최대/최소 (max / min)
min / max 메서드는 행/열 의 최대값, 최소값을 구하는 메서드 입니다.
사용법
df.max(axis=None, skipna=None, level=None, numeric_only=None, kwargs)
df.min(axis=None, skipna=None, level=None, numeric_only=None, kwargs)
axis: {0 : index / 1 : columns} 계산의 기준이 될 축입니다.
skipna: 결측치를 무시할지 여부입니다.
level: Multi Index의 경우 연산을 수행할 레벨입니다.
numeric_only: 숫자, 소수, 부울만 이용할지 여부입니다.
kwargs: 함수에 전달할 추가 키워드입니다.
먼저 기본적인 사용법 예시를 위해 Multi Index 객체를 생성하겠습니다.
[N,T,F]=[np.NaN,True,False]
idx = [['IDX1','IDX1','IDX2','IDX2'],['row1','row2','row3','row4']]
col = [['COL1','COL1','COL2','COL2'],['val1','val2','val3','val4']]
data = [[N,13,3,4],[5,7,10,8],[15,6,N,3],[2,14,9,1]]
df = pd.DataFrame(data,idx,col)
print(df)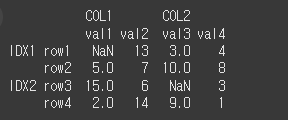
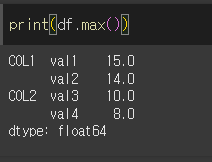
기본적인 사용법(+axis)
기본적으로 df.max( ) / df.min( )를 사용할 경우 모든 행/열에 대해서 최대/최소 값을 찾습니다.
axis를 설정해 줄 경우 축을 지정할 수 있습니다.

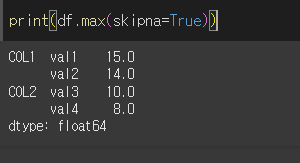
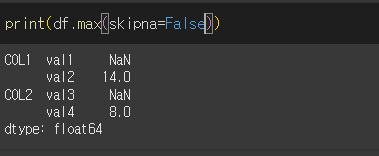
skipna인수의 사용
skipna인수를 사용할 경우 계산에 대해서 결측치를 포함하거나 제외시킬 수 있습니다.
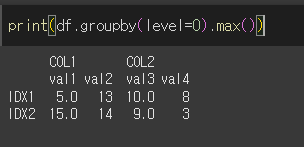
level의 설정
Multi Index의 경우 연산을 수행할 level을 지정할 수 있습니다.
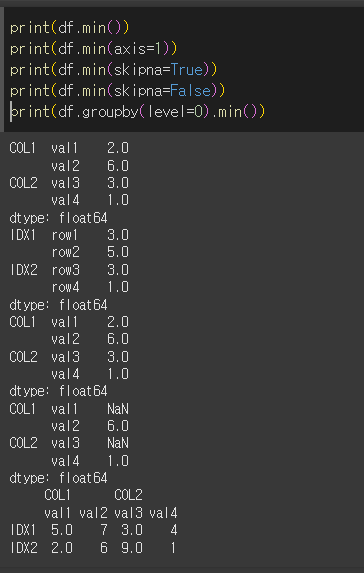
min메서드의 경우
이 아래는 위 예시와 동일하게 min메서드를 수행한 경우 입니다.
평균 (mean)
mean메서드는 행/열의 값들의 평균을 구하는 메서드입니다.
사용법
df.mean(axis=None, skipna=None, level=None, numeric_only=None, kwargs)
axis : {0 : index / 1 : columns} 계산의 기준이 될 축입니다.
skipna : 결측치를 무시할지 여부입니다.
level : Multi Index의 경우 연산을 수행할 레벨입니다.
numeric_only : 숫자, 소수, 부울만 이용할지 여부입니다.
kwargs : 함수에 전달할 추가 키워드입니다.
먼저 기본적인 사용법 예시를 위해 Multi Index 객체를 생성하겠습니다.
idx = [['IDX1','IDX1','IDX2','IDX2'],['row1','row2','row3','row4']]
col = [['COL1','COL1','COL2','COL2'],['val1','val2','val3','val4']]
data = [[N,13,3,4],[5,7,10,8],[15,6,N,3],[2,14,9,1]]
df = pd.DataFrame(data,idx,col)
print(df)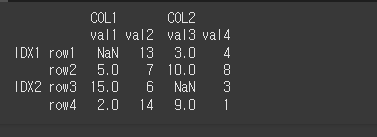
기본적인 사용법(+axis)
기본적으로 mean을 그대로 사용할 경우 모든 행/열에 대해서 연산을 수행합니다.
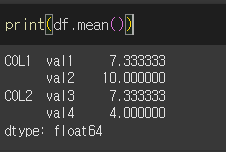
axis 인수를 이용하여 대상 축을 지정할 수 있습니다.
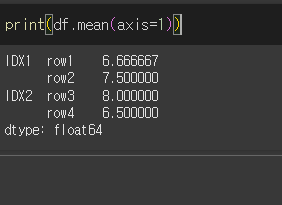
skipna인수의 사용
skipna인수를 이용하여 결측치를 무시할지 정할 수 있습니다.
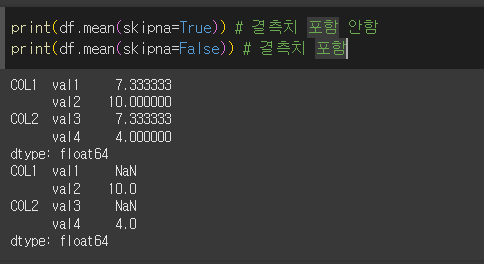
level인수의 사용
Multi Index의 경우 대상 레벨을 지정할 수 있습니다.
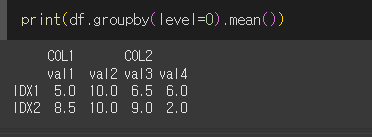
중앙값 (median)
median메서드는 행/열의 값들의 중앙값을 구하는 메서드입니다.
만약 수의 갯수가 짝수이면 중앙값 두 값의 평균값을 반환합니다.
사용법
df.median(axis=None, skipna=None, level=None, numeric_only=None, kwargs)
axis: {0 : index / 1 : columns} 계산의 기준이 될 축입니다.
skipna: 결측치를 무시할지 여부입니다.
level: Multi Index의 경우 연산을 수행할 레벨입니다.
numeric_only: 숫자, 소수, 부울만 이용할지 여부입니다.
kwargs: 함수에 전달할 추가 키워드입니다.
먼저 기본적인 사용법 예시를 위해 Multi Index 객체를 생성하겠습니다.
[N,T,F]=[np.nan,True,False]
idx = [['IDX1','IDX1','IDX2','IDX2'],['row1','row2','row3','row4']]
col = [['COL1','COL1','COL2','COL2'],['val1','val2','val3','val4']]
data = [[N,13,3,4],[5,7,10,8],[15,6,N,3],[2,14,9,1]]
df = pd.DataFrame(data,idx,col)
print(df)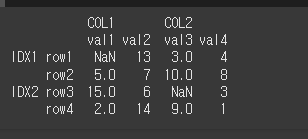
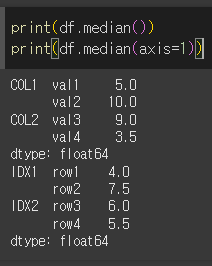
기본적인 사용법(+axis)
기본적으로 median을 그대로 사용할 경우 모든 행/열에 대해서 연산을 수행합니다.
만약 수의 갯수가 짝수이면 중앙값 두 값의 평균값을 반환합니다.
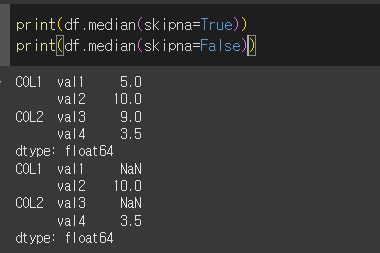
skipna인수의 사용
skipna인수를 이용하여 결측치를 무시할지 정할 수 있습니다.
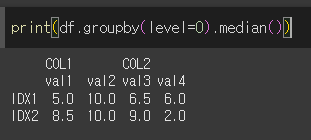
level인수의 사용
Multi Index의 경우 대상 레벨을 지정할 수 있습니다.
최빈값 (mode)
mode메서드는 대상 행/열의 최빈값을 구하는 메서드입니다.
최빈값이 여러개일 경우 모두 표시합니다.
사용법
df.mode(axis=0, numeric_only=False, dropna=True)
axis: {0 : index / 1 : columns} 최빈값을 구할 축 입니다.
numeric_only: True일 경우 숫자, 소수, 부울값만 있는 열에대해서만 연산을 수행합니다.
dropna: 결측치를 계산에서 제외할지 여부입니다. False일 경우 결측치도 계산에 포함됩니다.
먼저 기본적인 사용법 예시를 위해 4x4짜리 객체를 생성하겠습니다.
[N,T,F]=[np.nan,True,False]
idx = ['row1','row2','row3','row4']
col = ['col1','col2','col3','col4']
data = [['A',2,'x',N],['B',2,'y',N],['C',1,'y',1],['A',N,'z',3]]
df = pd.DataFrame(data,idx,col)
print(df)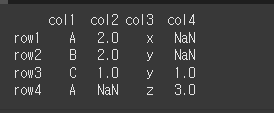
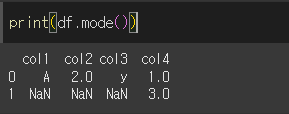
기본적인 사용법
mode메서드를 사용하면 각 열에 대해서 최빈값이 인덱스 0에 출력됩니다.
만약 최빈값이 여러개일 경우 갯수만큼 인덱스가 생성되어 출력됩니다.
이 때, 최빈값 이외의 값은 NaN을 출력합니다.
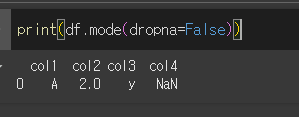
dropna인수의 사용
기본적으로 결측치는 최빈값 계산에서 제외됩니다. dropna= True로 할 경우 결측치도 계산에 포함되며,
결측치가 제일 많을 경우 최빈값은 결측치가 됩니다.
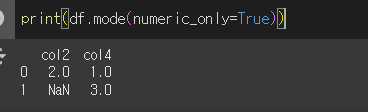
numeric_only인수의 사용
numeric_only인수가 True인 경우 숫자 or bool형태가 아닌 자료형을 갖는 열은 계산에서 제외됩니다.
표준편차 (std)
편차란?
데이터가 평균에서 얼마나 떨어져 있는지를 나타내는 것
표준편차란?
(편차를 제곱하여 음수 값을 양수로 바꾸어 데이터가 평균과 얼마나 떨어져있는지 확인함.)
분산 값에 루트를 씌워 다시 원래 데이터 단위로 돌려놓는 것
std 메서드는 행/열에 대한 표본표준편차를 구하는 메서드입니다.
사용법
df.std(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, kwargs)
axis: 표본표준편차를 구할 축을 지정합니다.
skipna: 결측치를 무시할지 여부입니다.
level: Multi Index의 경우 대상 레벨을 지정할 수 있습니다.
ddof: 표본표준편차 계산의 분모가되는 자유도를 지정합니다. 산식은 n - ddof값으로 기본값은 n-1입니다.
numeric_only: 숫자, 소수, bool로 구성된 열만 대상으로할지 여부입니다.
kwargs: 함수의 경우에 추가적으로 적용할 키워드입니다.
먼저 기본적인 사용법 예시를 위해 4x4짜리 Multi Index 객체를 생성하겠습니다.
[N,T,F]=[np.nan,True,False]
idx = [['IDX1','IDX1','IDX2','IDX2'],['row1','row2','row3','row4']]
col = ['col1','col2','col3','col4']
data = [[1,5,7,13],[5,2,19,1],[13,6,4,12],[8,N,0,8]]
df = pd.DataFrame(data,idx,col)
print(df)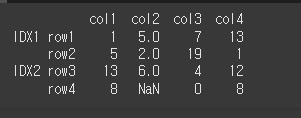
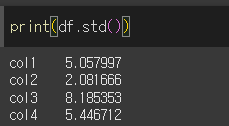
기본적인 사용법
인수입력 없이 std메서드를 사용할 경우 각 열의 요소들의 표본표준편차를 계산합니다.
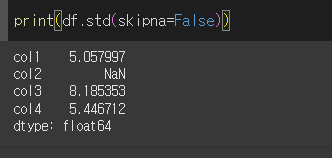
skipna인수의 사용
skipna=False인 경우 결측값이 포함된 경우 NaN을 출력합니다.
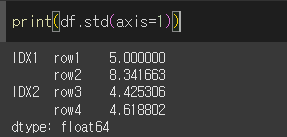
axis인수의 사용
axis 인수를 통해 계산의 대상이 될 축을 지정할 수 있습니다.
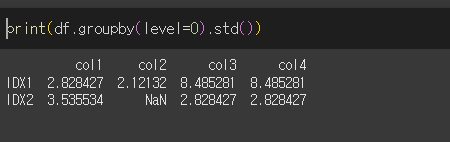
level인수의 사용
Multi Index의 경우 level 인수를 이용해 레벨을 지정할 수 있습니다.
분산 (var)
var 메서드는 행/열에 대한 불편향분산를 구하는 메서드입니다.
사용법
df.var(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, kwargs)
axis: 불편향분산을 구할 축을 지정합니다.
skipna: 결측치를 무시할지 여부입니다.
level: Multi Index의 경우 대상 레벨을 지정할 수 있습니다.
ddof: 불편향분산 계산의 분모가되는 자유도를 지정합니다. 산식은 n - ddof값으로 기본값은 n-1입니다.
numeric_only: 숫자, 소수, bool로 구성된 열만 대상으로할지 여부입니다.
kwargs: 함수의 경우에 추가적으로 적용할 키워드입니다.
먼저 기본적인 사용법 예시를 위해 4x4짜리 Multi Index 객체를 생성하겠습니다.
[N,T,F]=[np.NaN,True,False]
idx = [['IDX1','IDX1','IDX2','IDX2'],['row1','row2','row3','row4']]
col = ['col1','col2','col3','col4']
data = [[1,5,7,13],[5,2,19,1],[13,6,4,12],[8,N,0,8]]
df = pd.DataFrame(data,idx,col)
print(df)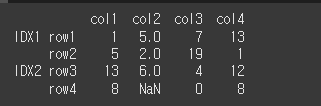
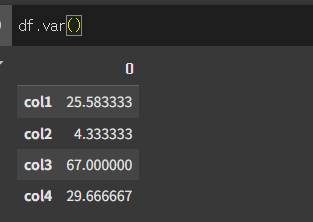
기본적인 사용법
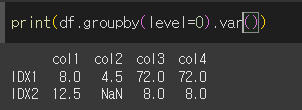
인수입력 없이 var메서드를 사용할 경우 각 열의 요소들의 불편향분산을 계산합니다.
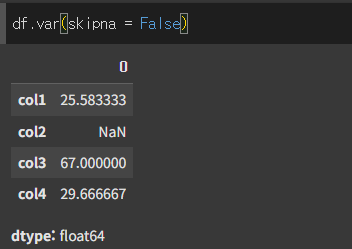
skipna인수의 사용
skipna=False인 경우 결측값이 포함된 경우 NaN을 출력합니다.
axis인수의 사용
axis 인수를 통해 계산의 대상이 될 축을 지정할 수 있습니다.
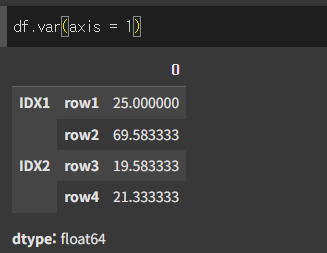
level인수의 사용
Multi Index의 경우 level 인수를 이용해 레벨을 지정할 수 있습니다.
누적 최대/최소 (cummax / cummin)
cummax / cummin메서드는 행/열의 누적 최대값/최소값을 구하는 메서드입니다.
위에서부터 아래로 한줄씩 검사하여 해당 행/열 까지의 값중 최대/최소값을 반환합니다.
사용법
df.cummax(axis=None, skipna=True, args, kwargs)
df.cummin(axis=None, skipna=True, args, kwargs)
axis: 누적 최대/최소값을 구할 축을 지정합니다.
skipna: 결측치를 무시할지 여부 입니다
먼저 기본적인 사용법 예시를 위해 6x2짜리 객체를 생성하겠습니다.
[N,T,F]=[np.nan,True,False]
df = pd.DataFrame({'col1':[1,-2,5,3,0,7],'col2':[3,4,N,9,2,5]})
print(df)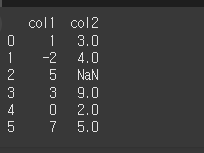
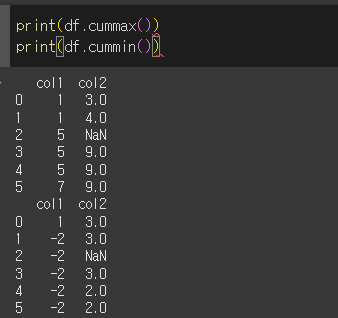
기본적인 사용법
cummax / cummin을 사용할 경우 해당 행/열 까지의 값중 최대/최소값을 반환합니다.
skipna 인수의 사용
skipna=False일 경우 결측값이 발생하면 최대/최소값을 결측값으로 반환하게됩니다.
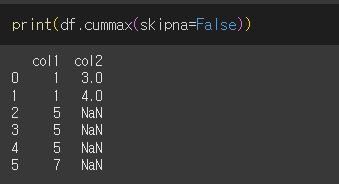
누적합/누적곱 (cumsum / cumprod)
cumsum / cumprod메서드는 행/열의 누적합/누적곱을 구하는 메서드입니다.
위에서부터 아래로 한줄씩 덧셈/곱셈을 누적하여 수행합니다.
사용법
df.cumsum(axis=None, skipna=True, args, kwargs)
df.cumprod(axis=None, skipna=True, args, kwargs)
axis: 누적합/누적곱을 구할 축을 지정합니다.
skipna: 결측치를 무시할지 여부 입니다
먼저 기본적인 사용법 예시를 위해 6x2짜리 객체를 생성하겠습니다.
[N,T,F]=[np.NaN,True,False]
df = pd.DataFrame({'col1':[1,-2,5,3,-1,7],'col2':[3,4,N,9,2,5]})
print(df)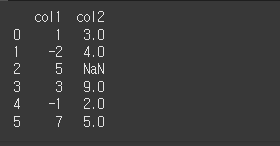
기본적인 사용법
cumsum / cumprod을 사용할 경우 해당 행/열 까지의 누적합/누적곱을 반환합니다.
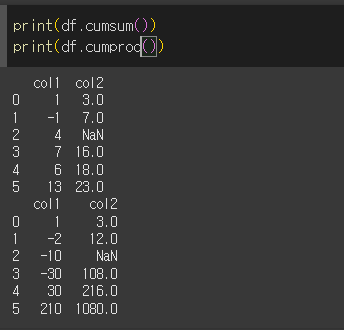
skipna 인수의 사용
skipna=False일 경우 결측값이 발생하면 반환값을 결측값으로 반환하게됩니다.
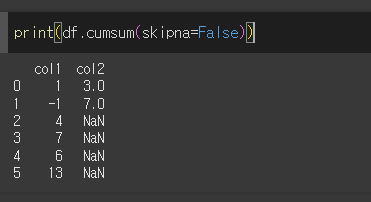
분위수 (quantile)
사용법
df.quantile(q=0.5, axis=0, numeric_only=True, interpolation='linear')
q: 분위수 입니다. 소수로 표현합니다. (예 : 75% = 0.75)
axis: 분위수의 값을 구할 축입니다.
numeric_only: 수(소수)만 대상으로할지 여부입니다. False일 경우 datetime 및 timedelta 데이터의 분위수도 계산됩니다.
interpolation: 분위수에 값이 없을때 보간하는 방법입니다. 방식은 아래와 같습니다.lower : i [분위수 앞, 뒤수 중 작은수] higher : j [분위수 앞, 뒤수 중 큰수] midpoint : (i+j)÷2 [분위수 앞, 뒤수의 중간값] nearest : i or j [분위수 앞, 뒤수중 분위수에 가까운 수]
먼저 기본적인 사용법 예시를 위해 3x3짜리 객체를 생성하겠습니다.
idx = ['row1','row2','row3']
col = ['col1','col2','col3']
data= [[0,1,32],[50,10,-9],[100,100,18]]
df = pd.DataFrame(data,idx,col)
print(df)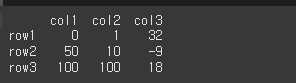
기본적인 사용법
q의 값에 따라 해당 분위수를 출력하게 됩니다.
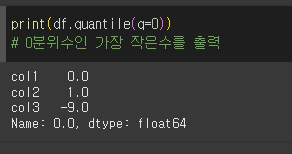
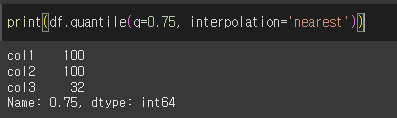
0분위수의 경우
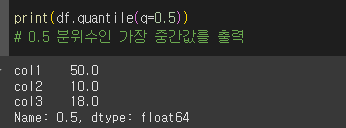
0.5분위수의 경우
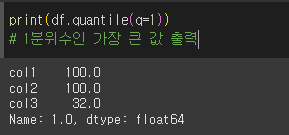
1분위수의 경우
interpolation인수의 사용
interpolation은 분위수의 해당하는 값이 없는 경우 어떤 수를 출력할지 정하는 보간법입니다.
linear의 경우 i + (j - i) x 비율입니다.
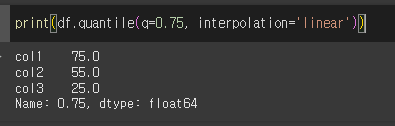
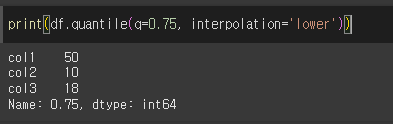
lower의 경우 i [분위수 앞, 뒤수 중 작은수] 입니다.
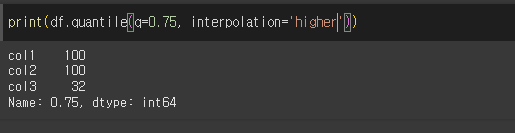
higher의 경우 j [분위수 앞, 뒤수 중 큰수] 입니다.
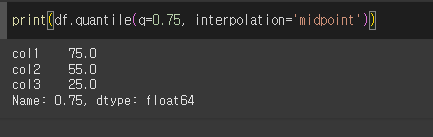
midpoint의 경우 (i+j)÷2 [분위수 앞, 뒤수의 중간값] 입니다.
nearest의 경우 i or j [분위수 앞, 뒤수중 분위수에 가까운 수] 입니다.
평균절대편차 (mad)
mad메서드는 지정한 행/열의 평균절대편차를 구하는 메서드입니다.
평균절대편차는 각 측정값과 평균 사이의 거리의 평균입니다. 값들의 산포도를 의미합니다.
산포도란?
데이터가 평균을 중심으로 얼마나 퍼져 있는지를 나타내는 통계적 지표먼저 기본적인 평균절대편차의 예시를 위해 4x4짜리 Multi Index 객체를 생성하겠습니다.
[N,T,F]=[np.nan,True,False]
idx = [['idx1','idx1','idx2','idx2'],['row1','row2','row3','row4']]
col = ['col1','col2','col3','col4']
data = [[1,-7,13,2],[9,2,-3,8],[8,N,3,0],[-1,12,9,7]]
df = pd.DataFrame(data,idx,col)
print(df)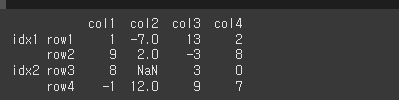
mad 함수가 사라졌기 때문에 mad 함수를 직접 만듭니다.
def mad(DataFrame, axis=0, skipna=True):
mean_values = DataFrame.mean(axis=axis, skipna=skipna)
if axis == 1:
mean_values = mean_values.reindex(DataFrame.index)
result = (DataFrame.sub(mean_values, axis=0)).abs().mean(axis=axis, skipna=skipna)
else:
result = (DataFrame.sub(mean_values, axis=1)).abs().mean(axis=axis, skipna=skipna)
return result기본적인 사용법(+axis)
mad는 각 측정값과 평균 사이의 거리의 평균인 평균절대편차를 구하는 메서드입니다.
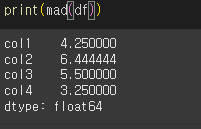
기본적으로 열에 대해서 계산하지만, axis=1을 이용해 행 기준으로 계산 할 수 있습니다.
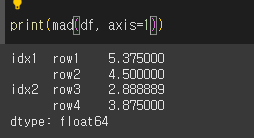
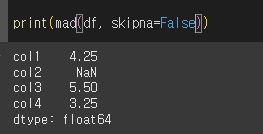
skipna인수의 사용
skipna=False인 경우 계산값에 결측치가 포함되어있으면 NaN을 반환하게됩니다.