오기
df = pd.read_csv('goldstocK.csv', encoding='utf-8')
fig = go.Figure()
fig.update_layout(
title=dict(
text="금 시세"
)
)
fig.add_trace(go.Candlestick(x=df['Date'],open=df['Open'],high=df['High'],low=df['Low'],close=df['Close']))
fig.update_layout(xaxis_rangeslider_visible=False) # Rangeslider 삭제
fig.update_traces(increasing_line_color= 'cyan', decreasing_line_color= 'gray') # 꾸미기
fig.show()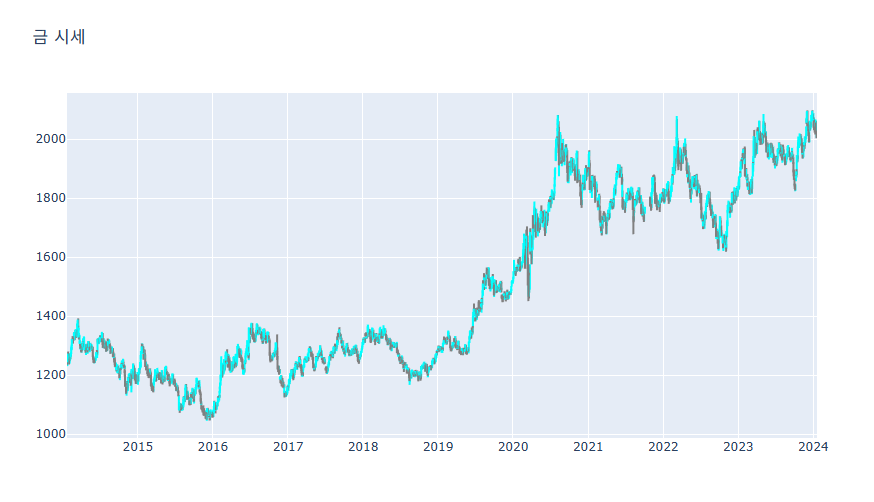
특정 날짜만 그리기
import plotly.express as px
import pandas as pd
import plotly.graph_objects as go
# 데이터 불러오기
df = pd.read_csv('goldstocK.csv', encoding='utf-8')
df = df.loc[df['Date'] > '2024-01-05']
fig = go.Figure()
fig.update_layout(
title=dict(
text="2024-01-05 이후 금 시세"
)
)
fig.add_trace(go.Candlestick(x=df['Date'],open=df['Open'],high=df['High'],low=df['Low'],close=df['Close']))
fig.show()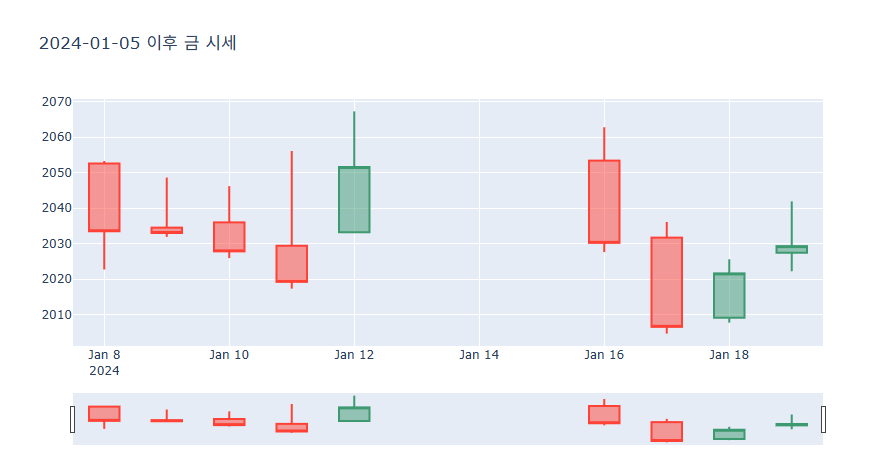

안녕하세요 게임개발을 공부하고 있는 돼지인간 입니다.